

CABAC: что скрывается за этими пятью буквами, часть 5
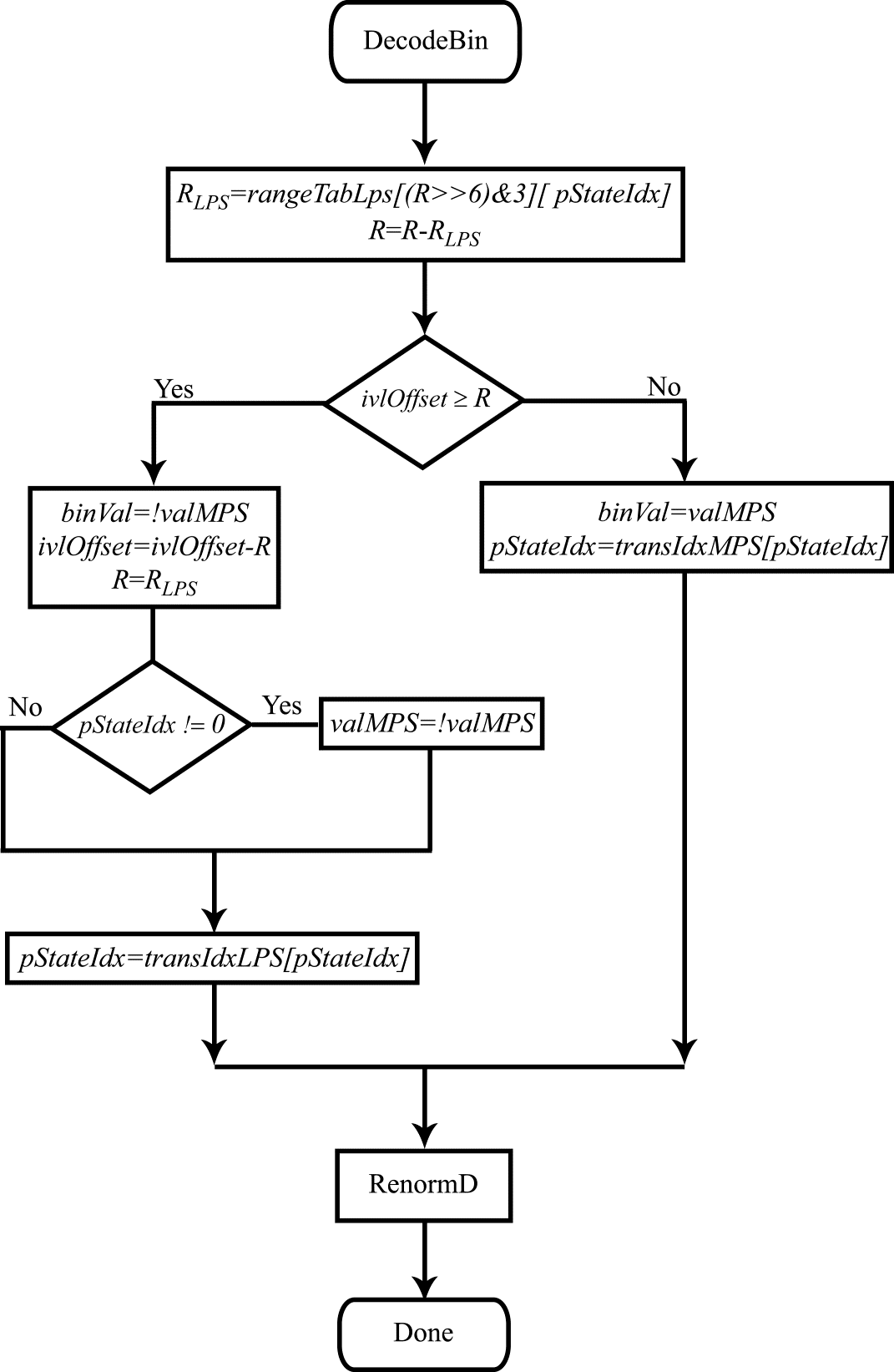
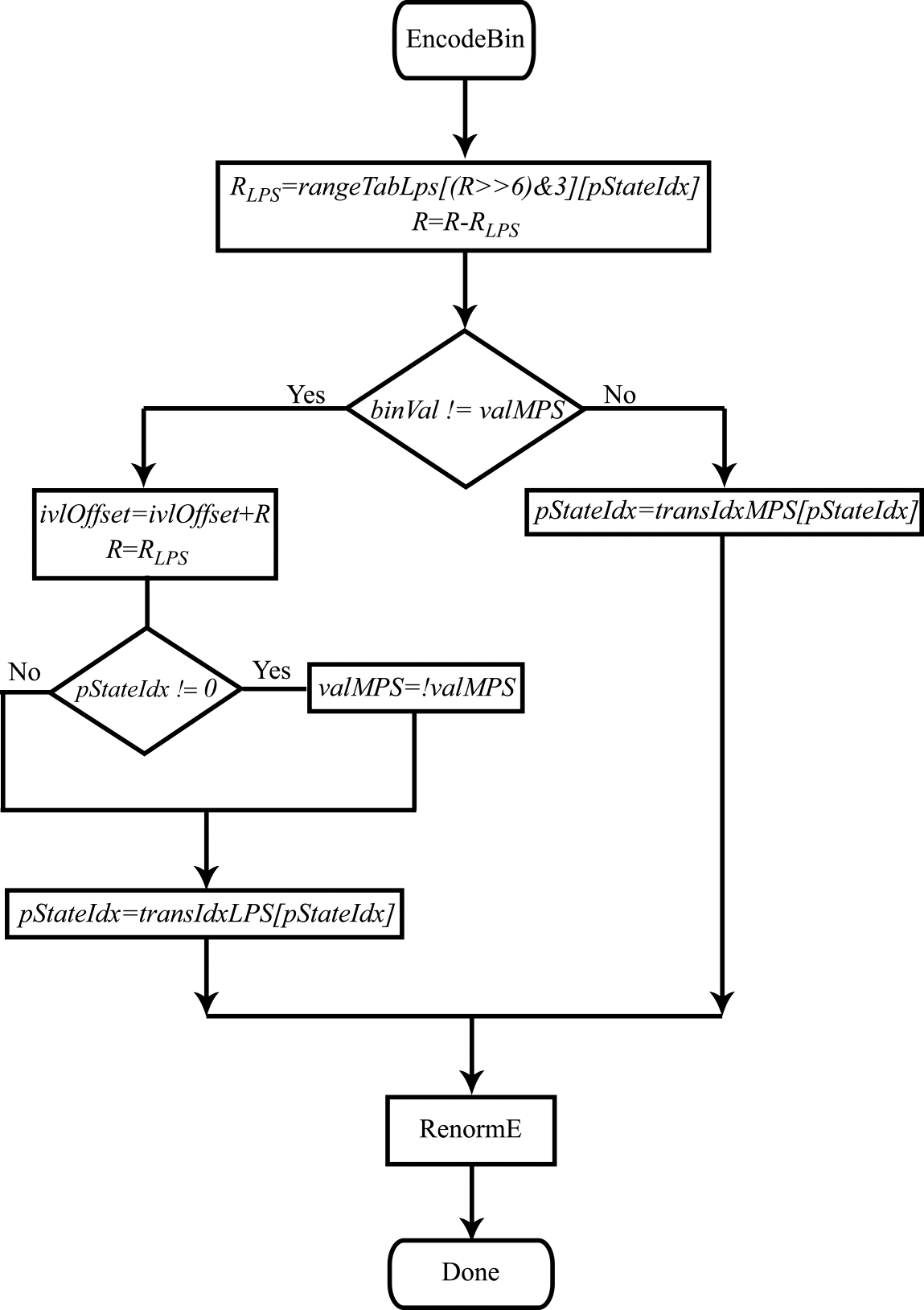
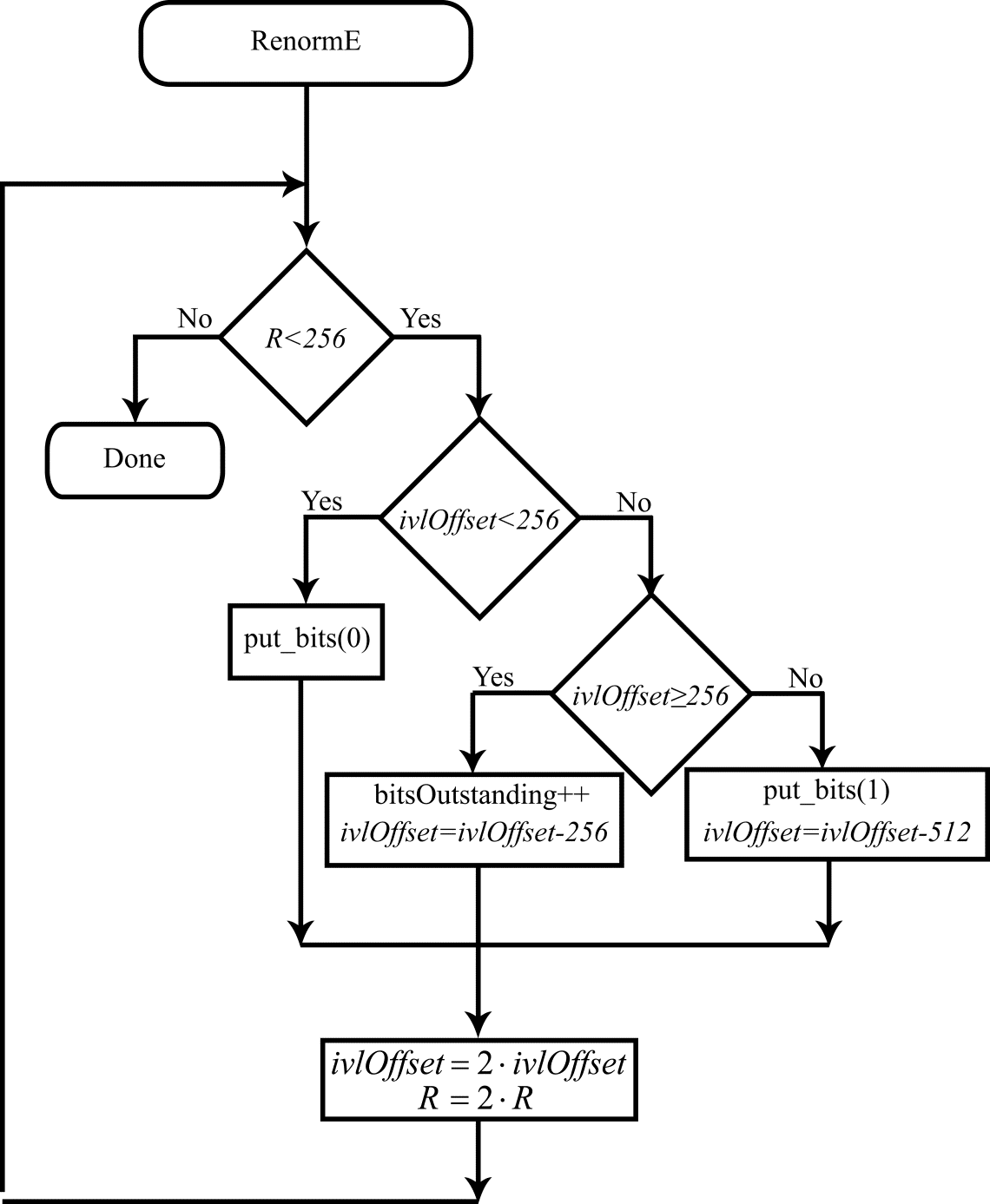
Ознакомьтесь с предыдущими главами: часть 1, часть 2, часть 3, часть 4. где а valMPS — значение наиболее вероятного символа (0 или 1). Как уже было сказано, PLPS принимает 64 возможных значения, индексируемых в CABAC 6-разрядной переменной pStateIdx. Обновление вероятности сводится к обновлению индекса pStateIdx и выполняется выборкой из заранее просчитанных таблиц (в стандарте Table 9-41 — State transition table). В том случае, когда pStateIdx принимает значение 0 происходит смена значения valMPS на противоположное. Значение переменной pStateIdx также используется в качестве второго индекса при выборке значений из таблицы rangeTabLps, т. е. при определении результата произведения RLPS=R⋅PLPS. Блок-схема модифицированного под целочисленную арифметику алгоритма декодирования представлена на рис. 1. На рис. 2 представлена блок-схема процедуры ренормализации при декодировании. Блок-схемы алгоритмов кодирования и ренормализации при кодировании представлены на рис. 3 и 4. Разберемся, наконец, со словосочетанием Context Adaptive в названии процедуры кодирования CABAC. Здесь все также достаточно просто. Значения всех бинов, подвергающихся арифметическому кодированию, получаются в результате бинаризации значений различных синтаксических элементов. Алгоритмы бинаризации различны для разных элементов. Как следствие, бины, представляющие значения различных синтаксических элементов имеют разные вероятности нулевого и единичного значений. Более того, вероятность PLPS, как правило, зависит от порядкового номера бина в бинаризованном представлении значения синтаксического элемента. Эта вероятность, так же как и значение valMPS, может меняться в зависимости от значений этого синтаксического элемента в соседних блоках видеокадра. В такой ситуации представляется разумным вести оценку вероятности PLPS и значения valMPS по отдельности для каждой группы бинов, имеющих примерно одинаковую статистику. Именно так и сделано в процедуре кодирования/декодирования CABAC. Как уже было сказано, дискретные значения вероятности PLPS в CABAC определяются семиразрядным индексом pStateIdx. Вместе с одноразрядным значением valMPS этот индекс полностью определяет статистику бинов. Обновление значений pStateIdx и valMPS производится для отдельных групп однотипных бинов. Для всех таких бинов эти два значения (объединенные в одно 8-ми разрядное число) хранятся в специальной таблице ctxTable. Элементы этой таблицы названы в стандарте контекстом. Процедура моделирования контекста (эта процедура является составной частью алгоритмов кодирования/декодирования CABAC) заключается в определении индекса ctxIdx, для получения из этой таблицы значений pStateIdx и valMPS. Значение ctxIdx как раз и определяется по типу синтаксического элемента, бинаризованному представлению которого принадлежит текущий бин, номеру текущего бина в этом бинаризованном представлении и, возможно, по значениям этого синтаксического элемента в соседних блоках кодируемого видеокадра. Контекст, таким образом, адаптивно выбирается в зависимости от того, к какой группе статистически однородных бинов принадлежит текущий бин. По завершении процедур кодирования/декодирования, в которых происходит обновление pStateIdx и valMPS, обновленные значения сохраняются в таблице ctxTable по соответствующему адресу ctxIdx.На этом мы закончим с рассмотрением алгоритмов кодирования/ декодирования CABAC. За рамками рассмотрения осталось достаточно много моментов, разбору которых можно посвятить еще не одну публикацию. С другой стороны, нам удалось разобраться с основными идеями, заложенными в реализацию CABAC, пройти путь от простого примера арифметического кодирования до блок-схем, описывающих алгоритмы кодирования/декодирования в стандарте HEVC. Олег Пономарев — специалист в области распространения радиоволн, статистической радиофизики, доцент кафедры радиофизики НИ ТГУ, кандидат физико-математических наук. 16 лет занимается вопросами видео кодирования и цифровой обработки сигналов. Руководитель исследовательской лаборатории Elecard.
Итак, мы коротко разобрали алгоритмы арифметического кодирования и декодирования, обсудили процедуры преобразования значений синтаксических элементов, описывающих содержимое видеокадра в закодированном потоке, в двоичный поток бинов, который и подвергается собственно двоичному арифметическому кодированию. За рамками обсуждения остался еще ряд важных вопросов. Во-первых, до сих пор в рассмотренных алгоритмах кодирование и декодирование производится путем деления текущего отрезка на части. Длина отрезка всегда меньше 1. Таким образом, для выполнения вычислений необходимо использование нецелочисленной арифметики. Во-вторых, для кодирования и декодирования необходима информация о вероятностях появления кодируемых символов (вероятность появления в кодируемом потоке наименее вероятного символа PLPS и его значение). Откуда кодер и декодер берут эту информацию? Наконец, в-третьих, мы так и не обсудили, что же означает словосочетание Context Adaptive, содержащееся в названии CABAC. Давайте разберемся с этими оставшимися вопросами.
Использование целочисленной арифметики при кодировании
Возможность использования целочисленной арифметики при кодировании, на первый взгляд, очевидна. Нужно только растянуть исходный интервал [0,1) в целое число раз (например в 512 раз), представить вероятность PLPS целочисленным делителем, а результат деления округлить и можно все процедуры деления отрезка выполнять приближенно, используя целочисленную арифметику с заданной разрядностью чисел. Остается открытым только вопрос о том, к какой потере эффективности кодирования (т.е. потере степени сжатия) приведет приближенность вычислений. Еще в начале 90-х годов прошлого столетия по этому поводу был доказан и опубликован ряд теорем (например, в работе P. G. Howard, J. S. Vitter Analysis of Arithmetic Coding for Data Compression, Information Processing and Management 28 (1992), 749 — 763), позволивших оценить потери в степени сжатия. Эти потери, вызванные приближенным характером вычислений, оказались минимальными. Таким образом, была доказана возможность эффективной реализации алгоритмов двоичного арифметического кодирования на основе целочисленной арифметики.Разработчики CABAC пошли еще дальше в этом направлении. Они предложили настолько загрубить значения величины R текущего интервала и вероятности PLPS, чтобы можно было заранее вычислить все возможные результаты произведения RLPS=R⋅PLPS. В результате, в предложенном алгоритме CABAC вычислительно затратная процедура умножения заменена на выборку заранее рассчитанных результатов умножения из таблицы (в стандарте Table 9-40 — Specification of rangeTabLps depending on the values of pStateIdx and qRangeIdx). Рассмотрим этот момент более детально.Для представления длины R текущего интервала в CABAC отведена 9-ти разрядная переменная ivlCurrRange. При инициализации процесса кодирования/декодирования она инициализируется значением 510. Значения этой переменной после выполнения кодирования/декодирования каждого бина и выполнения процедуры ренормализации всегда лежат в диапазоне от 257 до 511. Перед выполнением процедуры умножения RLPS=R⋅PLPS значение R квантуется, т. е. делится на 64 (квантование выполняется сдвигом вправо на 6 разрядов). Так как 8-й разряд этой переменной (при нумерации разрядов с 0 по 8) всегда равен 1, то четыре возможных квантованных значения величины R представляют разряды 6 и 7 переменной ivlCurrRange. Именно значение (ivlCurrRange≫6)&3 используется в качестве одного из адресов при выборке заранее рассчитанных значений результатов умножения из двумерной таблицы rangeTabLps. Второй индекс лежит в диапазоне от 0 до 63 и представляет 64 возможных значения PLPS. И здесь мы подходим к ответу на второй вопрос. Как происходит подсчет вероятности PLPS при кодировании/декодировании?Значение вероятности PLPS обновляется рекурсивно при получении каждого нового значения binVal кодируемого/декодируемого бина. На k-ом шаге (т.е. при кодировании/декодировании k-ого бина) новое значение вычисляется следующим образом:
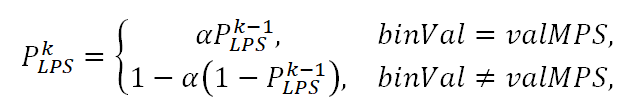


Значение словосочетания Context Adaptive
Об авторе