

Просто о некоторых способах машинного обучения (ML)
Трудно разобраться в большом количестве материала по теме. Особенно, если задача поставлена на уровне «быстренько разобраться что к чему, найти реализацию и использовать, не вникая в детали, о которых уже позаботились умные бородатые дяди». Задача статьи — систематизировать часто встречающуюся информацию и преподать её языком, понятным IT-шнику сходу. Сделать эдакую шпаргалку.
Машинное обучение — процесс, целью которого является достижение явно не заложенного поведения компьютера.
Виды ML
- Дедуктивное (аналитическое) — выведение фактов и правил из заранее сформулированных и формализованных правил.
- Индуктивное (статистическое) — построение правил на базе эмпирических данных.
Основные задачи ML
- группировка:
- кластеризация — разделение объектов на группы по изначально неизвестным признакам;
- классификация — разделение объектов на группы по заданным признакам;
- регрессионный анализ — нахождение зависимостей между изменяющимися данными:
- линейная регрессия — линейная зависимость некой переменной от другой (других);
- нелинейная регрессия — зависимость выражена нелинейной функцией (степенная, показательная, экспоненциальная и т. п.).
Нейронная сеть
Иногда задача такова, что очень трудно даже чётко сформулировать метод её решения, так как условий и зависимостей слишком много. Как раз в таких случаях часто берут нейросети, заменяя огромный сложный алгоритм на чёрный ящик, который можно настраивать, и эмпирическим путём приходят к приемлемому результату.
Перед тем как данные пойдут в нейросеть, их необходимо формализовать — перевести в понятный нейросети вид. Например, превратить картинку в одномерный массив, где каждый элемент соответствует пикселю и содержит информацию «закрашен/не закрашен». Благодаря абстрагированию от конкретных данных и переводу их в такой вид нейросеть можно обучить работать с самыми разными типами данных: графическими, текстовыми, звуковыми.
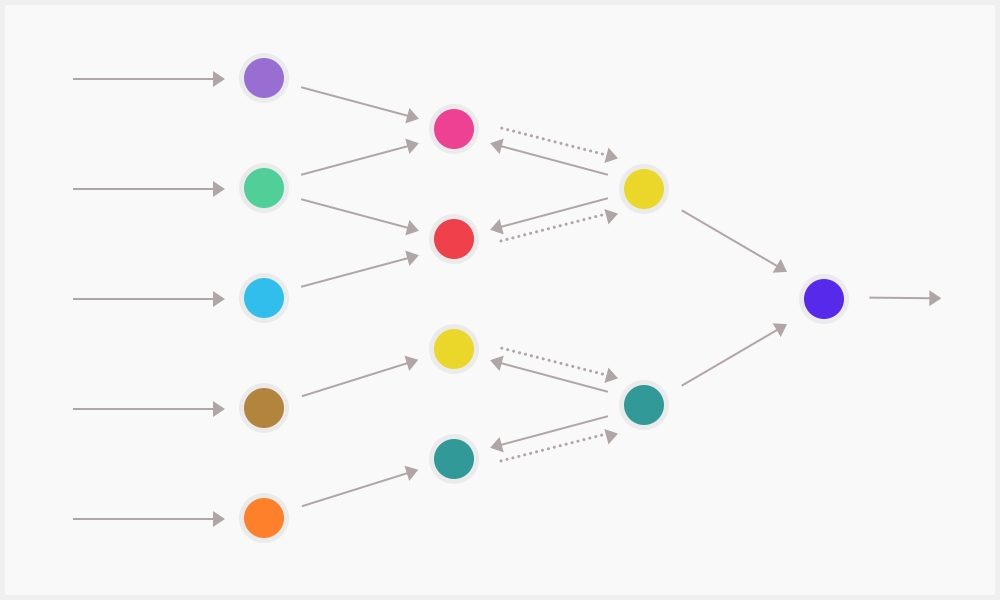
Элементы сети
- Синапс удобно представить как объект, похожий на очередь (канал) и имеющий определённый приоритет. Он нужен для обмена информацией между нейронами.
- Нейрон — объект, который принимает значения из синапса(ов), делает определённые вычисления и отдаёт их результат в синапс(ы) и/или аксон(ы).
- Аксон — объект, похожий на синапс, но отличающийся тем, что в него можно только помещать данные из нейросети, забирает же их кто-то из вне (например, они просто выводятся пользователю).
Как это работает
Нейронная сеть — группа связанных нейронов. Каждый нейрон имеет маленькую долю ответственности — решает какую-то маленькую задачу, вынося вердикт — 1 или 0. Этих задач и, соответственно, нейронов может быть очень много. Из результатов их решения формируется конечный результат. Настраивается всё это изменением приоритетов синапсов, в результате чего агрегация промежуточных результатов происходит по-разному, и общий результат, соответственно, получается разный.
Настраивать сети можно несколькими способами:
- обучение с учителем — восстановление зависимости по данным вида «стимул -> реакция»;
- обучение без учителя — обнаружение зависимостей объектов по обучающей выборке;
- обучение с подкреплением — обучение с взаимодействием с некоторой средой;
- генетический алгоритм — случайный подбор и комбинирование параметров по аналогии с механизмом естественного отбора в природе.
Выбор метода зависит от задачи.
Некоторые виды нейросетей
- персептрон;
- однослойный;
- многослойный;
- рекуррентный;
- ассоциативная память;
- спайковые сети;
- сеть радиальных базисных функций;
- когнитрон.
Если нейронные сети не являются необходимыми для решения задачи, их лучше не использовать.
Деревья принятия решений
Дерево принятия решений представляет собой набор правил в иерархической, последовательной структуре, где каждому входному данному соответствует узел, дающий решение. Такие деревья бывают бинарными, что по сути — много вложенных if-ов.
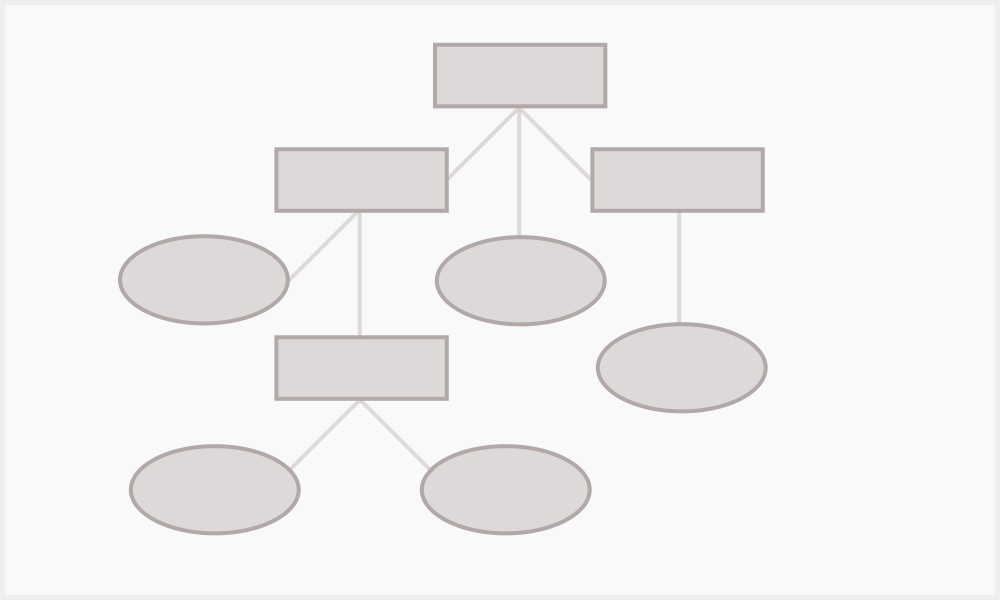
Основная проблема деревьев принятия решений — сложность построения. Для этого существует ряд алгоритмов, например Classification and Regression Tree. Он используется для построения бинарного дерева и C4.5 для построения дерева с неограниченным числом потомков у узлов.
Преимущества:
- быстрое обучение;
- формулирование правил на естественном языке;
- простота и интуитивность классификационной модели;
- высокий уровень и предсказуемость точности прогноза;
- простота тестирования.
Недостатки:
- неоптимальность дерева из-за «жадности» большинства алгоритмов построения деревьев;
- сложность поддержки.
Бустинг (boosting)
Бустинг — это комбинирование недостаточно точных алгоритмов ML, чтобы каждый каким-то образом влиял на результат. Эксперименты показывают, что бустинг позволяет сильно сократить количество ошибок на независимой выборке по мере увеличения количества «плохих» алгоритмов.
Автор: Андрей Резцов, Clojure-разработчик Eastwood
