

Обучение семантической модели куратором

Как мы уже упоминали в предыдущих материалах, при использовании в архитектуре диалоговой системы механизма курации, процесс формирования модели может быть разбит на два этапа:
- Начальное конфигурирование модели. Описание всех элементов модели со списком их базовых синонимов. Проводится на начальном этапе разработки.
- Отложенное обучение куратором. Проводится в режиме функционирования сервиса, путем отслеживания, анализа и использования информации по обработанным куратором вопросам, то есть тем, на которые сервис не смог ответить автоматически в силу своего несовершенства, недостаточной степени покрытия синонимами и т. д.
Первый этап является весьма трудоемкой и ресурсозатратной задачей. Чтобы не откладывать старт системы и не тратить значительных усилий на попытку создания идеальной модели, часть работы по ее дальнейшему совершенствованию можно перенести на второй этап.
Ниже приведен обзор подходов и алгоритмов для решения задачи отложенного обучения, применяемых в компании DataLingvo. Однако основные используемые методы и принципы совпадают для большинства решений подобного рода.
Процесс курирования
Куратор помогает системе распознать вопрос, который она не смогла обработать автоматически, как правило редактируя его.
Редактирование — это правка существующих и удаление лишних слов, но иногда и наоборот, добавление дополнительных элементов, понимаемых куратором лишь из контекста или просто на основе собственного экспертного знания сущностей, не нашедшего отражения в спроектированной модели.
Основная задача последующей автоматизации — максимально эффективно воспользоваться результатами курирования и научить модель понимать множество похожих вопросов.
Пример. Пусть мы разрабатываем ассистента для ответов на следующие типы вопросов “Сколько сейчас времени в таком-то городе“.
Примечание — подобный пример представлен среди прочих примеров системы DataLingvo https://github.com/aradzinski/datalingvo-examples — “Time example”
1. В нашем примере будут задействованы всего две сущности:
- Индикатор вопроса “время” [TIME]
- Параметр “город” [GEO:CITY]
2. Кроме того для простоты запретим использование свободных слов. Примечание. При использовании DataLingvo, GEO — это встроенный элемент и вам не придется при разработке модели каким-то специальным образом распознавать понятие “город”.
Сущность [TIME] можно определить через минимальный набор синонимов, таких как:
- What time is it
- What is local time
Таким образом наша максимально упрощенная модель состоит из единственного семантического шаблона [TIME][GEO:CITY]:
Пример обработки:
- Вопрос “What time is it in Tokyo” при такой конфигурации сразу распознается и будет отвечен.
- Вопрос “What time is it in Tokyo now” уже не может быть отвечен немедленно. Помешает нераспознанное свободное слово “now“. Вопрос перейдет на стадию курации.
- Куратор исправит текст исходного вопроса таким образом, чтобы он мог бы быть распознан автоматически. В нашем случае самый простой и логичный способ редактирования команды — это удаление не несущего никакой полезной информации слова “now”, после чего запрос будет удовлетворять представленному шаблону и сможет быть обработан в обычном режиме.
Что мы хотим получить от обучения
Теперь нужно продумать, какую максимальную пользу мы можем извлечь из уже проделанной куратором работы. Очевидно, что после курирования система должна стать умнее и научиться отвечать не только на вопрос “What time is it in Tokyo now” но и на все “похожие” вопросы.
Итак на какие именно вопросы следует научиться отвечать дополнительно:
1. На все вопросы с учетом стоп-слов. То есть вопрос “What time is it in Tokyo now, please“ тоже должен быть отвечен. Стоп-слова, в данном примере “please”, не должны помешать предложению быть распознанным автоматически.
2. На вопросы с измененным порядком следования сущностей: “Now, what time is it in Tokyo”. Если отбросить в сторону то, что вопрос сформулирован грамматически некорректно, он тоже должен быть успешно распознан.
Примечание. Эта возможность может быть сконфигурирована, то есть разрешена или запрещена для модели, так как для некоторых систем порядок следования элементов может быть критически важен. Классический пример — это сервис заказа билетов, для которого “Билет от Токио до Лондона” совершенно не тоже самое что “Билет от Лондона до Токио”.
3. На вопросы с той же типовой схемой сущностей. Было бы хорошо, если бы вопрос “What time is it in New York now” тоже был бы отвечен автоматически, несмотря на то, что курирование было произведено для вопроса по городу Tokyo. Система должна распознать сущности одного типа (GEO:CITY для Tokyo и New York).
Также обратите внимание на то, что название города New York состоит из двух слов и это тоже не должно сбить с толку.
4. На некоторые вопросы со схожей с типовой схемой сущностей. Некоторые сущности могут быть склеены или удалены без ущерба для структуры предложения, по которой собственно и будет происходить поиск наиболее подходящих среди уже прошедших курацию вариантов.
Примечание — смотри далее описание формирования ключей поиска.
Например, очень бы хотелось чтобы на вопрос “What time is it in Saint Petersburg, Russia now” также мог бы быть получен немедленный ответ, несмотря на его несколько отличающуюся структуру от структуры ранее прошедшего курацию вопроса. В нашем случае [TIME] [GEO:CITY] [GEO:COUNTRY]
Обратите внимание на то, что подобный подход трудно формализуется и должен применяться для всех подходящих наборов сущностей индивидуально.
5. На вопросы с “похожими” свободными словами. Стоит рассмотреть все синонимы свободных слов в предложении и попробовать найти сохраненные в процессе курирования запросы с “похожими” свободными словами. Похожие — это чаще всего обычные языковые синонимы.
Пример. Ниже представлен результат морфологического разбора предложения (частеречный разбор), построенный в процессе курации.
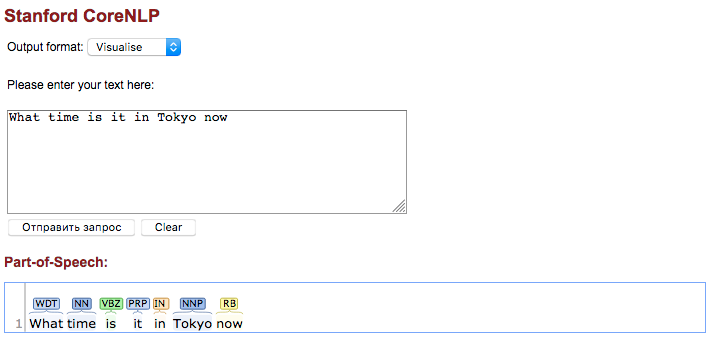
Теги частей речи (POS — Part of speech) соответствуют следующей таблице Penn Treebank II tag set.
Наша задача поддержать возможность автоматического ответа не только на непосредственно исправленный куратором вопрос, но и на все вопросы с синонимами к слову “now”. Заглянем в wordnet и найдем все синонимы слова “now” для части речи “adverb“ (POS тег RB)
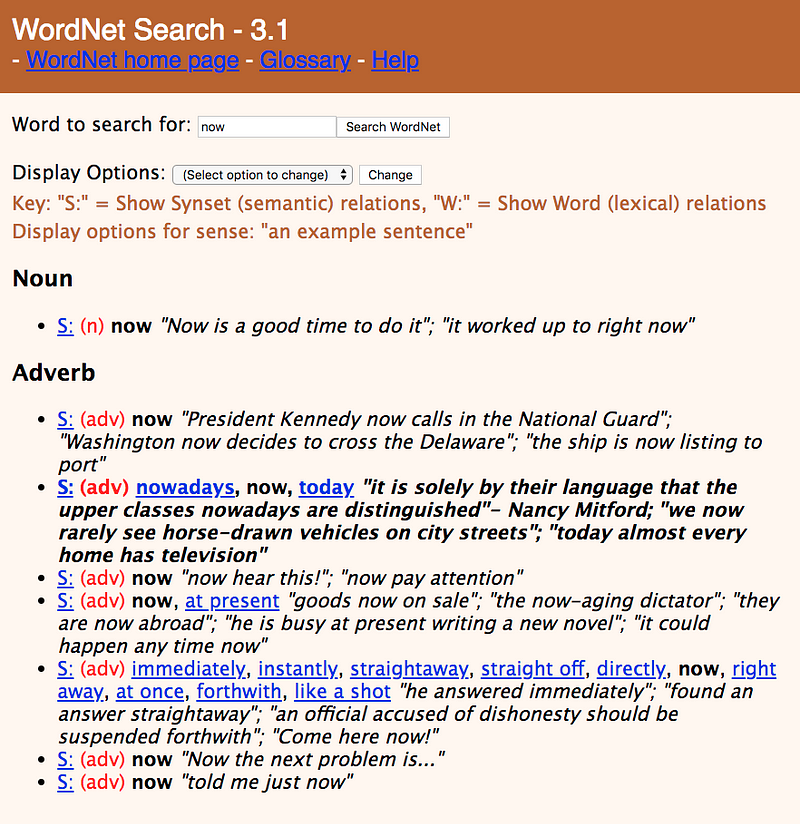
По ссылке видно, что одним из синонимов слова now (с типом RB) является слово today (типа RB). Таким образом, было бы желательно уметь отвечать на вопрос “What time is it in Tokyo (New York, etc) today”.
Для ряда систем подобный подход может выглядеть немного рискованным. Кроме того при использовании WordNet в качестве базы синонимов, имеет смысл осознанно сконфигурировать глубину поиска среди wordnet синсетов, а также количество синонимов на каждый синсет. Подробнее о WordNet и синсентах.
Ограничения для схожих по структуре запросов
После того как в систему поступил новый запрос, не прошедший автообработку, мы пытаемся найти “похожие“ вопросы, ранее сохраненные на этапе курирования.
Примечание — по какому принципу мы их ищем и чем нам это может помочь при ответе на текущий вопрос — будет рассмотрено далее.
Если найденное предложение “очень” похоже и отличается, например, только наличием или отсутствием некоторых стоп-слов, мы можем быть абсолютно уверены в том, что наш новый запрос будет столь же успешно обработан, как и тот, что уже распознан и обработан ранее. По мере уменьшения “степени схожести“, наша уверенность в успешности данной процедуры несколько уменьшается.
Но и вопросы с даже достаточно схожей структурой могут обрабатываться по разному.
Пусть программируемый нами ассистент умеет отвечать лишь на один вопрос — “Какая сейчас погода в Токио“, и только в одном единственном городе. Таким образом вполне “похожий“ вопрос “Какая сейчас погода в Лондоне” не может быть отвечен в принципе, несмотря на всю их очевидную структурную близость.
Иными словами, критерии схожести у систем сравнения текста и модуля обработки пользовательских команд могут не совпадать.
Расширение модели
Рассмотрим процесс шаг за шагом.
1. Куратор редактирует текст не прошедшего автообработку запроса, формируя вопрос с ожидаемой структурой.
2. Для исходного текста формируется набор ключей поиска, состоящих из сущностей, таких как GEO, NUMBERS, DATES и так далее, начальных словоформ свободных слов, POS тегов и, возможно, прочей полезной информации. Стоп-слова должны быть исключены из ключей.
Пример такого набора для “What time is it in Tokyo now”
- [TIME]|[GEO:CITY]|now (сущности + леммы свободных слов)
- [TIME]|[GEO:CITY]|RB (сущности + POS теги свободных слов)
- и так далее
Каждый такой ключ имеет свой “вес”, зависящий от типа преобразования исходного текста. Чем меньше преобразований — тем больше “вес”.
3. В расширенной модели для каждого ключа сохраняется следующий набор информации:
- его “вес“
- начальный вариант вопроса
- отредактированный куратором вариант вопроса
Таким образом модель обогащается новой информацией.
Использование данных обогащенной модели
Что происходит когда в систему поступает новая команда, которая не может быть распознана автоматически?
Она не сразу перенаправляется куратору. Сначала по ее тексту строится набор ключей поиска, по которым мы пытаемся найти уже сохраненные, ранее отредактированные куратором команды с теми же ключами, сформированными по их изначальным текстам.
- Если такие команды не обнаружены, запрос перенаправляется на курирование.
- Если обнаружены — мы пытаемся воспользоваться найденной информацией и программно скорректировать новый пришедший вопрос согласно логике уже примененной куратором к тексту найденной сохраненной команды.
Таким образом, отыскав сохраненные в модели ранее отредактированные предложения, и выбрав одно из них с максимальным весом ключа, мы располагаем следующим набором данных:
- Текст вопроса, на который мы пытаемся ответить (1)
- Сохраненный и прошедший курацию вопрос (2)
- Сохраненный и прошедший курацию отредактированный вопрос, на который система должна уметь ответить автоматически (2’)
Наша задача распознать функцию, которая была применена к (2) для получения (2’) и применить эту функцию к (1) чтобы получить текст (1’), который с некоторой долей вероятности, тоже может быть обработан автоматически.
Алгоритм поиска и применения такой функции задача нетривиальная, он может быть сколь угодно сложен, а также непрерывно развиваться и совершенствоваться с развитием системы. Описание деталей возможных реализаций выходит за рамки настоящей заметки.
Если найти такую функцию в силу каких-либо причин затруднительно или ее применение порождает вопрос, который все равно не может быть автоматически обработан — управление перенаправляется куратору. Все подобные “неуспешные” в обработке запросы должны быть помечены и в дальнейшем обработаны на втором контуре курирования и, по крайней мере в данном существующем виде, исключены из доступных для поиска.
Ниже подробнее о втором контуре курирования.
Второй контур курирования
Первый (основной) контур курирования — это процесс заключающийся в редактировании не прошедших автообработку пользовательских запросов. Мы неоднократно упоминали о нем в данной статье, также он подробно описан в предыдущих заметках. Первый контур может использоваться в режиме близком к режиму реального времени и позволяет быстро отвечать на все типы пользовательских запросов.
Второй контур — это процесс отложенной по времени проверки правильности работы куратора первой стадии. На второй стадии существует возможность удаления результатов курирования первого этапа и, как следствие, исключения из модели некоторых ранее сохраненных предложений. Также на второй стадии куратор делает выводы о состоянии модели, полноте описания синонимов ее элементов, корректности правил построения intents и т. д. Куратор корректирует и дополняет описание модели. Второй контур очень важен для процесса последовательного улучшения качества модели, выявления существующих ошибок и недоделок текущего состояния, а также их исправления.
Выводы
Расширение модели путем анализа результатов работы куратора — мощный механизм, позволяющий сократить время необходимое для описания начальной структуры модели, а также последовательно улучшать ее качества на каждой итерации. Использование второго контура курирования помогает контролировать работу кураторов первой ступени, анализировать состояние модели, своевременно обновлять и расширять ее, с каждым шагом повышая процент автоматически обрабатываемых запросов.
