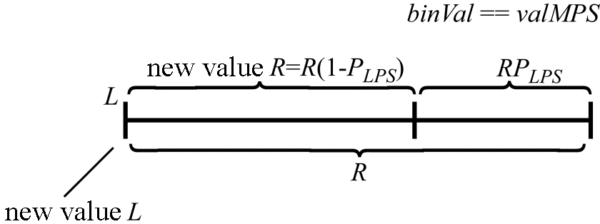CABAC: что скрывается за этими пятью буквами, часть 3
Прежде всего, необходимо отметить, что из алфавита исчезает символ EOF, обозначающий конец сообщения. Информация об окончании сообщения необходима при декодировании. При отсутствии такой информации декодирование будет продолжаться даже после правильного декодирования всего сообщения. Как в HEVC реализуется передача информации о конце сообщения мы рассмотрим позднее. Здесь же отметим только необходимость реализации процедуры такой передачи.
Что еще поменяется в случае кодирования сообщения, состоящего только из двух символов? Массив P, содержащий кумулятивные вероятности символов, будет содержать теперь только три значения: P={0,PMPS,1}. За PMPS здесь обозначена вероятность появления в сообщении более вероятного символа (если мы из нашего 20-ти символьного сообщения {b, a, b, b, b, b, b, b, b, b, a, b, b, b, b, b, b, b, b, EOF} уберем символ EOF, то длина сообщения станет равна 19/19, а вероятность более вероятного символа «b» будет равна 1819). Т. о. текущий отрезок [L,H) теперь при кодировании будет все время делиться на две части. Длина большей части определяется вероятностью PMPS, меньшей — вероятностью PLPS=1−PMPS. Массив P, по сути дела, выродился в одно число. Этим числом может быть PMPS, но с тем же успехом этим числом может быть и PLPS.
До сих пор положение на числовой оси текущего отрезка, который мы делим при кодировании сообщения, характеризовалось положением конечных точек этого отрезка L и H. Очевидно, что описывать текущее состояние процедуры арифметического кодирования (положение отрезка на числовой оси) можно и с помощью чисел L и R, где R — длина отрезка. Именно такое описание используется в стандарте HEVC.
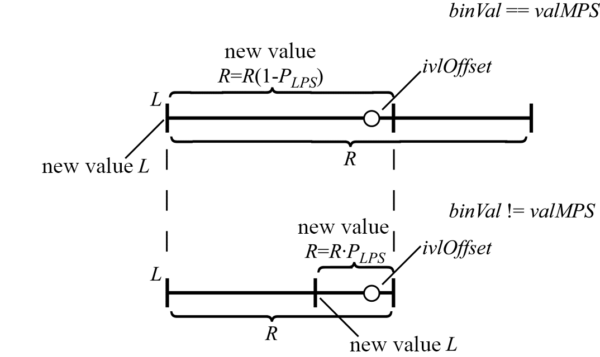
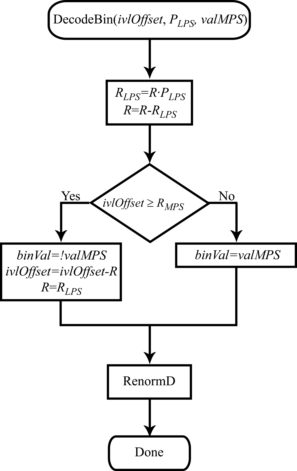
Итак, пусть число, характеризующее соотношение частей отрезка при его итеративном делении, будет равно PLPS. Обозначим, используя обозначения из стандарта HEVC, значение (0 или 1) наиболее вероятного бина в кодируемой последовательности за valMPS. Значение текущего кодируемого бина будем характеризовать величиной binVal. Положение левой границы текущего интервала по-прежнему будем обозначать значением L. Длину текущего интервала — R. В том случае, если значение текущего кодируемого бина равно valMPS, вычисление новых значений L и R по их текущим значениям и PLPSможно вычислить как (рис. 1):
R=R(1−PLPS)=R−R⋅PLPS,
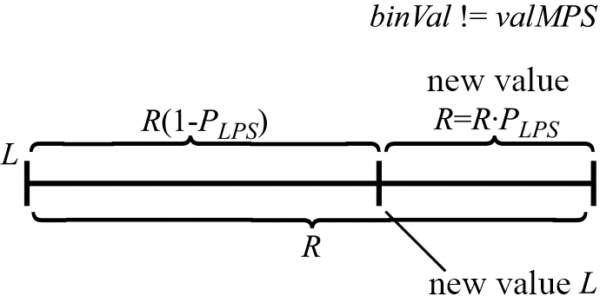
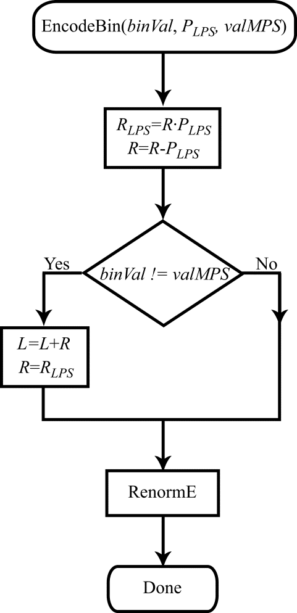
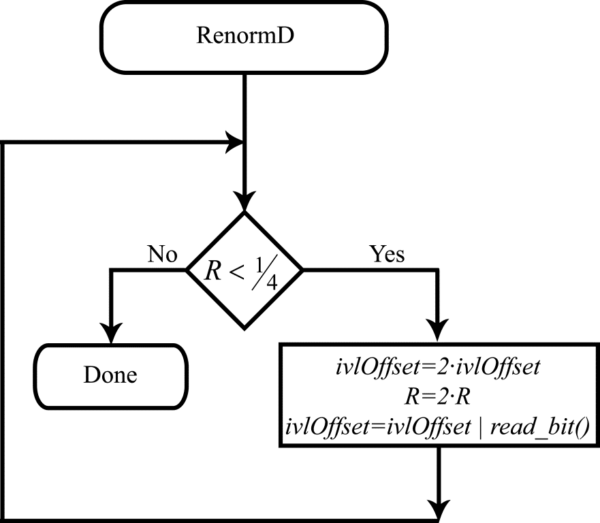
L=L. В том же случае, когда значение кодируемого бина не совпадает со значением valMPS, новые значения L и R определяются выражениями (рис. 2): R=R⋅PLPS, L=L+R(1−PLPS). В результате получаем несколько обновленную блок-схему (рис. 3) алгоритма теперь уже двоичного арифметического кодирования.