

Big Data: История одного нотификатора

Представим, что вы очень любите футбол.
Согласитесь, было бы неплохо иметь собственный сервис с уведомлениями о последних новостях из мира футбола? Еще лучше, если бы вы с помощью фильтров могли избавить себя от просмотра нескончаемого мусора, вызванного очередной трансферной сагой.
Или представим, что вы музыкальный фанат. Как среди огромного количества музыкальных порталов узнавать важную информацию о своих любимых группах и исполнителях без траты собственного времени?
Не стоит сдаваться и ждать милости от новостных порталов. Пришло время взять все в свои руки.
Когда подборка новостей с существующих ресурсов не устраивает, а вы просто хотите быть в курсе, узнавать инсайды и читать новости в оригинале поможет система iDVP.Data SaaS. Вы можете настроить формирование новостной ленты под свои предпочтения, как с сайтов, имеющих свое API, так и с с обычных сайтов (скрапинг – милое дело).
iDVP.Data SaaS - это инструмент, позволяющий работать с вашими данными в облаке. Как это работает?
Зайдем на сайт платформы https://idvp.io/ и зарегистрируемся.
 После завершения регистрации мы попадаем на стартовую страницу, где можем ознакомиться с демонстрационными рабочими пространствами..
После завершения регистрации мы попадаем на стартовую страницу, где можем ознакомиться с демонстрационными рабочими пространствами..

Но так как обучаться в процессе, на мой взгляд, эффективнее – перейдем к решению нашей задачи.
Сперва определимся с составом команды, ее названием и распределением ролей. После отправки приглашения участник получает на свой e-mail ссылку для доступа к рабочим пространствам команды.
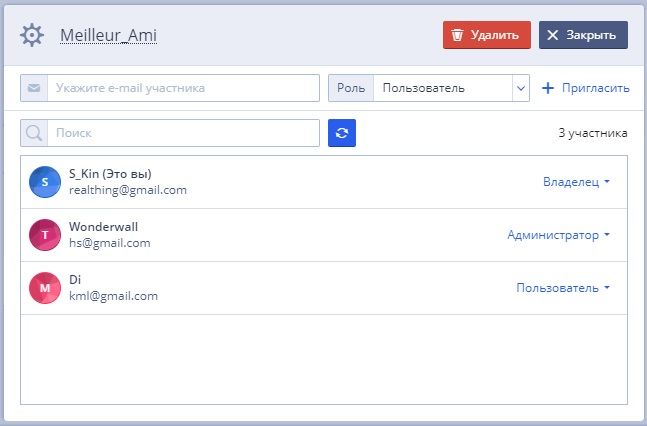
В любой момент мы можем изменить роли, а также пригласить и удалить участников команды.
Добавляем новое рабочее пространство, в котором мы будем строить поток данных (цепочка от источников данных до выходных сервисов).
Допустим, нас интересует Ла Лига и АПЛ и мы выбираем, соответственно, сайты газет Marca и The Telegraph. РФПЛ тоже добавим, поэтому еще подключимся к sports.ru
Заходим на wrapapi.com (заранее регистрируемся) и поочередно делаем API для каждого из источников.
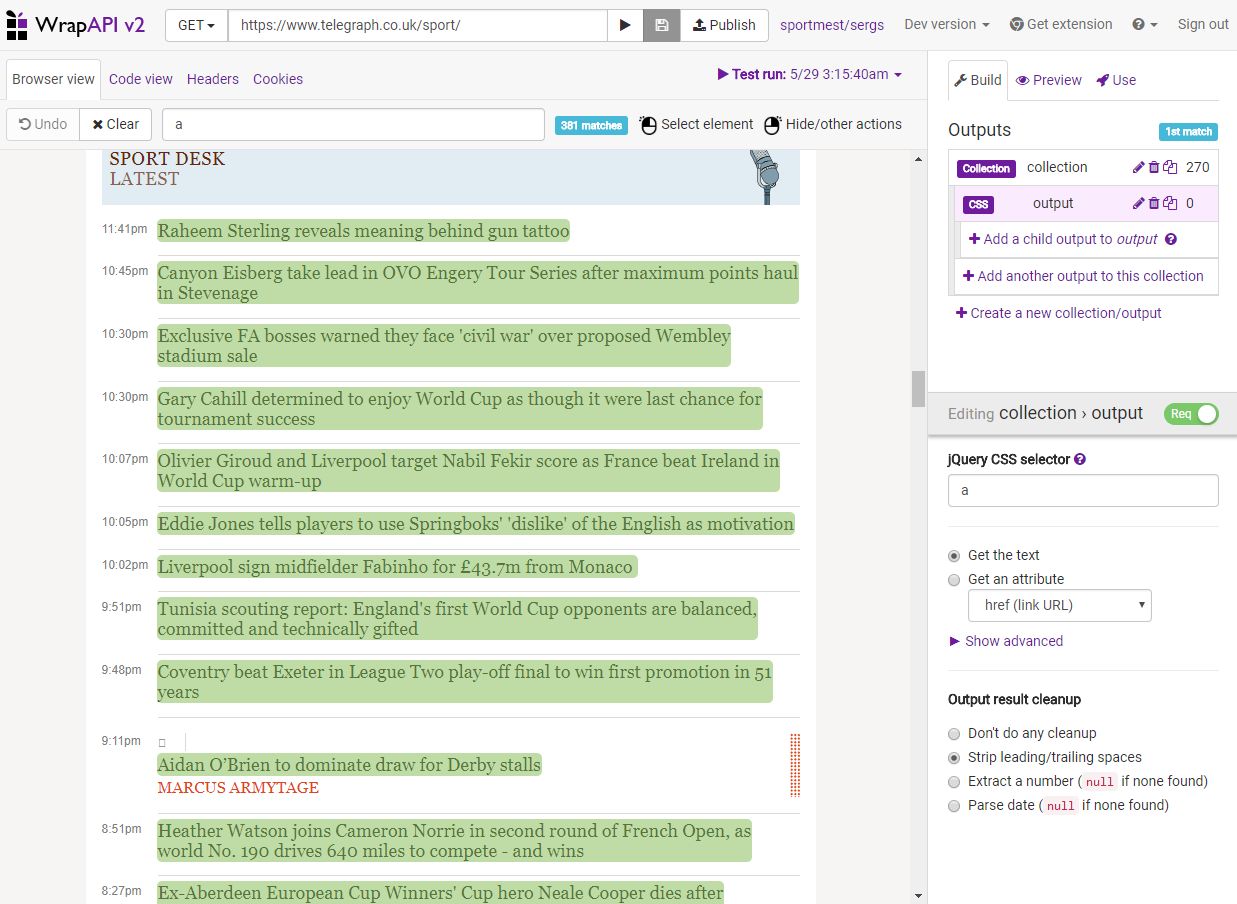
Выделяем элементы веб-страницы, относящиеся к заголовкам новостей (с такой привязкой мы сможем обновлять данные в будущем – они попадут в наш новоиспеченный API:
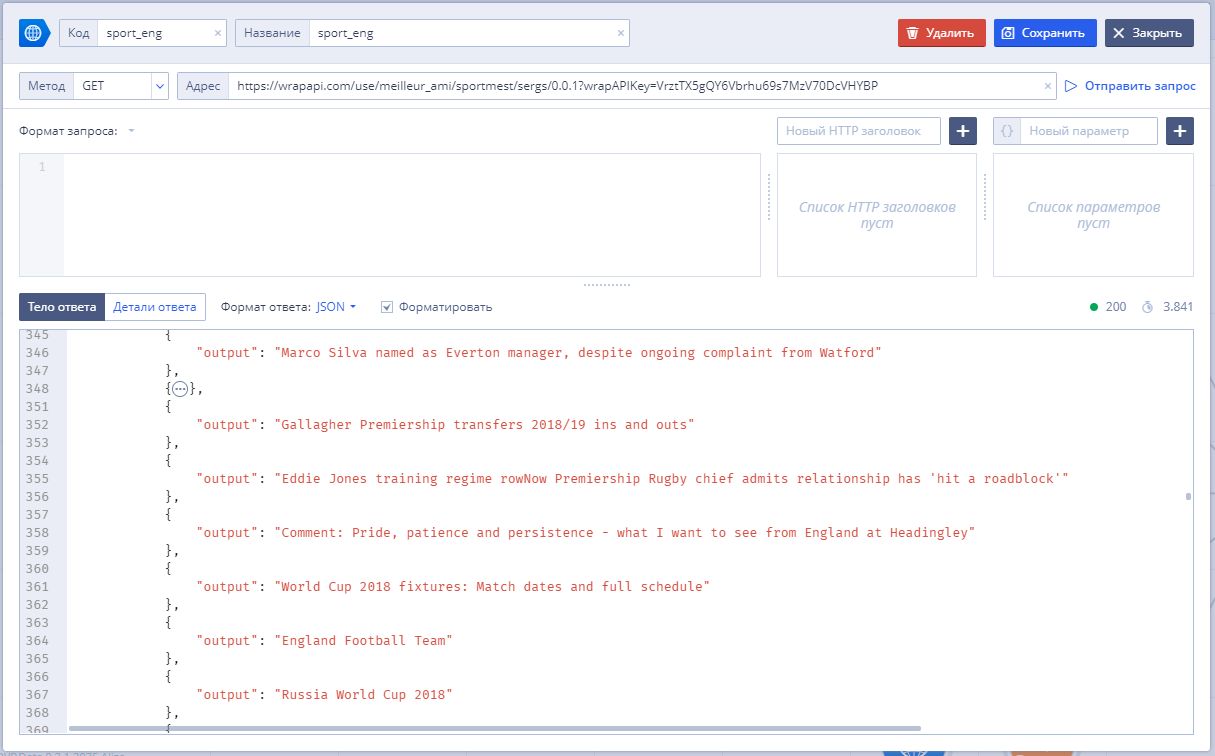
 Возвращаемся к нашему рабочему пространству и подключаем наше сконструированное API и выполняем запрос для проверки подключения. Выставляем формат ответа, как JSON (также доступен XML, TXT) и сохраняем:
Возвращаемся к нашему рабочему пространству и подключаем наше сконструированное API и выполняем запрос для проверки подключения. Выставляем формат ответа, как JSON (также доступен XML, TXT) и сохраняем:
 Далее нам нужно привести этот ответ в табличный вид. Для этого мы создаем наборы данных (Datasets), где выполняем различные преобразования над данными полученными из источников (очистка данных, вычисления или, например, парсинг данных из JSON) при помощи SQL-скриптов. В результате получаем преобразованные данные:
Далее нам нужно привести этот ответ в табличный вид. Для этого мы создаем наборы данных (Datasets), где выполняем различные преобразования над данными полученными из источников (очистка данных, вычисления или, например, парсинг данных из JSON) при помощи SQL-скриптов. В результате получаем преобразованные данные:
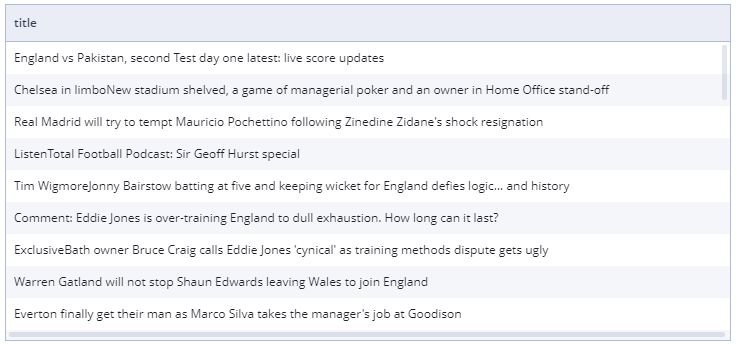 После подключения данных и их преобразованию скорость доступа полученной информации все еще может быть низка (из-за долгого ответа источника или из-за большого объема данных). Здесь срабатывает механизм «материализации» (сохранения) данных в самой iDVP.Data SaaS. Обращение к сохраненным данным осуществляется крайне быстро даже при работе с большими объемами информации за счет использования технологий BigData.
После подключения данных и их преобразованию скорость доступа полученной информации все еще может быть низка (из-за долгого ответа источника или из-за большого объема данных). Здесь срабатывает механизм «материализации» (сохранения) данных в самой iDVP.Data SaaS. Обращение к сохраненным данным осуществляется крайне быстро даже при работе с большими объемами информации за счет использования технологий BigData.

Опережая вопрос: «Смогу ли я накапливать данные, а не получать каждый раз с нуля?». Без проблем.
В таком случае вам поможет инкрементальное обновление, которое будет накапливать новости по установленному вами расписанию:

По аналогии подключим новостной источник Marca.
По пути заглянем на Last.fm, чтобы добавить немного музыки нашему нотификатору.

Единым запросом собираем все источники в одну витрину данных (web-сервис, объявление которых осуществляется также SQL-запросами).
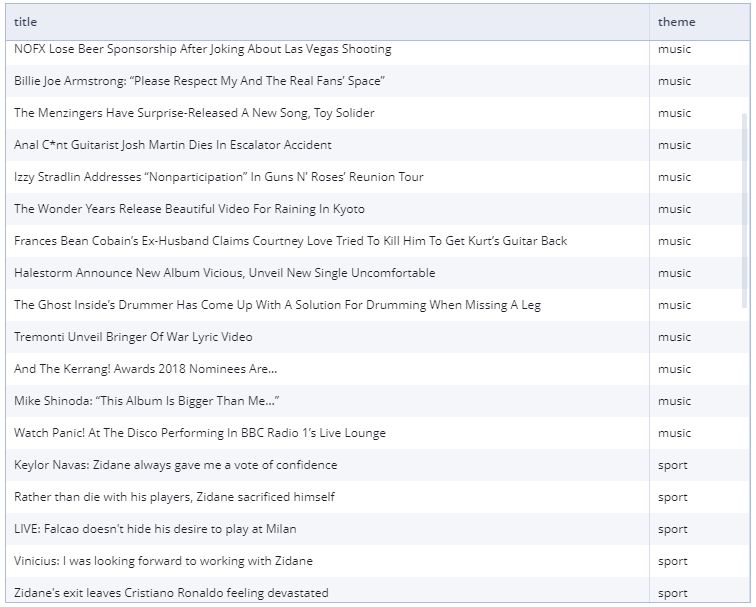 После сохранения мы видим итоговый для нашей задачи поток данных:
После сохранения мы видим итоговый для нашей задачи поток данных:
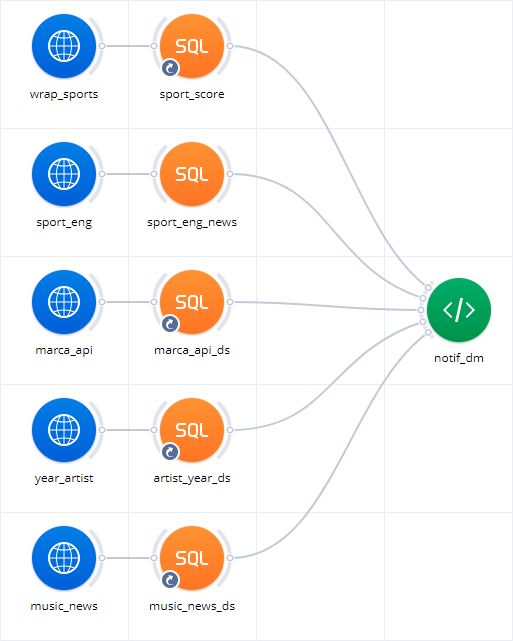
После формирования витрины данных, мы можем сделать ее публичной, выставив флажок напротив «Данные доступны внешним пользователям» или же закрытой.
Полученную ссылку можно предоставлять во внешние системы и подключать, как сервисы, в которой будут передаваться ваши данные в формате JSON.

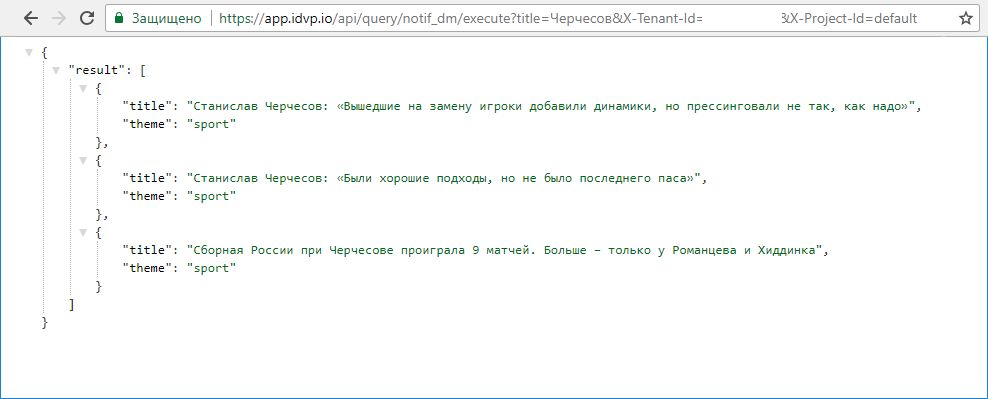
Теперь мы получили нотификатор в свое распоряжение и можем подвести итоги.
Если нужно быстро и легко справиться с данными, то можно воспользоваться системой iDVP.Data SaaS, которая на данный момент проходит этап бета-тестирования. Наша команда надеется, что среди вас, дочитавших эту историю до конца, есть те, кто станут первыми тестировщиками нашего нового инструмента.
С его помощью вы сможете самостоятельно:
- подключаться к различным источникам;
- единообразно получать данные из любых источников;
- выполнять ETL-преобразования данных при помощи SQL;
- повышать скорость работы с данными с помощью технологий BigData;
- анализировать данные;
- предоставлять данные во внешние системы;
- осуществлять данные операции в удобном и простом интерфейсе.
Удачи!