

Межкадровое (Inter) предсказание в HEVC
Одним из основных этапов обработки цифровых видеоданных в блочных гибридных системах видеокодирования является этап устранения пространственной или временной избыточности. Для каждого текущего кодируемого участка (блока) изображения система кодирования старается найти наиболее похожий блок на ранее закодированных видеоизображениях. Отсчеты найденного блока (пиксели) используются в качестве приближенной оценки (предсказания) значений отсчетов кодируемого блока. «Предсказанные» отсчеты вычитаются из отсчетов кодируемого блока, в результате чего формируется разностный сигнал (Residual). Очевидно, что разностный сигнал содержит информацию только об отличии изображения в кодируемом блоке от изображения в блоке, использованном в качестве предсказания. При «удачном предсказании» количество информации в разностном сигнале оказывается существенно меньше, чем в кодируемом блоке, что во многом и определяет степень сжатия видеоданных при кодировании. Именно информация о разностном сигнале (после некоторой дополнительной обработки) помещается в закодированный поток, т.е. представляет результат кодирования.
Кроме того, в поток помещается информация, позволяющая декодирующей системе выполнить предсказание. Что это за информация? Это, прежде всего, должен быть некоторый идентификатор ранее закодированного видеоизображения (его называют Reference), на котором найден блок, используемый в качестве предсказания. Идентификатор должен быть дополнен информацией о координатах блока-предсказания внутри reference-изображения. Эти координаты обычно задают относительно положения текущего кодируемого блока, то есть в виде смещения кодируемого блока относительно блока-предсказания. Как следствие, совокупность смещений в горизонтальном и вертикальном направлениях называют векторами движения (по сути, они и показывают то, насколько кодируемый блок сдвинулся относительно блока, используемого для предсказания).
Процедура декодирования заключается в том, чтобы по идентификатору найти среди ранее декодированных изображений Reference-изображение. По известным координатам «взять» с этого изображения отсчеты блока-предсказания и добавить к ним значения разностного сигнала из закодированного потока. В результате получится декодированное изображение. Все очень просто! Эта простая идея первоначально была реализована при разработке стандарта H.261 еще в 1988 году. За последующие 25 лет к этой идее было добавлено еще несколько, что позволило существенно снизить как количество информации, требуемое для описания разностного сигнала, так и количество информации, необходимое для идентификации блока на референсном изображении, используемого для предсказания. Кратко рассмотрим эти нововведения.
Нецелочисленные вектора движения
Очевидно, что в реальных видеопоследовательностях смещение изображения в одном кадре относительно изображения в другом (референсном) кадре часто не составляет целое число дискретных отсчетов. В этой ситуации введение нецелочисленных векторов движения позволяет существенно повысить «качество» предсказания. При нецелочисленном смещении для предсказания используются интерполированные (сдвинутые относительно целочисленной позиции) отсчеты референсного блока. Величина и направление сдвига задаются дробными частями горизонтальной и вертикальной составляющих вектора движения.
Двунаправленное предсказание
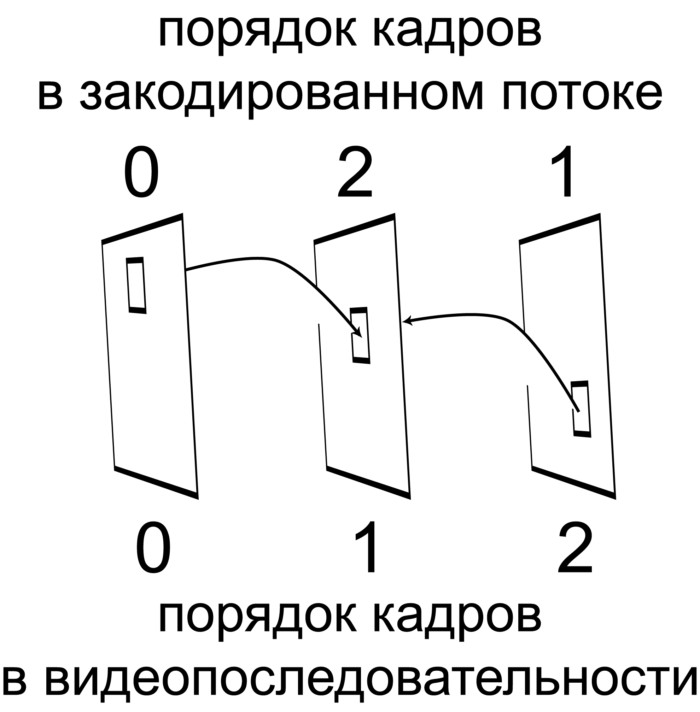
При двунаправленном предсказании кодируемого блока, в качестве референсных используются два блока, каждый из которых может находиться на своем референсном кадре. В качестве предсказания используется полусумма значений отсчетов из одного и другого блока. Наиболее часто один из референсных кадров находится в видеопоследовательности до кадра, содержащего кодируемый блок. Второй референсный кадр находится после текущего кадра. Так как в качестве референсных могут использоваться только уже закодированные кадры, введение двунаправленного предсказания приводит к необходимости кодировать видеокадры не в той последовательности, в которой они находятся в видео (рис. 1). А в чем идея? За счет чего такое двунаправленное предсказание (его называют bi-prediction, блоки, кодируемые с таким предсказанием называют B-блоками, а закодированные кадры, содержащие B-блоки, называют B-кадрами) дает выигрыш в степени сжатия видеоданных, то есть в «качестве» предсказания? Рассмотрим несколько ситуаций, в которых такой выигрыш не вызывает сомнений. Ситуация первая. Пусть нецелочисленные вектора движения в кодирующей системе могут быть заданы с четвертьпиксельной точностью. Один из референсных кадров предшествует кодируемому, а второй находится в видеопоследовательности после него (рис. 1). Кодируемый блок сдвинут относительно референсного блока на первом референсном кадре на −1/6 пикселя по горизонтальной оси. Если при этом относительно второго референсного блока текущий сдвинут на 1/6 пикселя вдоль той же оси, то использование среднего арифметического отсчетов из двух блоков будет эквивалентно линейной интерполяции, обеспечивающей расчет сдвинутых на 1/6 пикселя отсчетов. То есть двунаправленное предсказание в этом случае эквивалентно повышению точности задания векторов движения. Понятно, что приведенный пример несколько идеализирован. Но и в том случае, когда дробные части векторов движения не совпадают по абсолютной величине, использование усреднения отсчетов из двух блоков повышает «качество» предсказания. (Почему в примере взяты смещения с разным знаком? Как раз потому, что один референсный кадр предшествует кодируемому, а другой следует за ним. При непрерывном движении объектов в кадре с большой вероятностью изображение в кодируемом блоке будет сдвинуто относительно одного референсного изображения в одну сторону, а относительно другого — в другую.) Ситуация вторая. Пусть некоторый зафиксированный видеокамерой объект поворачивается с течением времени в плоскости, параллельной плоскости видеокадра. Опять имеем два референсных кадра, один из которых снят раньше кодируемого по времени, а второй позже. Очевидно, что изображение в кодируемом блоке будет повернуто относительно референсных изображений на углы с противоположными знаками. Если эти повороты небольшие, то результат усреднения референсных изображений компенсирует (может быть только частично) поворот кодируемого изображения относительно референсных, что и обеспечит повышение «качества» предсказания. Ситуация третья. Изображение в кодируемом блоке неподвижно относительно и референсного изображения, предшествующего ему, и относительно изображения, находящегося на кадре, снятом по времени позже. Но с течением времени происходит изменение освещенности этого участка видеокадра. Например, изображение темнеет. Очевидно, что и в этом случае использование двунаправленного предсказания позволяет добиться лучшего приближения результата предсказания к кодируемому изображению. В реальных видеопоследовательностях возможны и любые комбинации приведенных выше ситуаций. Кроме того, по-видимому, можно придумать еще не один пример, в которых выигрыш от использования двунаправленного предсказания не вызывает сомнений. Возможность такого выбора также позволяет существенно повысить «качество» предсказания при компенсации движения, адаптируя форму, размер и положение кодируемого блока к форме, размеру и положению движущегося объекта. Пример такой адаптации показан на рис. 2. Далеко не всегда участок изображения, дающий наилучшее предсказание для текущего блока, находится на видеокадре (видеокадрах), расположенном в видеопоследовательности наиболее близко (до или после) к кодируемому видеоизображению. В этой ситуации наилучшего предсказания можно было бы добиться, анализируя на этапе компенсации движения все ранее закодированные кадры. Такой подход, по-видимому, нереализуем на практике, так как требует практически бесконечного объема памяти для хранения декодированных изображений и практически бесконечного времени для поиска на них наилучших референсных блоков. В современных системах видеокодирования как правило используется компромиссный вариант. Для каждого кодируемого видеокадра в таких системах составляется список видеокадров (конечной длины), которые могут использоваться в качестве референсных. Информацию о содержимом списка кодирующая система помещает в закодированный видеопоток. Каждый из блоков, закодированный с использованием Inter-предсказания должен сопровождаться информацией об одном или, в случае двунаправленного предсказания, двух векторах движения. Количество этой информации в ряде случаев оказывается сравнимо или даже превосходит количество информации, необходимой для описания разностного сигнала. Для уменьшения количества информации о векторах движения, содержащейся в закодированном потоке, в современных системах видеокодирования широко используются механизмы предсказания векторов движения. При их использовании декодирующая система по заранее известному алгоритму рассчитывает вектор предсказания — mvp (от англ. Motion Vector Prediction). В закодированный видеопоток же помещается только информация о разностном векторе, определяющем отличие вектора движения от результата его предсказания. Эти разностные векторы называют mvd (от англ. Motion Vector Difference). Олег Пономарев — специалист в области распространения радиоволн, статистической радиофизики, доцент кафедры радиофизики НИ ТГУ, кандидат физико-математических наук. 16 лет занимается вопросами видео кодирования и цифровой обработки сигналов. Руководитель исследовательской лаборатории Elecard.
Адаптивный выбор формы, размера и положения блоков изображения при выполнении предсказания

Списки кадров, которые могут использоваться как источники референсных блоков при компенсации движения
Предсказание векторов движения
Об авторе