Виксна Максим
Виксна Максим
Как мы в очередной раз пытаемся заменить людей на роботов
Как появилась идея
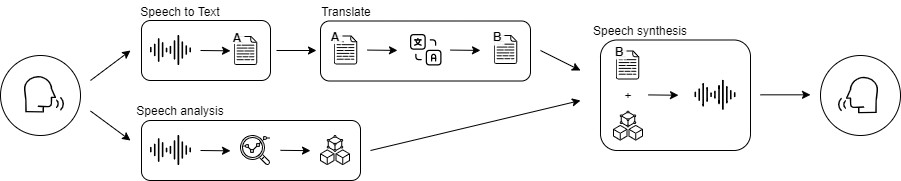
Всё началось с увиденного поста про новую платформу Maxine с ИИ для
апгрейда видеосвязи от Nvidia, одна из особенностей этой платформы является
синхронный перевод в виде титров, данная фича реализована при помощи фреймворка
от той же Nvidia под название Jarvis, данный фреймворк предназначен для
мультимодальных разговорных сервисов искусственного интеллекта, обеспечивающая
производительность графических процессоров в реальном времени. Именно эта
концепция синхронного перевода легла в основу нашей платформы аудио- и видео-
связи. Поскольку это новая платформа, она должна иметь ряд особенностей в
сравнении с другими подобными платформами, поэтому мы решили добавить этим
титрам голос, формируя голосовой профиль пользователя и синтезируя речь с
учётом тональности и окраса голоса человека, который говорит.
Речь в текст или распознавание речи Что лучше использовать Google, Яндекс или Mozilla? Google в сравнении с Яндекс имеет большую точность
распознавания, мы прогнали 5 тестовых голосовых сообщений: 3 на английском
языке и 2 на русском через API Google и точность распознавания составила 100%
(5/5), Яндекс 60% (3/5). Google поддерживает 125 языков, Яндекс — 3 языка. Плюсами Mozilla Deepspeech является точность распознавания, так как она
составляет 92,5%, для сравнения человек распознаёт с точностью до 94,2%,
поэтому точность распознавания тестовых голосовых сообщений составила 100%
(5/5), также плюсом является то, что данный движок опенсурсный, в отличие от Google и
Яндекс. Минусом данного движка является количество распознаваемых
языков — это английский, русский и французский. В итоге выбор пал на Google Speech to Text из-за соотношения количества
языков к точности распознавания. Перевод текста Для решения этой задачи первым приходит на ум использование готового API от
Google или Яндекс. Первая проблема, с которой мы столкнулись, — это неточность
перевода. Например, перевод предложения «Народу в Китае видимо невидимо» с
русского на английский. Яндекс
Переводчик: «People in China are
apparently invisible» и Google Переводчик:
«There are a lot of people in China», в
данном случае Google справился лучше. Панацеи для решения данной проблемы на текущий момент нет. Главная задача
данных переводчиков на сегодняшний день — это научить алгоритм понимать смысл
предложения/текста. Если алгоритм поймёт смысл, то и перевод будет намного
качественным. Перевод ряда предложений, связанных с бизнес тематикой, через Google
Translate и Яндекс Переводчик показал, что Google делает это более грамотно,
поэтому использовать будем Google Translate. Анализ и получение голосового профиля Чтобы получить голосовой профиль нам необходимо
собрать некоторый датасет. Поскольку стоит задача синтезировать переведенный
текст речью говорящего, нам нужно собрать датасет от каждого пользователя. Это
делается посредством прочтения специализированного текста, содержащего
необходимый набор буквосочетаний, синтаксических конструкций и знаков
препинания. Длительность прочтения текста составляет примерно 15 минут, так мы
получим достаточное количество информации о частотных и интонационных
характеристиках каждого пользователя. Прочтение текста можно повторять, чтобы
улучшить итоговые результаты. Синтез речи с учётом голосового профиля Синтезировать речь человека на языке, на котором он никогда не говорил -
задача не из простых. Для этого необходимо собрать первичный датасет с помощью
билингвальных людей, которые также прочитают специализированный текст, затем
зачитают аналогичный текст на другом языке, а после этого — дополнительные
тексты для расширения датасета. На основе этого обучения и выявленных
взаимосвязей впоследствии будет генерироваться речь пользователей на другом
языке. Также в этом процессе помогут уже существующие автоматизированные
решения по синтезу речи на различных языках, так как сбор полностью
самостоятельного датасета необходимого масштаба не представляется ни
эффективным, ни реалистичным. Вывод Основная наша задача на текущий момент — это совмещения голосового профиля
с синтезом речи, так как перенос голосового профиля на другой язык задача сложная и нужно обучить нейронную сеть таким образом, чтобы она поняла, как это
делать, имея всего два датасета на разных языках. В ходе развития проекта мы будет делать публикации, связанные с более
конкретными задачами и путями их решения.