

Как создать единый AI-слой в компании и избежать хаоса при внедрении искусственного интеллекта
Сейчас почти каждая компания уже «внедряет AI», от небольшой кофешки до крупных корпораций. Обычно кто-то в маркетинге собирает себе AI-ассистента, продажи делают своего бота, где-то рядом появляется n8n-сценарий с прямым доступом к модели, разработчики пишут отдельный AI-сервис, а кто-то внутри бизнеса параллельно поднимает локальную RAG-базу под конкретного AI-агента.
На старте это позволяет очень быстро запустить решение, но по факту является началом хауса.
Потому что AI в компании скоро перестанет быть просто экспериментом. Он начинает трогать клиентский сервис, внутренние знания, деньги, доступы, процессы и операционную логику. И если в этот момент у бизнеса нет общих правил, через несколько месяцев он получает зоопарк из ботов, агентов, workflow и полуручных интеграций, которые сложно поддерживать, страшно менять и дорого масштабировать.
Именно поэтому, перед тем, как заниматься внедрением, я начинаю с составления документа, где смотрю на AI, как на отдельный корпоративный слой, для которого нужны свои нормативы: как решения строятся, как они ходят в модели, как работают со знаниями, где место AI, а где место обычной инженерии, и как не плодить пять разных контуров там, где должен быть один.
Ниже описаны принципы, которые я считаю базовыми, если компания хочет полноценно внедрять AI в свои процессы.
Главная ошибка внедрения AI в компании: подход как к набору инициатив, а не к системе
Почти всегда всё начинается одинаково: каждая команда делает что-то полезное для себя.
Маркетинг автоматизирует контент. Саппорт собирает внутреннего помощника. Продажи тестируют AI для обработки лидов. HR хочет своего ассистента. Операционный блок — свой. Вроде бы всё логично. Но в этот момент компания незаметно начинает строить не одну AI-систему, а сразу несколько маленьких, не связанных между собой.
Снаружи это выглядит как активное внедрение AI. Но изнутри это быстрое накопление технического и организационного долга.
У меня здесь очень простой принцип: любой новый AI-проект должен усиливать общий AI-контур компании, а не создавать ещё один изолированный слой.
Пока этого принципа нет, AI растёт как набор кружков по интересам. Когда он появляется, AI начинает становиться инфраструктурой.
Почему без единой архитектуры AI в компании превращается в хаос
Как только AI-инициатив становится больше трёх-пяти, начинают всплывать одинаковые проблемы.
Одна команда ходит в OpenAI напрямую. Другая — в Anthropic. Третья использует no-code связку через внешний сервис. У одной команды документы лежат в Notion и индексируются вручную. У другой — в Google Drive и парсятся по-другому. Где-то точные факты ищут через RAG, где-то наоборот пытаются засунуть большие инструкции в таблицы и потом ждут, что LLM с этим нормально справится.
Проблема не в том, что инструменты разные. Проблема в том, что у компании нет единого каркаса.
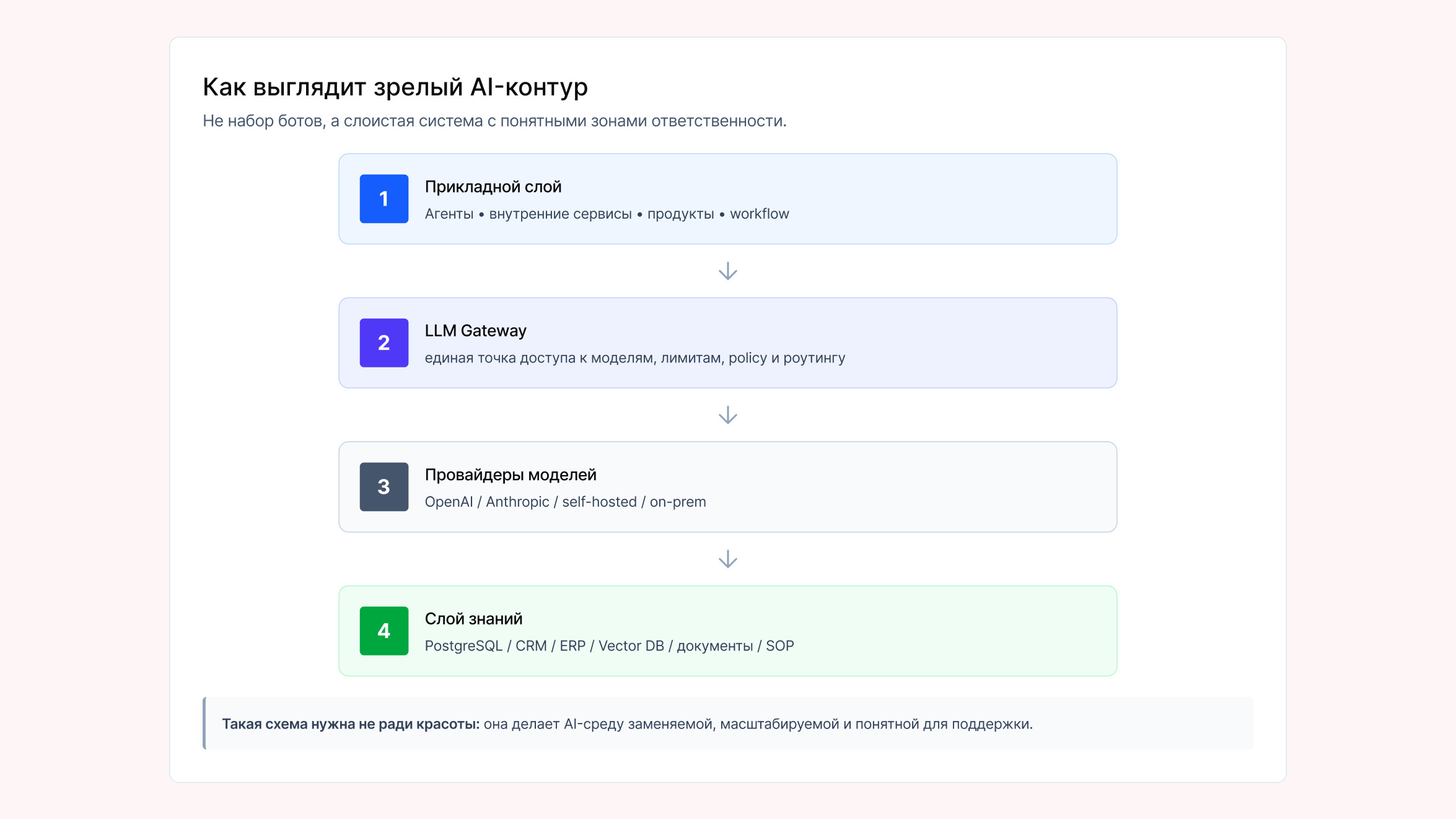
На практике я всё больше убеждаюсь, что AI-решения в компании должны вставать в общую слоистую архитектуру. Сверху — прикладные решения: агенты, workflow, внутренние сервисы, продукты с AI-логикой. Ниже — единый слой доступа к моделям. Ещё ниже — сами model providers: внешние API, self-hosted модели, on-prem deployment. Отдельно — слой знаний, где структурные и семантические данные разделены и используются по назначению. Когда такой каркас есть, новые решения начинают собираться быстрее. Когда его нет, каждое новое AI-решение приносит в компанию ещё один кусок будущего хаоса. Очень многие команды начинают одинаково: просто вставляют ключ к модели туда, где надо быстро получить результат. В n8n. В backend. В скрипт. В бота. В какой-нибудь внутренний сервис. Сначала это правда кажется нормальным. Но как только AI-сценариев становится много, компания резко теряет управляемость. Уже непонятно, кто какие модели использует, где дорогие вызовы, где нет лимитов, где нет fallback-сценариев, какие окружения вообще имеют доступ к дорогим моделям и что произойдёт, если нужно будет быстро поменять провайдера или перераспределить бюджеты. Поэтому для меня один из обязательных принципов выглядит так: все обращения к моделям должны идти через единый gateway-слой. Это единственный способ сделать AI управляемым корпоративным сервисом. Когда у компании появляется единая точка доступа к моделям, она наконец-то начинает видеть реальную картину: usage, latency, расходы, правила доступа, роутинг между моделями, ограничения по окружениям, распределение дешёвых и дорогих моделей между командами и проектами. То есть AI перестаёт быть серой зоной. Он становится управляемой платформенной функцией. Здесь бизнес обычно ошибается особенно быстро. Появляется первый внутренний ассистент и под него собирают свою базу знаний. Потом второй, и под него снова делают отдельную. Потом третий агент. Потом четвёртый. И через какое-то время выясняется, что один и тот же документ живёт в нескольких реализациях, разные команды по-разному его парсят, индексируют и обновляют, а ответы на похожие вопросы начинают отличаться друг от друга. Такой AI-контур невозможно нормально масштабировать. Потому что компания плодит не знания, а локальные интерпретации знаний. Поэтому я почти всегда настаиваю на другой логике: корпоративные знания должны собираться в единый knowledge layer, а не расползаться по отдельным проектам. Причём здесь очень важно не свалить всё в одну кучу. Я предлагаю выбрать единое хранилище данных, у которого есть функции вебхуков или иные способы взаимодействия с другими системами. Это можем быть Notion, Confluence или Google Drive. Сотрудники наполняют документами, и они автоматически отправляются в RAG и Postgre Если системе нужен точный факт, например статус, дата, остаток, ID, сущность, транзакция — это задача для структурного слоя. Обычно это PostgreSQL. Если нужен смысловой поиск по инструкциям, регламентам, SOP, документам, перепискам, комментариям, описаниям процессов — тогда уже нужен RAG и семантический слой. Это принципиально разные типы работы. И как только компания начинает искать точные факты через «семантические догадки» модели, она получает ошибки там, где вообще не должно было быть пространства для интерпретации. С этим сейчас вообще происходит важный сдвиг. Ещё недавно многим казалось, что главное это выбрать «лучшую модель». Но по мере того как сильные модели и AI-инструменты становятся доступными всё большему числу компаний, само наличие LLM перестаёт быть преимуществом. Всё важнее становится то, насколько хорошо компания собрала свой контекст: знания, процессы, доступы, сущности, историю, связи между системами. На этом же делают акцент и в свежих международных публикациях: при более широком доступе к одинаковым моделям дифференциатором становится контекст компании. Именно поэтому вопрос «какую модель выбрать» почти никогда не должен быть первым. Гораздо важнее сначала ответить на другие вопросы: Если этого нет, никакая «лучшая модель» не спасёт. Сейчас многие настолько увлеклись AI, что пытаются отдать модели вообще всё подряд: проверки, маршрутизацию, state logic, критичные действия, правила, фильтрацию, куски бизнес-логики и даже то, что давно и надёжно решается обычной инженерией. Для меня здесь базовый принцип очень простой: AI нужен там, где действительно есть reasoning: интерпретация, классификация, работа с неструктурированным входом, генерация объяснений, анализ контекста, обработка смысловых неоднозначностей. Но если задачу можно надёжно решить через код, deterministic rules, workflow, state machine или явную бизнес-логику, именно это и должно быть основой. Зрелая AI-архитектура — это понятная граница между тем, что делает AI, и тем, что должна делать система без него. Иначе компания очень быстро получает ситуацию, в которой часть операционной логики живёт в промптах, часть в workflow, часть в коде, а объяснить, почему система сработала именно так, становится почти невозможно. Я вообще не вижу смысла в войне между «настоящей разработкой» и no-code orchestration. Проблема обычно не в n8n и не в коде. Проблема в том, строит ли компания управляемую систему или просто быстро собирает времянки. n8n может быть отличным orchestration-слоем. Код тоже. И то и другое может оказаться катастрофой. Вопрос в том, какие правила закладываются: Если ответов на эти вопросы нет, инструмент уже не так важен. Компания всё равно соберёт красивый, но одноразовый AI-контур. Международные материалы про GenAI в компаниях всё чаще повторяют одну и ту же мысль про то, что проблема не в умении запускать пилоты, а в том, что компании не умеют переводить их в систему. Для этого нужны не новые демки, а дисциплина, фокус, operating model и архитектурные принципы. На практике это означает очень неприятную, но важную вещь: сделать первого бота обычно несложно. Сложно сделать так, чтобы через год у компании было не пятнадцать разрозненных инициатив, а единая работающая AI-среда. Именно здесь становится понятно, зачем вообще нужны внутренние нормативы внедрения AI. Ради того, чтобы каждый новый AI-проект не создавал новый изолированный контур, а усиливал уже существующую систему. Для меня у зрелого AI-внедрения есть несколько обязательных признаков. Во-первых, Во-вторых, В-третьих, В-четвёртых, В-пятых, И финальное Как только этого нет, почти любой разговор про «корпоративный AI» начинает быстро скатываться в набор отдельных чат-ботов и автоматизаций, живущих своей жизнью. Мне кажется, в ближайшие годы выиграют не те компании, которые первыми собрали себе больше автоматизаций, а те кто раньше других выстроил правила. Собрали единый gateway, единый knowledge layer, понятную границу между AI и обычной инженерией, общую архитектуру, формальный подход к качеству, стоимости и масштабированию. Потому что именно так, автоматизации соберутся в полноценный AI-слой компании. Сохраните мой контакт — на случай, если захотите применить ИИ или другие IT-решения у себя. Telegram-канал: https://t.me/egormklive
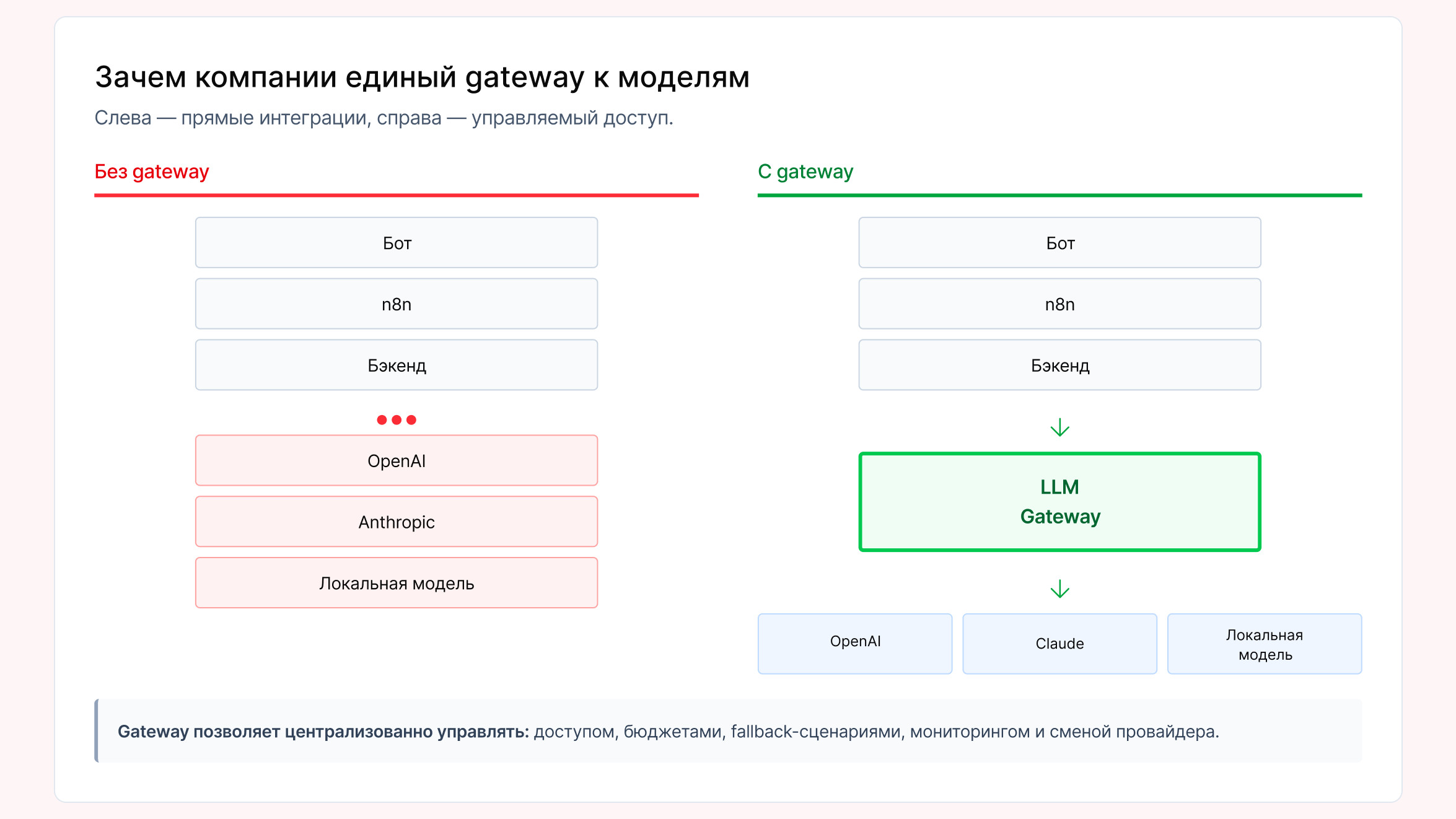
Прямая интеграция с AI-моделями: почему это работает только в начале
Gateway-слой — это единый инфраструктурный слой доступа к AI-моделям, через который все системы компании отправляют запросы в LLM. Он нужен, чтобы централизованно управлять доступом к моделям, лимитами, маршрутами запросов, стоимостью, логированием, fallback-сценариями и заменой провайдеров.
Ошибка № 2: отсутствие единого knowledge layer и рост мини-RAG решений

RAG — это слой семантического поиска по документам и базе знаний: система находит релевантные фрагменты в инструкциях, регламентах и других текстах и подмешивает их в контекст модели, чтобы она отвечала не «из головы», а с опорой на реальные материалы компании.
PostgreSQL — это структурная база данных, где информация хранится в точном и формализованном виде: сущности, статусы, даты, связи, справочники и другие данные, по которым системе нужно не интерпретировать, а получать конкретный факт.
Почему модели AI перестают быть конкурентным преимуществом
Ошибка внедрения AI: когда задачи, решаемые кодом, передают моделям

Код или no-code (n8n): как правильно выбирать инструменты для AI-автоматизации
Почему AI-проекты не масштабируются: проблема перехода от пилота к системе
Минимальный стандарт зрелого внедрения AI в компании
AI в компании рассматривается как единая инфраструктура, а не как набор локальных инициатив разных команд.
все решения строятся по общей архитектуре: прикладной слой, слой доступа к моделям, слой провайдеров, слой знаний.
обращения к моделям не живут внутри прикладной логики напрямую, а идут через единый gateway.
корпоративные знания не размазываются по мини-базам под каждого бота, а собираются в единый knowledge layer с понятным разделением между точными структурными данными и семантическим поиском.
AI используется там, где он реально нужен, а не как замена нормальной инженерии.
Любое серьёзное AI-решение до разработки проходит нормальную формализацию: какую задачу решает, где лежит логика, какие источники данных использует, какие метрики качества считаются приемлемыми, какие реальные сценарии тестируются и за счёт чего вообще должен появиться экономический эффект.Вывод