

И в очередной раз про мониторинги: как их готовим мы и при чем тут бизнес?

Про мониторинги написано уже примерно 100500 статей, но это не значит, что нельзя делиться продакшен-опытом. Я Виктор Глембицкий, управляющий партнер компании-разработчика Haiku Dev. Одна из наших услуг — копипаста с западных сервисов — Managed Service Provider. Запустились недавно, пока в управлении порядка 400 серверов.
Часто в диалоге с бизнесом, для которого ИТ по МСФО не относится к активам в бухгалтерском балансе, очень сложно бывает обосновать какие-то изменения в инфраструктуре. Поэтому мы стремимся говорить на языке цифр, денег, активов и пассивов, что делает коммуникацию гораздо продуктивнее.
Как видит бизнес ИТ-департамент? Речь тут пойдет именно о бизнесах, где ИТ — это не основной вид доходов. Надо для начала нанять в штат айтишников с их непомерными аппетитами по зп, потом они попросят денег на сервисы, on-prem или облака — не суть важно. А через несколько ротаций кадров будут вынуждены прибегать к услугам аутсорсеров, потому что «надо же как-то разгребать этот бардак и легаси». Словом, одни расходы, которые растут как снежный ком.
Любой предприниматель относится к костам соответствующе — их надо резать. Поэтому очень часто коллеги в подобных штатах оказываются в ситуации, когда куча проблем, а ресурсов на решение нет. Так и живут.
На мой взгляд, причина этому — недостаточно прозрачная коммуникация между ИТ и бизнесом. Нет связующего звена между пассивами и соответствующими активами, поэтому бизнесу очень трудно становится принимать финансово взвешенные решения.
Вот этот пробел в коммуникации мы и пытаемся заполнить. И хорошее подспорье здесь — наш мониторинг. Расскажу, как мы его готовим, и буду признателен за обратную связь. Потому что всегда можно сделать лучше, чем есть.
В статье расскажу о сервисе мониторинга MSP (managed service provider), его ключевых понятиях, архитектуре и техническом стеке.
Для чего нужен сервис мониторинга MSP и как он работает
Сервис мониторинга MSP отслеживает состояния приложений, реагирует на изменения производительности и выдает аналитическую информацию о работоспособности системы и ее элементов. Ключевое — он покрывает 100% обслуживаемой инфраструктуры, позволяя полностью ее контролировать. Основные понятия сервиса — модели здоровья и алертинг.
Сервис мониторинга является геораспределенным. Почему так? В нашей практике были кейсы, когда падал ЦОД, а с ним и обслуживаемый сервис, а с ним и мониторинг с алертингом. К сожалению, о таких случаях узнавали от клиентов, что и стало поводом прийти к геораспределенности.
Базовое значение, на которое мы ориентируемся — SLA. Целевой ориентир для обслуживаемых бизнес-систем составляет 99,9%. Здесь мы говорим о SLA-аптайме на сервисы, не на железо. Как правило, этот параметр не нужно объяснять тем, кто работает с инфрой и уже получает SLA от облачных провайдеров. Отличие только в том, что облако дает SLA на доступность виртуальных машин и сеть, а мы — на сервисы, которые крутятся на этих виртуалках.
Модель здоровья
При использовании сервиса мониторинга существует 3 уровня (tier) глубины.
1-ый уровень (1 tier). Базовая модель
На первом уровне все сервисы подключаются к ядру системы и начинается контроль базовых параметров хелсчека. Для виртуальных и on-premise машин это означает наблюдение над CPU и его загрузкой:
- загрузка RAM,
- остаток свободного места на дисках,
- сетевая доступность,
- даты экспирации доменных имен и HTTPS-сертификатов,
- синхронизирование DNS и сервисов времени (NTP) и DNS.
Проводится документирование обслуживаемой системы, количества и качества различных сервисов, статусов EOS, EOL, циклов жизни используемого ПО, а также контроль доступов и наличия SSH-ключей, обслуживающих систему команд.
Подключается первичный алертинг. Базовая модель — это список правил-алертов, которые позволяют избежать наступления большего количества инцидентов и предотвратить их.
2-й уровень (2 tier). Расширенная модель
На втором уровне выделяются сервисы, уникальные для конкретной инсталляции:
- редко используемые виды сервисов,
- продукты внутренней разработки,
- кастомные решения.
На данном этапе модель здоровья расширяется, учитывая специфику работы данных конкретных сервисов, и добавляется в пул правил-алертов для исключения специфических инцидентов.
3-й уровень (3 tier). Бизнес-модель
На заключительном уровне выделяются конкретные сервисы, обслуживающие определенные потоки данных, работоспособность которых критична для бизнеса. Выставляется приоритет сервисов с точки зрения критичности простоя.
Например, к инфраструктурам финтеха ключевыми параметрами будут TPS (transactions per second). Деградация данного показателя будет свидетельствовать о существенных убытках.
В инфраструктурах, которые по SLA несут ответственность перед третьими лицами, простой сервиса отправки данных может привести к штрафам контролирующего органа. На данном этапе оценивается производительность и масштабируемость инфраструктуры в разрезе ценности для бизнеса.
Алертинг
Чтобы предотвратить простой сервиса, нужно своевременно уведомить команду поддержки о необходимости вмешаться в работу инфраструктуры. При использовании корректно настроенных моделей здоровья алерты приходят только в те моменты, когда необходимо вмешаться в работу системы.
Алертинг распространяет уведомления через множество каналов — публичные или частные корпоративные мессенджеры, электронную почту, телефонию. Система учитывает уровни ответственности персонала (L1, L2, бизнес-владельцы инфраструктуры) и настраивается на различное время оповещения.
К примеру, информация о мажорных инцидентах приходит всем группам лиц в любое время суток. Информация о необходимости провести технические работы — в первую очередь в департаменты обслуживания L1 и L2.Тут интересен вопрос биллинга. Потому как вменяемая обслуживающая сторона должна прореагировать на алерт и приступить к устранению инцидента. Это означает, что работа может догнать вас и в выходной, и в праздник, и (как меня) в день рождения. По закону РФ, такие работы владелец сотрудников исполнителей должен оплачивать по двойному тарифу.
Мы обходимся проще. При таких работах, если они совокупно занимали не более 24 часов накопленным итогом в месяце, делаем дейофф для исполнителей без увеличения счета для клиента. Ну и, конечно, постинцидент ревью.
Реагирование
При обслуживании систем для разных типов задач и сообщений алертинга используются различные временные промежутки и время реакции.
Инцидент — 24/7, время реакции L1 — 15 минут.
Запрос — 8/5, время реакции L1 — 1 час.
Используется матрица зависимости уровня влияния (импакт) инцидента и срочности его устранения. Матрица разрабатывается после установки системы на 3-й уровень мониторинга. К этому моменту можно точно определить и все группы лиц, заинтересованные в использовании инфраструктуры, и критичность SLA каждого сегмента в целом.
| Уровень влияния | Уровень влияния | Уровень влияния | Уровень влияния | ||
| Внешний клиент | Департамент | Сервис | Пользователь | ||
| Уровень критичности | Мажорный | Критический | Критический | Серьезный | Средний |
| Уровень критичности | Высокий | Критический | Серьезный | Средний | Незначительный |
| Уровень критичности | Средний | Серьезный | Средний | Незначительный | Незначительный |
| Уровень критичности | Низкий | Средний | Незначительный | Незначительный | Незначительный |
Архитектура сервиса
Чтобы уменьшить зависимость от конкретного провайдера услуг, мы используем геораспределенные сервисы от разных поставщиков.
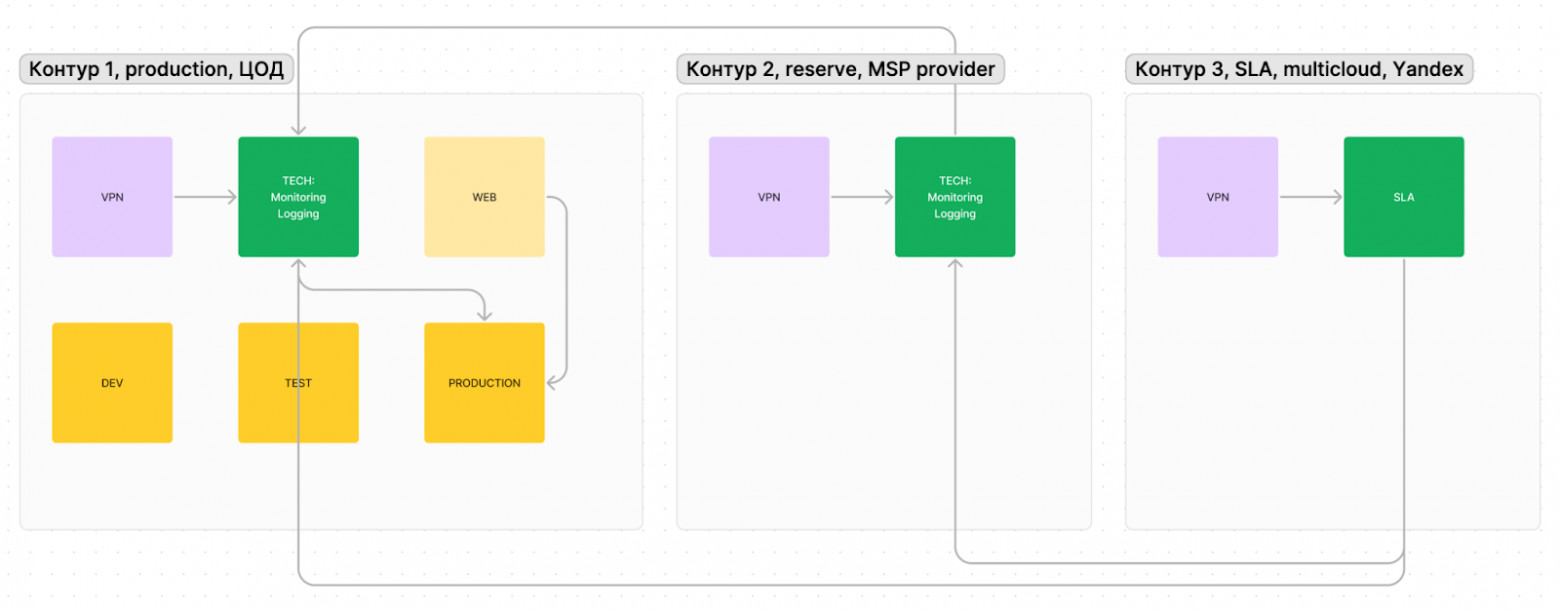
Основной сервис располагается в целевой инфраструктуре (здесь для простоты примера используется 1 ЦОД), к мониторингу подключены продуктивные контуры. Все данные в деперсонифицированном виде агрегируются в контуре ЦОДа.
Во втором контуре находится резервный инстанс мониторинга, который призван сообщить о проблемах, если недоступен основной мониторинг. Этот подход позволяет получать сообщения в крайних случаях, когда мониторинг не может сообщить о проблемах, так как ЦОД недоступен.
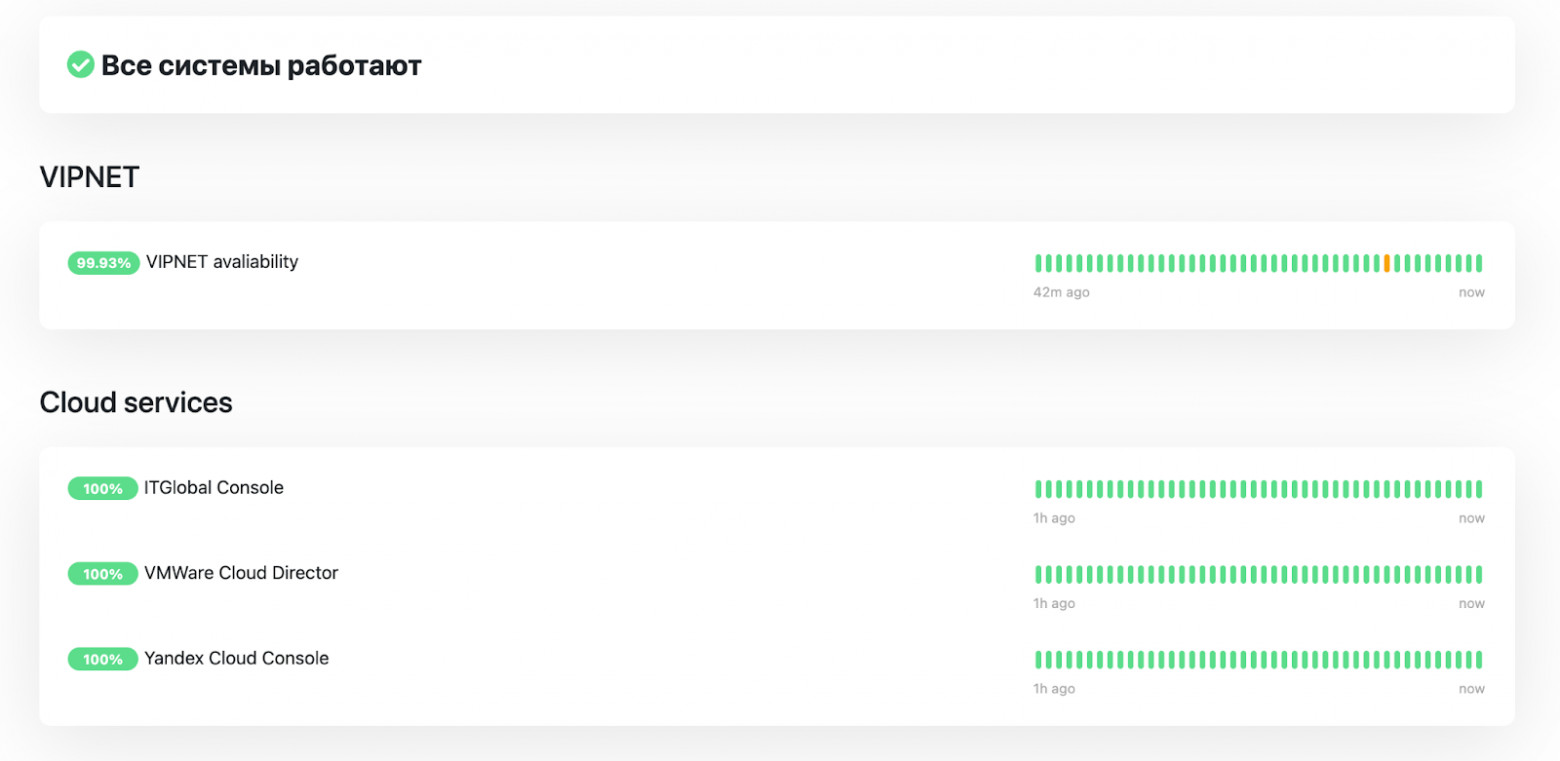
В третьем контуре — сервисы, транслирующие uptime SLA в удобном виде для разных групп пользователей. Здесь мы указываем как SLA сервисов, за которые несем ответственность, так и SLA внешних провайдеров и поставщиков услуг.
Сервис очень удобен и в первоначальной диагностике проблем системы, и он позволяет оперативно коммуницировать с большими группами заинтересованных лиц.
В рамках выполнения роадмапа иногда требуется организовать запланированный простой сервиса. Тогда нужно согласовать простой с бизнесом, выбрать временные промежутки минимальной нагрузки, уведомить заинтересованных пользователей о технических работах. Согласованный промежуток простоя влияет на конечный SLA и не учитывается при оценке месячных результатов работы инфраструктуры.
Технический стек
При выборе стека мы ориентируемся на инструменты, поддерживаемые Cloud Native Computing Foundation, а также на инструменты, верифицированные временем. Из фреймворков являемся апологетами подхода Infrastructure as Code, который минимизирует влияние человеческого фактора на производимые в инфраструктуре изменения. Обслуживание как процесс становится более прозрачным с точки зрения управления и владения.
Базовый технологический стек сервиса мониторинга:
Grafana — сводный дашборд метрик,
Prometheus — основной инструмент сбора и обработки метрик,
TSDB — база данных хранения метрик Prometheus (time series database),
Kuma — сервис калькуляции SLA,
Loki — сервис агрегации логов.
В зависимости от бизнес-целей и задач клиента в виде расширений могут использоваться следующие продукты:
ELK — Elasticsearch Logstash & Beats, Kibana. Для нагруженных корпоративных систем с ориентацией на JAVA. В качестве опенсорс замены может использоваться OpenSearch.
Icinga — как форк Nagios с поддержкой всего возможного спектра модулей, а также с поддержкой InfluxDB — одной из TSDB баз данных, разработанных для хранения и обработки специфичных для мониторинга данных. Используется в проектах с большим количеством физических устройств от 1000 юнитов и выше.
Доработка коннекторов
Бывают ситуации, когда необходимо контролировать крайне специфическое оборудование. В таких случаях разрабатывается специализированный коннектор либо работа с такими сервисами идет на протоколах низкого уровня (SNMP и другие).
Автоматизация
Основными инструментами автоматизации является Ansible и модель плейбуков.
Поддержка процессов разработки, CICD, DevOps-практики
В качестве систем хранения кода используем GitLab, CI/CD на базе Docker.
Масштабирование и скейлинг
На базе системы мониторинга реализован скейлинг. Это особенно актуально для инфраструктур с динамическим уровнем трафика. К примеру, черные пятницы в ритейле, когда в определенные периоды времени возможно многократное превышение обычных значений нагрузки. Мониторинг отслеживает объем трафика и поднимает или гасит ноды, обслуживающие данный трафик.
Виртуализация и облачные провайдеры
Используемые системы виртуализации:
- VMware
- OpenStack
- Провайдеры с управляемыми сервисами (Yandex, Selectel)
- vStack (крайне рекомендуем посмотреть на эту российскую разработку виртуализации)
- Облака ITGLOBAL
- ЦОДы «Атомдата-Иннополис».
Технические инструменты
- Система коммуникаций Mattermost как защищенный корпоративный мессенджер.
- ITSM-система получения и обработки заявок с фиксированием затраченного на обслуживание времени.
- Альтернативные резервные каналы для коммуникаций.
- Системы хранения критичной информации (пароли, доступы) как для сотрудников (на базе платформы Passwork), так и для целей разработки (Vault).
- Система хранения знаний на базе Outline Wiki или MkDocs.
- Яндекс 360 для бизнеса, инструменты рассылок, различные боты.
Кейсы
Поддержка и развитие инфраструктуры
В одном из проектов мы обслуживаем инфраструктуру клиента, у которого несколько пунктов взимания платы (ПВП). Мы осуществляем SRE-поддержку, оперативно реагируем на инциденты. Наша задача — не только поддерживать стабильную работу системы, но и осуществлять ее развитие, что включает в себя замену серверов и ключевых элементов инфраструктуры клиента.
Одним из особенных аспектов проекта является обслуживание закрытого программного обеспечения по управлению ПВП, разработанного французской компанией, которая покинула российский рынок. С помощью мониторинга мы обеспечиваем функционирование финансового ядра и более 3 000 точек оборудования, расположенных как на пунктах ПВП, так и между ними.
Обслуживание транзакционного ядра сети POS (point-of-sale)
Например, в одном из проектов мы работаем с транзакционным ядром, к которому подключено около 400 точек по всей России. Ядро обеспечивает более 1 200 000 транзакций в месяц.
Ключевые игроки рынка используют ядро через API для осуществления транзакций по перепродаже. Проект предполагает работу с персональными данными по 152-ФЗ, а также использование защищенных информационных контуров с продуктами Vipnet Coordinator.
На этом по теме пока все. Очень буду признателен за обратную связь от коллег, кто по долгу профессии занимается настройкой и обслуживанием мониторингов и поделится опытом, как удается строить «хрустальный» мост коммуникации между ИТ и бизнесом.
А еще мы с командой Haiku Dev будем рады помочь, если у вас возникла потребность в экспертной оценке или разработке новых технологических решений под задачи вашего бизнеса. Предлагаем комплексный подход к решению ИТ-задач, включающий высокоуровневый консалтинг, дизайн продуктов, разработку, внедрение программного обеспечения и подбор ИТ-инфраструктуры.