

Эволюция архитектуры данных. Data Warehouse, Data Lake, Data Lakehouse, Data Fabric, Data Mesh – что это такое, и в чем разница
Эпоха современных хранилищ данных началась с появления реляционных баз данных (далее БД). С появлением бизнес-аналитики следствием развития БД стала концепция Data Warehouse (корпоративное хранилище данных, DWH).
Дальнейший рост объемов данных, введение термина «большие данные» и разнообразие требований к обработке привели к эволюции архитектур данных.
Архитектура данных включает модели, правила, стандарты, которые определяют, как собирать, хранить, размещать, интегрировать и использовать данные для решения бизнес-задач.
Появились концепции:
- Data Lake
- Data Lakehouse
- Data Fabric
- Data Mesh
В статье рассмотрим этапы эволюции архитектуры данных: чем отличаются концепции, какие у них преимущества и недостатки, для каких задач в работе с данными подходят.
Содержание:
- Хронология развития БД и хранилищ данных
- Что такое Data Lake и чем отличается от Data Warehouse
- Data Lakehouse: объединение преимуществ Data Lake и DWH
- Data Fabric — хранилище, усиленное ML
- Децентрализация данных в Data Mesh
Хронология развития БД и хранилищ данных
Чтобы лучше понять, как и почему появились технологии, которые мы используем сегодня, погрузимся в историю возникновения первых БД, СУБД и хранилищ данных.
База данных — это организованный набор данных, который управляется с помощью системы управления базами данных (СУБД).
1960–1970
В связи с развитием банковской и финансовой сферы в 60-х годах появилась потребность в надежной модели хранения и обработки данных.
Принято считать, что современная история обработки данных началась с создания организации CODASYL (Conference of Data Systems Language).
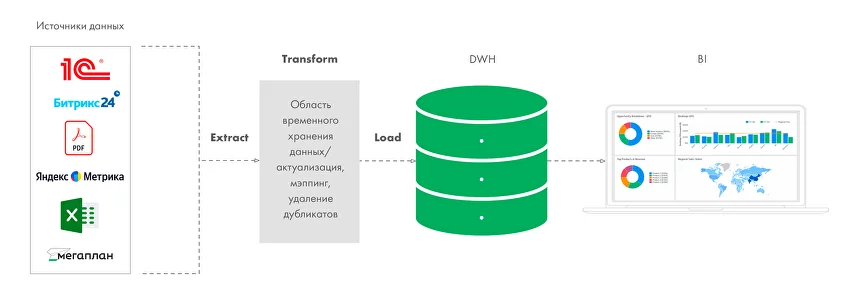
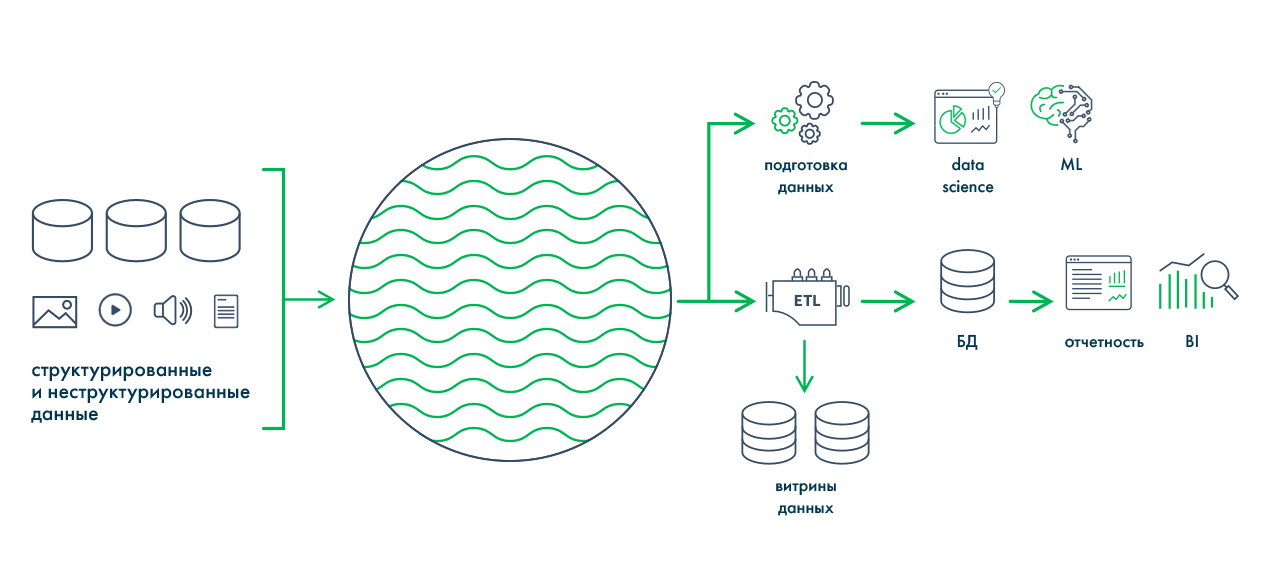
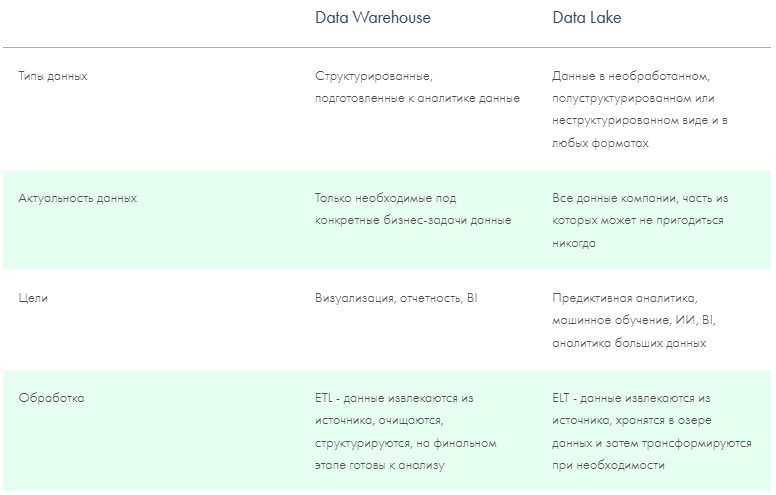
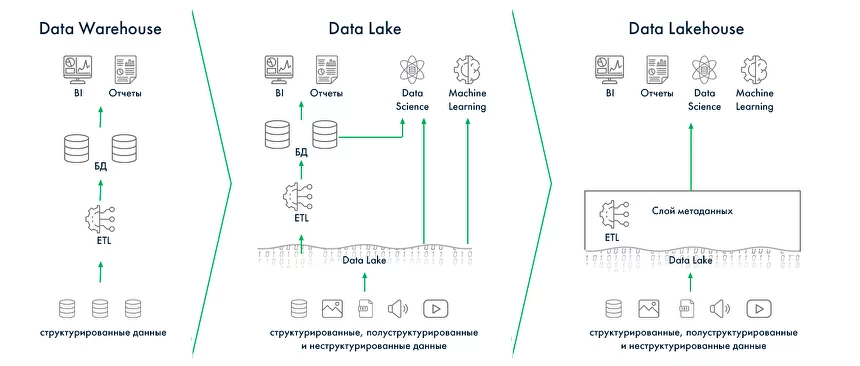
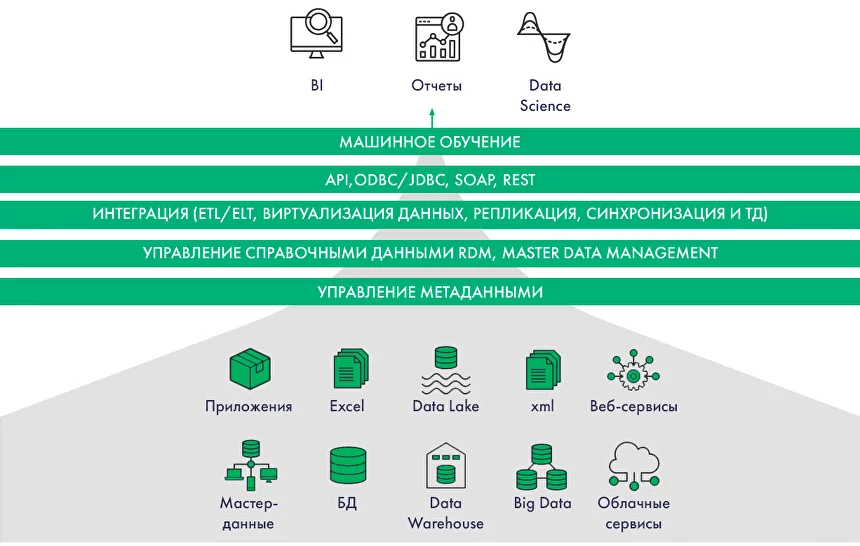
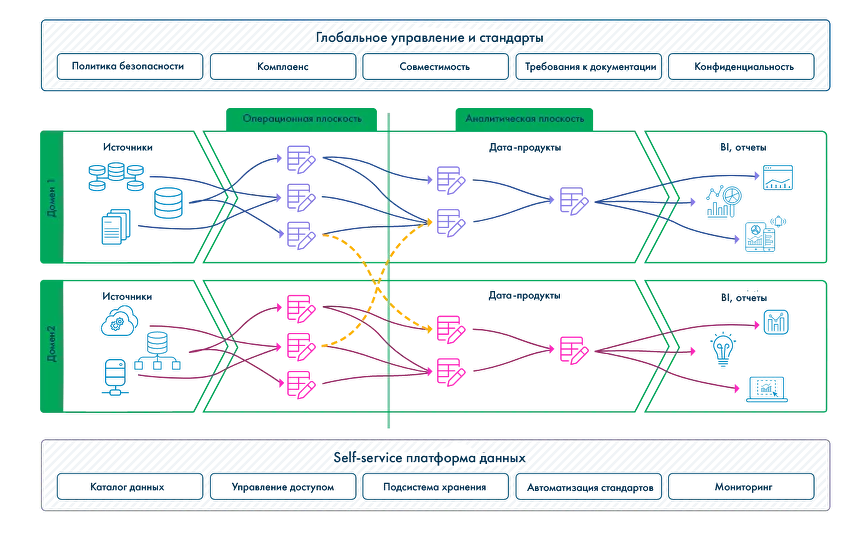
В 1959 году организация создала язык программирования COBOL, а в 1969 году опубликовала спецификацию языка для сетевой модели данных DBTG или модели данных CODASYL (CODASYL Data Model). Прототипом для этих первых стандартов БД стала разработка в 1963 году компьютерным подразделением General Electric сетевой базы данных Integrated Data Store (IDS). Одновременно в 1960-х появляется концепция информационной экономики и прототипы BI — системы для принятия решений на основе необработанных данных. В 1966 году для космической программы Аполлон компанией IBM была разработана первая промышленная СУБД — иерархическая система IMS (Information Management System), в задачу которой входила обработка спецификаций изделий для ракетоносителя «Сатурн-5» и шаттла «Аполлон». Ранее разработанные модели данных было сложно поддерживать, и доктор компьютерных наук Эдгар Франк «Тед» Кодд начинает работу над теорией хранения данных, чтобы упростить этот процесс. В 1970 году он издает работу «A Relational Model of Data for Large Shared Data Banks» («Реляционная модель данных для больших общих банков данных»). Работа Кодда стала основой для появления реляционной модели данных, а также вдохновила его коллег из IBM на создание языка программирования SEQUEL (Structured English Query Language), ставшего в дальнейшем SQL. В 1975 году выдвинут проект трехуровневой архитектуры ANSI-SPARC для построения СУБД, цель которой заключается в отделении пользовательского представления базы данных от ее физического представления. Годом позже разработана ER-модель данных (Entity-Relationship model), выделяющая ключевые сущности и обозначающая связи, которые могут устанавливаться между этими сущностями. В 1979 году выпущена первая версия РСУБД (реляционная система управления базами данных) Oracle Database на базе SQL, а в 1980 — СУБД dBASE, ставшая самой популярной среди всех существовавших в то время продуктов. Дальнейшее развитие реляционной модели и появление на рынке нескольких вариантов СУБД привело к необходимости разработки стандартов СУБД. Эдгар Кодд публикует знаменитые 12 правил Кодда, которым должна соответствовать каждая реляционная система управления базами данных. В 1986 Американский национальный институт стандартов представил первую версию стандарта языка SQL, а в 1987 году принят первый международный стандарт языка SQL — ICO SQL-87. В Калифорнийском университете стартует некоммерческий проект POSTGRES по созданию одноименной СУБД для исследовательских и производственных задач: анализа финансовых данных, мониторинга работы реактивных двигателей, хранения данных медицинских учреждений, географических информационных систем и других. Параллельно IBM разрабатывает семейство продуктов для управления данными DB2 (РСУБД IBM Database 2), которые предлагают удобный интерфейс для заполнения данных и встроенные средства для генерации отчетов. Компания Sybase начинает комплектовать интеллектуальные рабочие станции Sun Microsystems или Apollo Computer с серверами баз данных. Множится количество ПК и локальных сетей, появляется необходимость разработки методов объединения, загрузки и извлечения данных для СУБД, согласования форматов хранения данных. В этот период зарождается концепция хранилища данных, отдельной БД, изолированной от производственных систем, использование которой снижает нагрузку на операционные базы данных. В моделировании данных для таких БД начинают использовать схему звезды и снежинки. Появляется термин OLTP — Online Transaction Processing, обработка транзакций (последовательных операций с БД) в реальном времени. В то же время Ховард Дреснер, позднее ставший аналитиком Gartner, вводит термин Business Intelligence как «концепции и методы для улучшения принятия бизнес-решений с использованием систем на основе бизнес-данных». В 1991 году американский ученый Билл Инмон публикует книгу «Building the Data Warehouse» и вводит в обиход концепцию DWH как централизованного хранилища всех данных компании, разработка которого начинается с создания нормализованной модели данных. Антагонистом теории Инмона становится Ральф Кимбалл, использующий подход «снизу вверх», при котором создаются отдельные витрины, направленные на решение конкретных бизнес-задач и согласованные между собой на уровне размерностей в концептуальное хранилище данных. Идея Кимбалла направлена на денормализацию структуры хранилища и упрощения анализа для бизнес-пользователей. Концепции Инмона и Кимбалла широко используются и сегодня, при чем часто параллельно. В 1993 году уже известный Эдгар Кодд предлагает «12 правил аналитической обработки в реальном времени», так появляется OLAP (OnLine Analytical Processing) — технология интерактивной аналитической обработки данных в реальном времени. В 1990–1991 Microsoft выпускает первые релизы реляционной SQL Server, которые сразу занимают лидирующие позиции на рынке СУБД. В 1994 году на основе некоммерческой СУБД Postgres с добавлением интерпретатора языка SQL появляется Postgres95 и начинает свой путь как open source проект. В 1996 году на ее базе была создана объектно-реляционная СУБД PostgreSQL. В двухтысячных для обозначения структурированных и неструктурированных данных огромных объёмов появляется понятие «большие данные» (Big Data). Началось создание высокомасштабируемых интернет-приложений, например поисковиков и сервисов электронной почты. В рамках этих проектов стали создаваться и использоваться нереляционные СУБД (NoSQL), позволяющие справиться с быстрым ростом объёма данных и нагрузки. Для решения проблемы вертикального масштабирования (когда при увеличении объемов данных необходимо добавлять ресурсы — память и диски) и параллельных вычислений компания Google предлагает модель распределенных вычислений MapReduce. В 2006 году на ее базе Дугом Каттингом создана основополагающая технология больших данных — распределенная файловая система Hadoop (HDFS). В то же время в 2000 году Дэном Линстедтом представлена модель проектирования корпоративных хранилищ данных Data Vault, а в 2009 Ларсом Рённбеком и Олле Регардтом — якорное моделирование (Anchor Modeling). В экосистему проектов Hadoop для упрощения работы с MapReduce входят фреймворки Apache Spark, Apache PySpark, СУБД Apache Hive с SQL-подобным языком запросов и Apache Pig. Появляется возможность обработки не только структурированных, но и неструктурированных данных, растут возможности масштабирования хранилищ. Эволюционируют и архитектуры, появляются Data Lake (озеро данных) и Data Fabric, более гибкие по сравнению с классическим DWH. В то же время на базе PostgreSQL с применением массово-параллельной архитектуры (MPP) спроектирована СУБД Greenplum. Компанией Яндекс разработаны первые прототипы колоночной аналитической СУБД ClickHouse. Растет экосистема Apache, появляются Apache Airflow, Kafka, Storm. В 2011–2014 появляется несколько облачных проприетарных распределённых хранилищ для аналитики, где данные разбиты на фрагменты и распределены по узлам (серверам). Хранилища Google BigQuery, Amazon Redshift, и Snowflake позволили увеличивать объем данных и требования к вычислениям без необходимости вертикального или горизонтального масштабирования инфраструктуры. В этот же период появляется тренд на перемещение инфраструктуры данных в облака, Data Science, машинное обучение. Сегодня в связи со стремительным ростом бизнеса появились новые потребности в упрощении хранения, управления и анализа данных. Потребовались решения, которые позволят внедрять ML и ИИ в бизнес-аналитику и управление данными, при этом данные станут одинаково доступны и data-сайентистам, и бизнес-аналитикам. В связи с этим разработаны новые гибридные концепции хранилищ: Data Lakehouse, совмещающая преимущества озера данных и хранилища данных, и децентрализованная Data Mesh. Итак, в 1980–1990 DWH стали ответом на растущие потребности в аналитике данных и позволили обойти ограничения простых баз данных, предназначенных для хранения и доступа к определенной информации: Со временем рост объема генерируемой информации, поиск более гибких решений и масштабируемых технологий привели к эволюции архитектур данных от Data Lake и Data Fabric до гибких, гибридных Data Lakehouse и Mesh. Расскажем про каждую подробнее. Одними из основных процессов в управлении хранилищами данных являются: Эти процессы включают в себя получение данных из разрозненных внутренних и внешних источников, их оптимизацию, трансформацию, очистку и перемещение в репозиторий. При внедрении ETL-процесса архитектура хранилища данных состоит из трёх компонентов: DWH — это централизованный репозиторий для хранения и дальнейшего анализа структурированных данных. Корпоративное хранилище данных DWH позволяет актуализировать, нормализовать, обогатить данные и объединить их из различных информационных систем, таблиц и других внешних источников в единую структуру. В итоге дальнейшая подготовка данных не требуется, что значительно упрощает доступ к этим данным аналитикам и бизнес-пользователям. В корпоративных хранилищах архивные и исторические данные за разные периоды хранятся в формате, подходящем для анализа трендов во времени. Появление концепции Big Data, рост объема информации и необходимость обрабатывать не только структурированные, но и неструктурированные данные, повлияли и на способы обработки данных, стал развиваться ELT-подход. В отличие от ETL, в ELT-процессе данные сначала извлекаются в «сыром» виде, затем загружаются в хранилище Data Lake, а после уже в хранилище преобразуются в необходимый формат. Data Lake — озеро данных, хранилище, в которое поступают непрерывные потоки структурированных, полуструктурированных и неструктурированных «больших данных». Неструктурированные данные — это данные, в которых отсутствует формат и упорядоченность: текстовые документы, электронные письма, изображения, видео, посты в соцсетях, показания датчиков, файлы логов, данные GPS и т. д. Такой поход позволяет использовать данные не только для бизнес-аналитики, но и для инструментов искусственного интеллекта или машинного обучения. Озеро позволяет анализировать более широкий спектр данных новыми способами, чтобы получить ранее недоступные бизнес-инсайты. По сравнению с DWH, архитектура Data Lake при работе с большими объемами данных (массивы свыше 150 Гб в сутки) обеспечивает более гибкую масштабируемость, высокую производительность и низкую стоимость поддержки. Data Lake строят на базе распределенных файловых систем (DFS), фреймворков обработки Hadoop и Spark, форматов хранения данных Apache Parquet или Avro, объектных хранилищ (Apache Ozon) баз данных NoSQL и других open-source инструментов. Некоторые крупные компании с распределенными и разветвленными структурами бизнеса используют и DWH, и Data Lake, в зависимости от задач в области управления данными. Если в компании не планируются проекты аналитики Big Data, Natural Language Processing (NLP), ML или ИИ, внедрение Data Lake может быть нецелесообразным. Для работы с данными в озере необходимо уметь взаимодействовать с его компонентами. Для этого нужны навыки Data Science, Data Develop, бизнес-аналитики, инженерии данных, иначе огромные объемы данных рискуют превратиться в неуправляемые и недоступные для анализа потоки информации. Кроме того, в Data Lake отсутствуют некоторые функции, необходимые для операционной аналитики: поддержка транзакций, выполнение схемы, аудит операций. Все эти факторы вынуждают искать компромисс — архитектуру данных, предоставляющую возможности хранения различных типов данных и при этом простой доступ к ним для отчетности. История Lakehouse начинается с предложенной компанией Databricks многоуровневой архитектуры Medallion Lakehouse, которая описывает преобразование данных от исходной формы к структурированной для бизнес-аналитики. Lakehouse совмещает гибкость озер с четкой структурой классических хранилищ. Поверх Data Lake развертывают Apache CarbonData, Apache Iceberg, Open Delta, Apache Hudi, которые обеспечивают дополнительный слой для управления метаданными и реализации транзакций. Такая концепция позволяет использовать только один репозиторий, где не только располагаются все типы данных: структурированные, полуструктурированные и неструктурированные — но и выполняются все запросы и отчеты. Хранилище Lakehouse предлагает более широкие возможности для аналитики Big Data, при этом остается управляемым: Концепция Data Lakehouse является относительно новой, и ее потенциал и возможности еще только изучаются. Это сложная система, которую необходимо создавать с нуля под нужды конкретного бизнеса. Концепция Data Fabric развивалась параллельно архитектуре Lakehouse и была призвана обойти ограничения, связанные с длительностью и сложностью поиска, интеграции и аналитики больших объемов разрозненных и разноформатных данных. Data Fabric — дополнительный слой виртуализации данных, экосистема, состоящая из технологий обработки данных в реальном времени, API-интерфейсов, MDM (Master Data Manegement), семантических сетей (Knowledge Graph), инструментов искусственного интеллекта и машинного обучения (ML) и методик Data Governance. Хранилище при этом представляет собой единое информационное пространство с настроенной сквозной интеграцией на базе микросервисной архитектуры, где для построения и оптимизации алгоритмов управления данными используется машинное обучение. Для получения информации о бизнес-процессах активно используются метаданные — «данные о данных», набор описаний и свойств данных. Обычно, подход Data Fabric реализуется с внедрением готовых коммерческих платформ данных, например, Arenadata EDP (Enterprise Data Platform). Data Fabric упрощает доступ к данным и управление ими из различных источников, независимо от их местоположения или формата. Организационный фреймворк Data Mesh отличается от перечисленных выше архитектур. Концепция Data Mesh сфокусирована скорее на управлении данными (Data Governance) и повышение их качества, нежели на технические особенности построения хранилища. Идеи Data Warehouse и Data Lake основаны на централизованности данных: из объединении в центральном репозитории, которое принадлежит и контролируется как правило data-инженерами и ИТ-службой. Это затрудняет демократизацию данных для анализа — их доступность для всех бизнес-пользователей. К тому же команда управления хранилищем обычно малочисленная, а значит при росте объемов, количества источников и типов данных их обработка становится все сложнее и длительнее, что сказывается на качестве. Data Mesh призвана решить эти проблемы, так как основана на противоположной идее децентрализации данных — их распределении и владении функциональными подразделениями компании (доменам), такими как продажи, производство, финансы. К каждому домену прикреплена собственная ИТ-команда, которая работает только с принадлежащими им данными. Инфраструктура данных выстроена таким образом, чтобы хранилище представляло собой self-serve платформу, где каждый специалист доменной команды может легко самостоятельно работать с данными. Конечный результат работы каждого домена называется дата-продукт и имеет собственные стандарты, метрики, четкую бизнес-цель, при этом доступен и понятен для других доменов. При таком подходе данные, команда и инфраструктура свободно масштабируются, при этом вся компания получает стандартизированный и унифицированный опыт работы с данными. Концепция Data Mesh подходит только для крупных корпораций, которые работают с действительно большими объемами данных, и предполагает глобальное изменение в организационной структуре, изменения в бизнес-процессах, появление новых функциональных ролей.
Итак, мы рассмотрели основные вехи развития хранилищ данных и эволюцию архитектур, которые изменялись в соответствии с растущими требованиями бизнес-среды. Для целей регулярной отчетности и бизнес-аналитики отлично подойдет классическое хранилище данных (DWH). Оно помогает объединить и привести к единому формату данные из информационных систем, баз данных и других источников: CRM, ERP, систем бухгалтерского учета, кассовых систем. Благодаря своей структурированности и оптимизации данных, КХД позволяет получить быстрый доступ к большим объемам информации без значительного влияния на производительность информационных систем и оперативных баз данных. Data Lake — метод хранения и обработки «больших данных». Сбор структурированных и неструктурированных данных расширяет возможности для продвинутой аналитики или для использования инструментов машинного обучения. Озеро данных становится особенно ценным инструментом в крупных концернах с распределенной структурой, так как позволяет извлекать пользу из неочевидных источников информации. Концепции Data Lakehouse, Data Fabric и Data Mesh — следующие уровни работы с данными, которые охватывают не только технологический стек, но и организационную структуру компании. Реализация таких архитектур подразумевает полный пересмотр бизнес-процессов в компании, но при грамотном внедрении повышает эффективность работы всех подразделений. Окончательный выбор технологий работы с данными зависит от их текущего и потенциального объема, особенностей имеющейся инфраструктуры, масштаба команды, приоритетных бизнес-целей компании. В любом случае, лучшим решением станет начать с предпроектного обследования — оценки бизнес-процессов, источников данных, инфраструктуры компании.
Запишитесь на предпроектное обследование инфраструктуры обработки данных. Мы проведем аудит, разработаем требования к хранилищу данных под ваши уникальные задачи, рассчитаем стоимость его внедрения и поможем защитить проект.

1970–1980

1980–1990
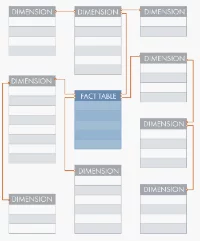
1990–2000

2000–2010
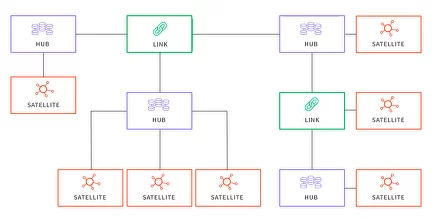
2010–2020
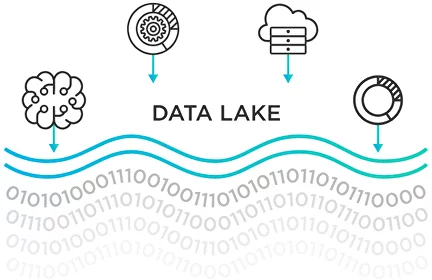
Настоящее время
***
Что такое Data Lake и чем отличается от Data Warehouse
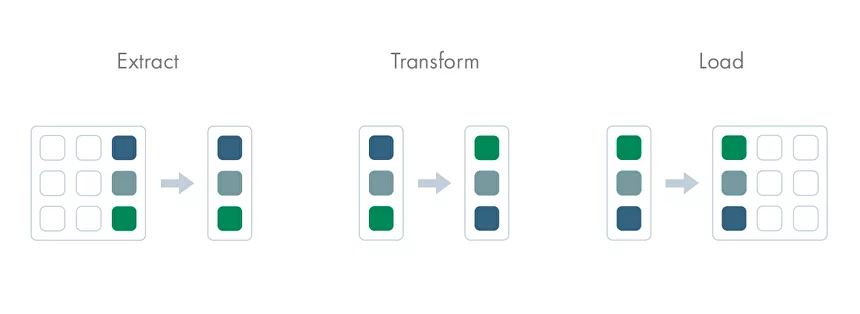

Data Lakehouse: объединение преимуществ Data Lake и DWH
Data Fabric — хранилище, усиленное ML
Децентрализация данных в Data Mesh
***
Хотите извлекать максимум пользы из данных?