

Как найти и объединить дубли клиентов

Почему дубли вредят бизнесу
Пожалуй, все сталкивались с тем, что один и тот же клиент заведен в базах данных компании несколько раз. Причин этому множество, в том числе, любимый «человеческий фактор». Например, клиент авторизовался на сайте интернет-магазина, а потом позвонил в call-центр или обратился лично и менеджер повторно внес его данные.
Путаница в клиентской базе может обернуться большой проблемой для компании и вот почему:
- Ошибки в проведении маркетинговых кампаний, планировании продаж, закупок и т.д.
- Репутационные потери, возникающие, например, в следствие ошибочных рассылок и спама.
- Отток клиентов из-за того, что усилия на удержания не доходят до нужных адресатов.
- Лишние траты на коммуникации с клиентами.
- Отсутствие четкого представления о реальном объеме клиентской базы, т.к. зачастую дубли могут составлять десятки процентов от общего количества контрагентов.
Перечисленные последствия — малая часть проблем. Cо временем они усугубляются и разрастаются, как болезнь, становятся причиной все бОльших и бОльших убытков.
Что же такое дубли
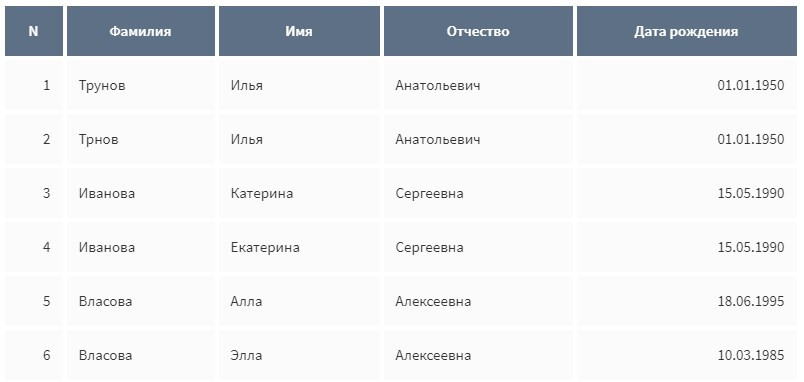
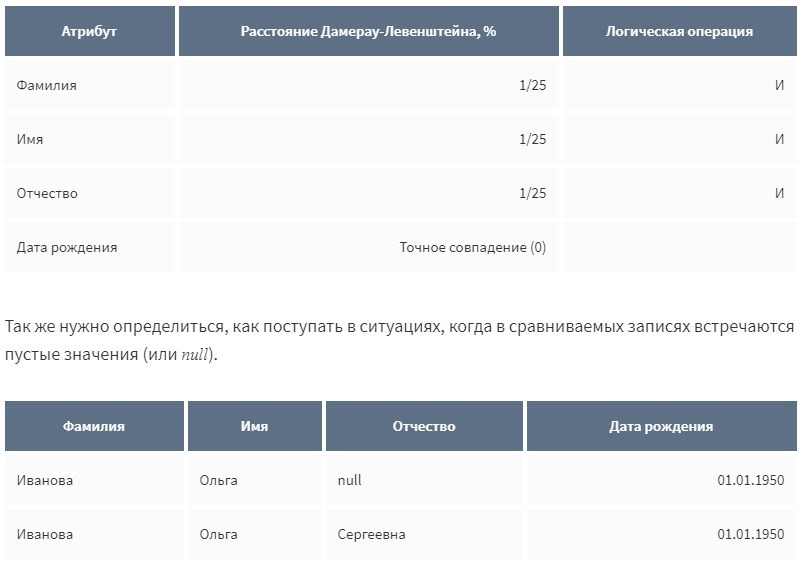
В общем случае под дублями понимаются несколько записей в учетных системах, относящихся к одному клиенту. Типичный пример таких данных: Карточки 1 и 4 являются полностью идентичными и относятся к одному клиенту, при этом карточка 3, вероятно, также относится к этому же клиенту, а различие обусловлено опечатками и пропусками при заполнении. А вот карточка 2 относится к совершенно другому клиенту и не является дублирующей. Таким образом, можно выделить полные и потенциальные дубли. Основной задачей дедупликации является настройка таких алгоритмов поиска, которые с одной стороны, максимизируют количество записей, относящихся к одному клиенту, а с другой — минимизируют ложные срабатывания, т.е. попадания в группу дублей записей о другом клиенте. Большинство негативных последствий можно избежать, если «причесать» информацию, настроить и внедрить систему дедупликации данных. Наиболее эффективный подход, используемый в решении Loginom Data Qualityдля устранения проблемы дублей, состоит из следующих шагов: Расскажем подробнее о каждом шаге поиска дублированных записей. До начала дедупликации нужно оценить степень загрязненности карточек клиентов. Как правило, ситуация с качеством данных в CRM-системахсложная. Операторы вводят данные о контрагентах «как придется». Одна из проблем — разные форматы атрибутов клиентов: ФИО, телефоны, e-mail, документы, адреса. Распространенная ситуация, когда ФИО записано в CRM-системах в разных последовательностях, например, Александров Иван Сергеевич и Иван Сергеевич Александров. Еще чаще не структурированы адресные данные, номера телефонов и документов. Такие записи при автоматической проверке на полное совпадение будут определены как разные. В этих случаях для повышения эффективности поиска дублей все атрибуты приводятся к унифицированному стандарту, а адреса к формату ФИАС. Другая проблема — опечатки: — Ошибочный ввод символов, расположенных рядом на клавиатуре, например, вместо Федор пишут Ыедор или вместо 74 АА 397530 записано 74 АА 297530. — Смешанные символы из разных алфавитов со схожим написанием, например, в написании номера водительского удостоверения 74 АА 397530 символ А может быть записан латиницей и такое написание не совпадет с написанием полностью на кириллице. — Неверный язык при вводе букв, например, Иван будет записан как Bdfy. Все эти типы ошибок учитываются в решении Loginom Data Quality для формирования «чистых» клиентских атрибутов, которые позже направляются на дедупликацию. В общем случае можно выделить два подхода для сравнения записей и поиска дублей — полное совпадение и нечеткое сравнение. Каждый из подходов имеет свои плюсы и минусы. Проверка на полное совпадение является простой и быстрой, что особенно важно, когда клиентская база — десятки миллионов записей. Однако, для корректного решения задачи дедупликации недостаточно только точного совпадения клиентских атрибутов. Множество клиентских записей содержат опечатки и пропуски, поэтому точное сравнение не позволит найти все дубли, следовательно, их не получится очистить и стандартизировать. Для улучшения качества дедупликации целесообразно применение нечеткого сравнения — сопоставления значений на основе метрик схожести, таких как расстояния Хемминга, Левенштейна, Дамерау-Левенштейна. Такие методы позволяют найти кандидатов в дубли, которые невозможно обнаружить при помощи сравнения на полное совпадение, но расчет нечетких метрик схожести является ресурсоемким. Это приводит к снижению производительности на больших объемах данных, а также необходимости оптимизировать процедуру сравнения, что является нетривиальной задачей. В решении Loginom Data Quality для поиска дублей используется комбинированный подход с использованием точного и нечеткого сравнения, который выражается в применений стратегий поиска — наборов условий сравнения различных клиентских атрибутов, при выполнении которых записи будут считаться дублями. Рассмотрим примеры стратегий поиска дублей для сравнения следующих записей: Видно, что в ФИО значения расходятся в один символ, поэтому использовать точное сравнение по данным атрибутам нельзя. В качестве метрики выберем расстояние редактирования. Если мы зададим его равным 1, то, казалось бы, найдем нужные дубли, но при этом записи 5 и 6 имеют разное имя и явно относятся к разным клиентам. Для этого нужно при сравнении записей учитывать длину строк. Таким образом, получаем один из критериев сравнения — расстояние редактирования не более 1 и при этом, не более 25% от длины сравниваемых строк. Но и в этом случае могут возникнуть ошибки. Так, в записи 2 может оказаться значение Трынов и строки 1 и 2 уже будут относятся к разными клиентам. Да и в целом, даже полное совпадение ФИО не дает основания считать записи дублями. Нужно вводить еще один критерий на точное совпадение, например, по дате рождения. Здесь есть два варианта: Также, стоит обратить внимание на то, что некоторые дубли не всегда можно выявить автоматически. В этом случае используются более «мягкие» стратегии — наборы условий с менее жестким порогом совпадения. Результаты работы таких стратегий далее попадают на ручную обработку.
Как с ними бороться
Очистка клиентских данных
Методы и стратегии поиска дублей
Подведем итоги