

ТИГР на страже производительности - часть 1
Введение
В этом цикле публикаций, состоящих из нескольких частей, мы расскажем вам о том, как искали, изучали и внедряли в нашей компании ITA Labs решение, помогающее теперь нам всегда быть в курсе текущей ситуации по производительности наших продуктов.
От части к части, шаг за шагом, от теории к практике – покажем, с какими проблемами сталкивались и как их решили.
Ознакомившись в итоге со всеми частями публикации, вы поймете: зачем это вообще надо, почему выбран именно такой способ и, изучив это решение на практическом примере, без особого труда сможете внедрить его для своих продуктов.
Часть 1. Как мы вышли на след этого чудо-зверя
Какие виды тестирования производительности существуютДля начала, давайте вспомним про существующие виды тестирования производительности:
- Нагрузочное тестирование – основной вид, используется для измерения различных параметров сервера при подаче нагрузки от нагрузочного инструмента, имитирующего работу клиентов.
- Стрессовое тестирование – в этом виде требуется нагрузить систему по максимуму ресурсов, а затем снять нагрузку и наблюдать – сможет ли восстановиться эта система.
- Тестирование на большом количестве данных – либо заранее, либо в процессе тестов требуется сгенерировать настолько много данных, насколько хватит ресурсов, а затем снимать метрики. В какой-то степени - подвид предыдущих тестов, но обычно их разделяют.
- Тестирование стабильности – самое долгое, ставит перед собой цель – выявить различные утечки ресурсов и деградацию производительности при средних нагрузках, но за большее количество времени.
- Тесты на масштабируемость – нужны, чтобы понять, будет ли увеличиваться производительность с увеличением количества ресурсов, и если будет, то насколько пропорционально.
- Конфигурационное тестирование – проверка работы продукта на различных конфигурациях оборудования, стендов и т.п.
Наглядное представление всех вышеперечисленных видов показано на рисунке:

Рисунок 1.
В этой статье будет затронут только 1-й вид (нагрузочный), но в равной мере материал публикации и описанные методики можно будет применить и для других видов тестирования.
Для нагрузочных тестов можно еще утонить два типа, по методу проведения:
- Вручную – обычно долго, иногда дорого, но зато получаются более-менее абсолютные цифры нагрузочных метрик.
- Автоматические – ставят перед собой цель выявить динамику изменения выбранных метрик после каких-либо модификаций в логике продукта, т.е. здесь требуется только сравнивать текущие цифры с цифрами тестирования предыдущих сборок продукта.
Зачем нужно тестировать производительность
В нашей компании мы придерживаемся такой формулировки:
«Тестировать производительность нужно, чтобы понять, насколько тот или иной продукт соответствует ожиданиям (как заказчиков, так и нашим) и выявлять возможные проблемы, с этим связанные».
Тестирование производительности часто еще затрагивает возможные проблемы не только в коде продукта, но и в конфигурации ПО, аппаратного обеспечения и многие другие.
Зачем это нужно нам
Прежде всего, надо определиться, из каких компонентов состоят исходные данные для постановки задачи:
- Есть клиент-серверный продукт (далее - просто «продукт»), и нужно протестировать как серверная часть справляется с нагрузкой клиентов.
- Есть заказчики этого продукта, которые задают резонный вопрос: «Сколько клиентов (пользователей) он сможет одновременно обслуживать в рамках одного узла отказоустойчивого кластера? Нам нужен понятный и желательно какой-то стандартизированный отчет о тестах производительности - HP LoadRunner, например…».
- Есть задача внутри компании – периодически тестировать наши компоненты на предмет того, нет ли деградации производительности в связи с реализацией той или иной фичи. Либо наоборот – насколько она увеличилась после той или иной оптимизации. Обычно, подобные тесты занимают немало времени тестировщиков, отчеты выглядят сложно и некрасиво, а значит и непонятно для заказчиков. И, отказаться совсем от таких тестов тоже нельзя, т.к. в их рамках можно получить абсолютные цифры (т.е. подать максимальную нагрузку на мощных стендах) и уже показать их заказчикам.
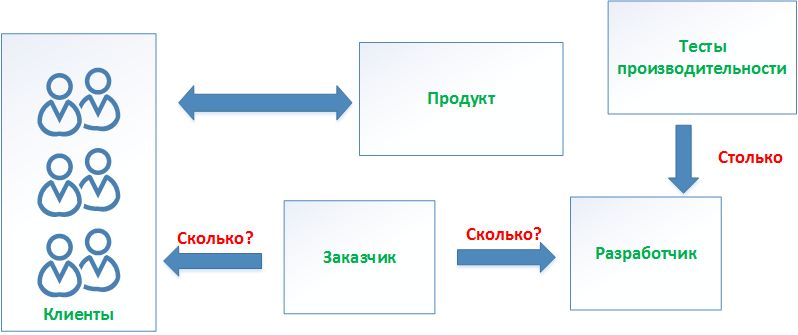
Рисунок 2.
Далее, имеем давно назревшую проблему: как бы нам сделать так, чтобы и тестировщиков не занимать надолго, и картину производительности компонентов видеть почаще. Понятно, что абсолютных цифр при такой постановке задачи – не получить. Поэтому, мы начали искать компромисс.
Формулируем исходную задачу
И компромисс нашелся. Рассуждали так: раз мы не можем регулярно получать актуальные и абсолютные цифры производительности, давайте возьмем какую-то сборку нашего продукта за эталон (точку отсчета), для которой мы знаем эти абсолютные цифры, а далее будем просто сравнивать с ней все последующие сборки.
Т.е., в итоге, будем наблюдать за динамикой изменения производительности продуктапо выбранным метрикам - сравнивать цифры, неважно какой они абсолютной величины. И она (динамика) нам сразу покажет – после какой сборки и какие метрики отклоняются за допустимые рамки. Причем как в сторону уменьшения производительности, так и в сторону увеличения (когда, например, оптимизировали код).
А использовать для этого мы будем регулярные автоматические прогоны тестов производительности после каждой сборки, и видеть графики, примерно такого вида:
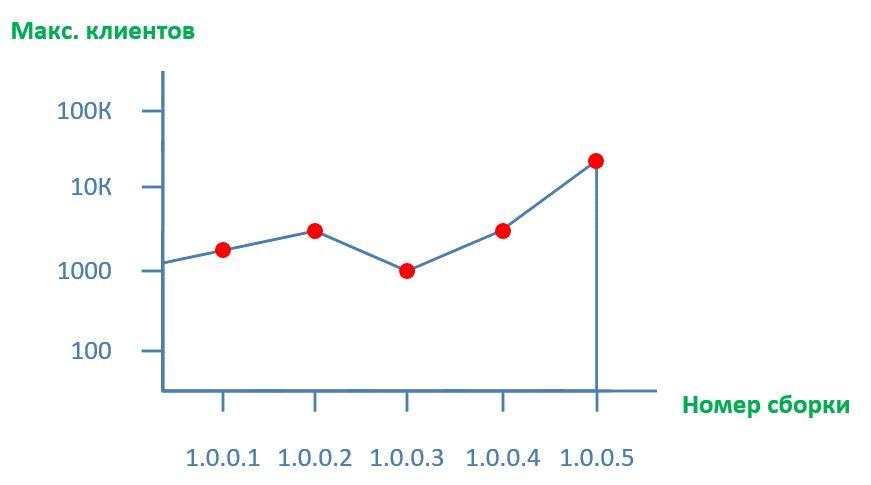 Рисунок 3.
Рисунок 3.
Сам график представляет какую-то из метрик, либо ее производную.
По горизонтали – номер сборки (билда) продукта, а по вертикали – индекс производительности, в нашем примере – какое макс. количество клиентов поддерживает один экземпляр серверной части продукта.
Уточняем исходную задачу
Вы наверняка уже обратили внимание, что в постановке задачи не хватает одной вещи – автоматизации анализа и оповещений. Т.е. графики-то мы увидим, но смотреть их «вручную» для каждой сборки неудобно.
Поэтому, отображение графиков - пусть будет задачей минимум, а задачу максимум надо уточнить:
- Автоматически, после каждой сборки продукта, запускать тестирование производительности на небольшой период, по заранее определенным сценариям.
- Наглядным способом, по заранее определенным метрикам, отображать изменение показателей производительности компонентов.
- Автоматически анализировать и выдавать предупреждения с подробностями, если появилась деградация или наоборот – резкое увеличение производительности.
Чтобы в конечном итоге: либо оперативно исправить проблему в коде, ТЗ (тех. задание), где-то еще, либо зафиксировать оптимальное на текущий момент решение.
Наш график теперь будет выглядеть так:
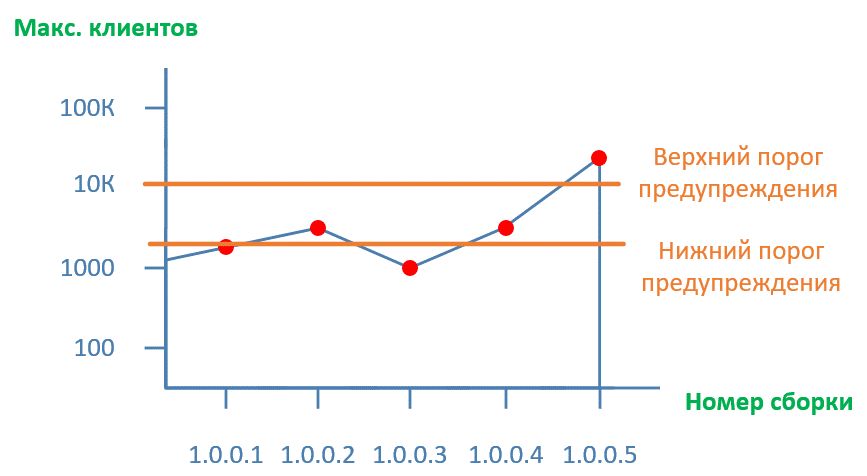
Рисунок 4.
Добавились пороги предупреждений – все значения за пределами нижнего и верхнего пороговбудут сигнализировать о том, что у нас резкое изменение в определенной метрике производительности.
Звучит заманчиво, но что на практике?
Почему не подошел HP LoadRunner
Мы сначала всерьез взялись за HP LoadRunner, т.к. его отчеты считаются стандартом де-факто при тестировании серьезных продуктов серьезными компаниями.
Развернули HP LoadRunner, настроили базовую функциональность, сделали по инструкции из документации несколько прогонов нагрузки тестового сайта, пару отчетов – все заработало, начало неплохое.
Затем, приступили к основной цели – эмуляции нагрузочного клиента. Наши компоненты написаны с использованием .NET, и есть в HP LoadRunner так называемый «.NET Vuser», который, как нам представлялось, смог бы «притвориться» реальным клиентом, если его сначала предварительно подготовить для этого, т.е. записать скрипт его работы.
Во время записи такого скрипта выяснилось, что наш клиент-серверный протокол обмена, а точнее – момент аутентификации клиента, не могут быть эмулированы через «.NET Vuser». Дело усугубилось еще тем, что для этого компонента нет подробной документации у самой компании НР.
Когда мы окончательно поняли, что HP LoadRunner не может нам помочь, было решено посмотреть, что еще есть из решений для тестирования производительности, и что используют другие компании. Подробнее о муках выбора расскажем чуть позже, но было выбрано самое простое, и в тоже время – гибкое, надежное и проверенное другими тестировщиками решение (точнее, основа для решения, т.к. особенности наших продуктов и инфраструктура наложили определенные сложности, которые пришлось решать).
Какие есть инструменты для тестирования производительности
Теперь про обещанные муки выбора инструментов и решений.
HP LoadRunner – это было первое, что мы попробовали из крупных профессиональных отраслевых решений, к тому же продукт де-факто стандарт – многие заказчики его знают и доверяют. Что можно сказать: надежно, сложно, дорого.
Продукт интересный, и возможно у нас будет отдельная статья по нему в будущем.
JMeter – если HP LoadRunner можно сравнить с Windows в мире ОС, то JMeter в данном случае – Linux: мощный, бесплатный, гибкий, но часто требует различных доработок (как в самом JMeter, так и в тестируемых продуктах).
В последнее время сильно догоняет HP LoadRunner по функциональности, но и проблема в JMeter для нас та же – невозможность эмуляции нашего клиента из-за специфики работы клиент-серверного протокола. Для JMeter существует поддержка разработки собственных плагинов, но в нашем случае – показалась сложной сама реализация такого плагина.
Несмотря на это - продукт тоже интересный и тоже заслуживает отдельной статьи.
Gatling – серьезный конкурент JMeter, но без GUI. Однако, считается одним из самых мощных, к тому же, его язык описания тестов – один из стандартизованных. При прочих равных с JMeter имеет более производительный модуль работы с сокетами.
Если у нас будет статья по JMeter, то в ней обязательно будет сравнение с Gatling. Но, в рамках этой статьи и для целей нагрузочного тестирования нашего продукта он не подходит по тем же причинам, что и два предыдущих решения.
Taurus, Яндекс.Танк и другие похожие решения – исключительно для тестирования web-сайтов (а наши компоненты – это не совсем сайты, точнее - совсем не сайты). Но, в своей нише эти решения имеют заслуженно хорошую репутацию. Яндекс использует «Танк» в т.ч. и для своих сайтов – согласитесь, уже неплохая реклама. Очень жаль, что нам пока так и не удалось «пристроить» эти решения в своих продуктах.

Рисунок 5.
Далее, мы начали смотреть в сторону решений, о которых мы узнали от разработчиков и тестировщиков на различных форумах, конференциях, и просто в отдельных публикациях.
InfluxData или TICK Stack (Telegraf, InfluxDB, Chronograf и Kapacitor) – изначально не был предназначен для измерения производительности, но многие быстро поняли его преимущество, и разворачивают его в том числе и для этого. Изначально задумывался как решения для мониторинга метрик из различных источников.
Отметим, что именно этот TICK-стек решений серьезно повлиял на наш окончательный выбор. К тому же, именно на этом этапе поиска стало понятно, что выбирать решение нужно с наиболее полной поддержкой Windows-счетчиков, т.к. наши продукты очень активно их используют.
Существуют еще различного рода связки из агентов (Carbon, NetData, Node_Exporter, CollectD, Zabbix, Telegraf), баз данных (MySQL, ElasticSearch, Prometheus, InfluxDB) и интерфейсов визуализации (здесь выбор поменьше – Chronograf, Kibana, Graphite и Grafana, которая и сама является надстройка над Graphite). По большей части, их выбор – это уже личные предпочтения каждого, т.к. фактически являются конкурентами друг друга.
Мы пытались также понять, что используют для автоматизированного тестирования в других компаниях-производителях ПО. Однако, почему-то никто сейчас не спешит делиться своим наработками: толи они настолько секретные, толи нечем делиться.
В итоге, изучив и попробовав несколько различных вариантов и сочетаний описанных выше решений, у нас сформировалось определенное предпочтение, которое и привело к окончательному выбору.
Почему мы выбрали TIGr-а и что это за зверь такой
Как уже многие догадались из названия статьи, а также из описания существующих решений, выбрали мы «Тигра», а точнее: Telegraf + InfluxDB + Grafana = TIGr
Рассмотрим коротко отдельные компоненты этого решения:
- Grafana – это автономный веб-сервер, предназначенный для визуализации данных и всевозможных циклических метрик. Своей БД не имеет, но может использовать различные источники данных (есть встроенная поддержка нескольких, расширяется плагинами). Обычно называют просто «дашборд» из-за концепции размещения объектов. Обо всех достоинствах можно сказать просто: красивая, гибкая, простая, http-API, много плагинов и успешная репутация в среде системных администраторов и тестировщиков. В последнее время заметна тенденция применения этого продукта и в других, самых различных областях. Все ее возможности – однозначно тема отдельной статьи, а возможно - и нескольких.
 Рисунок 6.
Рисунок 6. - InfluxDB – это так называемая «time series» база данных, т.е. специализирована для хранения временных рядов и оперирования ими.Она идеально подошла для выбранной нами связки: просто развертывается, легкая и быстрая, без проблем интегрируется с остальным компонентам TIGr-а, широко распространена идокументирована, опять же – есть http-API.Т.е. наш выбор именно этой БД не заставил себя долго ждать.
- Telegraf – это агент сбора всевозможных метрик из системы (в которой он установлен), и в частности, для Windows, реализован как обычный исполняемый файл с отдельным конфигурационным файлом, в котором настраивается вся логика работы этого агента.Простой, легкий, встроенная поддержка множества входных метрик, в т.ч. Windows-счетчики (как мы отметили выше, что для нас это самое главное) и выходных форматов данных, расширяется плагинами, полностью поддерживает InfluxDB в качестве БД при передаче метрик.

Рисунок 7.
Все три компонента написаны на языке Go (Golang). Этот язык разработан в Google, его прочат на замену С(++), специально оптимизирован на многопоточность. Более подробно и про другие его интересные возможности можно почитать на официальном сайте.
И все это есть под Windows, что немаловажно в нашей инфраструктуре, т.к. мы:
- официальные партнеры Microsoft
- работаем в основном на стеке технологий Microsoft
Тем не менее, вы возможно и не встретите упоминания, что кто-то разворачивал всю связку TIGr-a на Windows, кроме разве что агента Telegraf. Все-таки сказывается изначальное ориентирование продукта на Linux.
Все три компонента – с открытым исходным кодом (лицензия MIT для Telegraf и InfluxDB, лицензия Apache для Grafana).
Взглянем на схему работы TIGr-а (представлена переработанная для нашей задачи схема с официального сайта InfluxData):
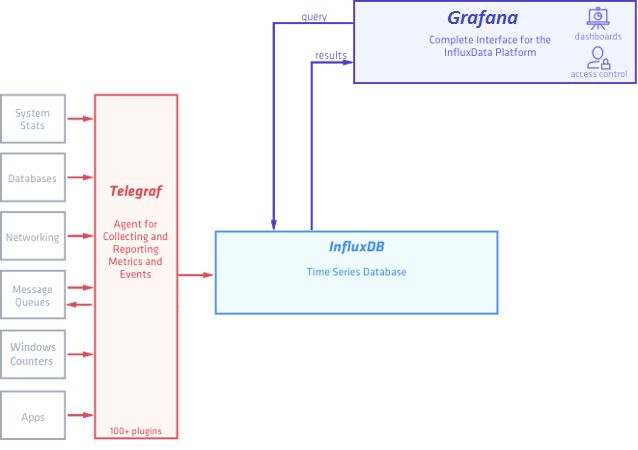
Рисунок 8.
В качестве основного связующего звена выступает InfluxDB, которая получает данные из Telegraf и отдает их Grafana в понятном для всех участников решения формате.
Итоги
В первой части статьи мы разобрали, зачем нам нужно тестировать производительность, зачем нужно тестировать ее автоматически, поставили исходную задачу.
Затем показали поиск решения, и из всего многообразия выбрали конкретную связку Telegraf + InfluxDB + Grafana = TIGr
Во второй части статьи мы более подробно рассмотрим архитектуру компонентов связки («анатомию Тигра»), а также опишем, как их устанавливать и настраиватьв базовой конфигурации («загоним Тигра в клетку»).
Автор статьи: Евгений Климов, Системный инженер, ITA Labs