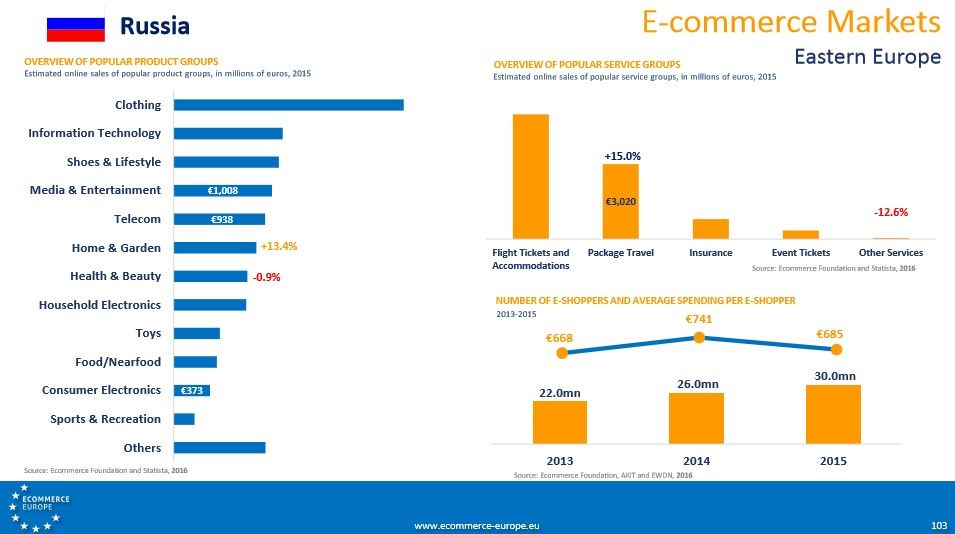
Как мы в России придумали инновацию или новая механика поиска одежды

Если взять мировой рынок одежды, то в основном здесь нет новых маркетинговых механик, а тем более нишевых поисков, все основные игроки типа Shopstyle или Polyvore в основном давят на модную составляющую – подбор луков, must have листы и т.д. Поэтому механика поиска одежды которую мы реализовали в salery.ru абсолютно инновационна во всем мире. Сразу добавлю, что в данный момент поиск осуществляется на основе семантических библиотек, а не запросов пользователей. Потому что вся система еще на этапе тестирования. Позже откроем возможность делать произвольные запросы.
Кто не любит много читать суть нашего поиска описывает видео ниже
Внимание, дальше контент только для людей с минимальными знаниями алгебры!
Сложно придумать новую механику продаж для одежды
На самом деле очень сложно придумать новую маркетинговую механику, так как нет единого стандарта одежды, одну модель одежды не продают годами, есть много размеров и характеристик у каждого бренда. Даже название у одной и той же вещи может быть разное. Это все осложняет агрегацию и категоризацию одежды.
А что касается механик с агрегацией скидок и подбора лучшей цены, то тут максимум чего добились сервисы - это сортировка всех товаров, у которых есть вторая цена, т.е. цена со скидкой.
Существует ли поиск одежды?
Информацию мы ищем в Yandex и Google. Электронику мы сравниваем в прайс агрегаторах – они же являются поиском самой дешевой цены. А вот одежду где искать? Если посмотреть Yandex Market самый крупный агрегатор одежды, то в разделе одежды он недалеко ушел от Shostyle. Максимум там есть фильтры в категориях. Значит по объективным причинам механика поиска одежды не существует в мире.
Проблема поиска одежды
Если взять механику прайс агрегатора, то понятно, что товар определенной модели можно найти и самая релевантная выдача будет основана на низкой цене. К поиску одежды такого применить нельзя. Если искать красное платье, то самое дешевое красное платье не будет релевантное для пользователя по понятным причинам – для описания проблемы при сравнении одежды тут подойдет цитата «а хочу такое же, только с перламутровыми пуговицами». Основная проблема при создании поисковика, как понять какая выдача релевантная для пользователя при выборе одежды.
Кроме того, при поиске самой низкой цены на одежду надо проводить анализ групп в разрезе каждого магазина и бренда. Учитывая именно качество скидки, ведь у товара, который продается со скидкой 2 месяца, вероятность быть релевантным гораздо меньше чем у товара скидка на который появилась вчера. Ну и так же надо брать во внимание историю цены на конкретный товар, ведь манипуляции на «Черную пятницу» подтвердили что скидки, которые появились после подорожания товара не являются релевантными для пользователя, так как люди все-таки умеют думать.
Какие вопросы актуальны для онлайн шопперов при поиске одежды?
Если провести анализ топовых бьюти блогов и дисконт сообществ. Можно сделать вывод что посты с подборкой распродаж в определенной категории или магазины набирают максимальную аудиторию и отклик. А при анализе самых крупных ритейлеров, качество товарной карточки играет огромную роль. Кроме того, у каждого магазина есть свой траст, т.е. товары популярных магазинов с активной рекламой более релевантные. Получается, что релевантность можно выразить следующими вопросами:
Качество:
- Могу ли доверять этому магазину?
- Могу ли понять по фото и описанию товарной карточки что этот товар тот, который мне нужен?
Цена:
- Есть ли еще аналогичные предложения с более приемлемой ценой?
- Есть ли дополнительные акции и промокоды в магазине?
- На сколько скидка на товар честная?
- Когда начинается распродажи в категории товара, который я хочу купить?
- В каком магазине будут самые выгодные цена на мой любимый бренд?
Каждый из вышеприведенных вопросов можно рассчитать алгоритмически. После проведенных месяцев исследований, мы разработали оптимальную формулу ранжирования, которая учитывает все ответы на вышеприведенные вопросы. Это наподобие Google pageRank, формулу которого можно найти в Wikipedia.
Формула оптимального ранжирования одежды
Мы старались учесть максимальное количество критериев при оценке товаров, и ответить на максимальное количество вопросов, которые возникают у пользователей при просмотре товара.
Нам важно, чтобы пользователь мог узнать максимум о товаре из фото, потому изображение должно быть достаточно качественным и не отторгать при просмотре большими белыми полями или водяными знаками. Описание, которое читает пользователь, должно быть информативным и приятным к прочтению, оно не должно быть сухой выжимкой формальных характеристик товара, человеку должно быть приятно прочитать краткую историю про товар, который он, возможно, купит. Чем больше уточняющих характеристик упомянуто, тем полнее будет понимание пользователем особенностей товара: никому не вредно узнать, что воротник рубашки из другого материала, а платье сзади застегивается на невидимую молнию.
Скидки на товар должны быть честными и свежими (если товар не покупают даже после скидок, скорее всего, с ним что-то не так). Помимо прочего, нам важно, чтобы магазин, в котором люди покупают одежду, был им привычен и удобен, потому ритейлеры, которые доказали временем и фактами качество своей работы, имеют более высокую вероятность отображения их товаров вверху нашей ленты.
Расскажу вкратце о том, как мы проектировали алгоритм оценки товара по изображению и приятности слога.
Картинку мы решили разделить на полезные, бесполезные и вредные области. Полезными областями на фото мы считаем ту часть, где зображен сам товар, бесполезными — пустоту, вредными — водяные знаки и шум. Протестировав на реальной базе набор эвристических алгоритмов, мы приняли решение оценивать области в пикселях, максимальную корреляцию визуальных ощущений с результатами вычислений мы получили на такой формуле:
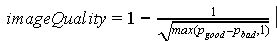
Она достигает единицы на условном идеальном фото, где товар видно чётко, без лишних полей и без водяных знаков вовсе, и стремится к нулю на изображениях посредственного качества. Бесполезные области использовать мы не сумели.
Когда мы оценивали описания, одной из проблем были тексты, которые были содержательными, но безинтересными для пользователя (например, где шло перечисление материалов и процент состава), также мы сочли неправильным, когда магазины приписывали фиксированный текст в некоторых местах описания.
Эту часть алгоритма мы решили закрыть при помощи нашей вариации на тему алгоритма шинглов, только мы рассматривали текст как набор пассажей. В нашей трактовке это произвольная последовательность буквенных символов, не содержащая символов разделителей. Теперь рассмотрим текст как список пассажей, для каждого из которых мы вычислим его рейтинг. Тогда формула этого компонента общей формулы качества товара будет иметь следующий вид:
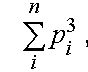
где pi (рейтинг пассажа) вычисляется от длины пассажа (len) по следующему принципу:
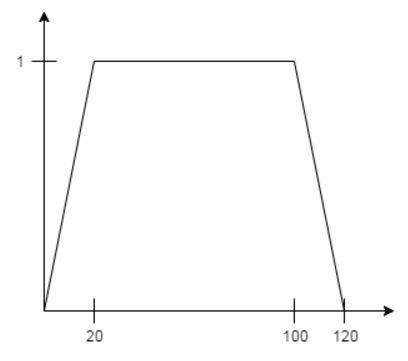
На практике этот алгоритм высоко ранжирует только визуально приятные и синтаксически правильные тексты.
Создали поиск одежды и что дальше?
У нас есть рабочий алгоритм ранжирования товаров. И у нас есть 60-70% всех товарных позиций ру-нета. У нас есть около 200 категорий одежды и более 20000 нормализованных фильтров в мужской, женской и детской одежде. Теперь в любой категории одежды любого пола мы можем найти самые интересные товары, а это очень важно для пользователей. Дальше в планах добавлять новые магазины одежды и обработку пользовательских запросов.
Данный проект был создан на минимальных посевных инвестициях и уже показывает хорошую динамику. Для выхода на рынки других стран мы планируем привлечь дополнительные инвестиции для ускорения процесса локализации и маркетинговых активностей.
Хотите попробовать наш поиск одежды? Добро пожаловать на Salery.