Как работают рекомендательные системы в приложении ЯRUS

Что это такое, как она работает и как создавалась, расскажет руководитель технической дирекции проекта Дмитрий Илюхин.
— Привет, Дима. Давай сначала расскажем, что же такое ЯRUS?
— Привет. ЯRUS − это мобильное приложение-агрегатор, где собраны новости, видео, короткие ролики, музыка, пользовательские материалы и мероприятия со всей России. Однако наша главная цель не только собирать разнообразный контент на одной площадке, но и правильно показывать его пользователям.
С первого запуска приложения пользователем мы определяем его интересы, предлагая выбрать интересные темы в настройках аккаунта и во вкладке с новостями. Эти данные мы соотносим с группой других пользователей со схожими интересами и получаем выборку материалов для отображения в ленте. Проще говоря, наша рекомендательная система учитывает индивидуальные и общие интересы аудитории для формирования персонализированной выдачи.
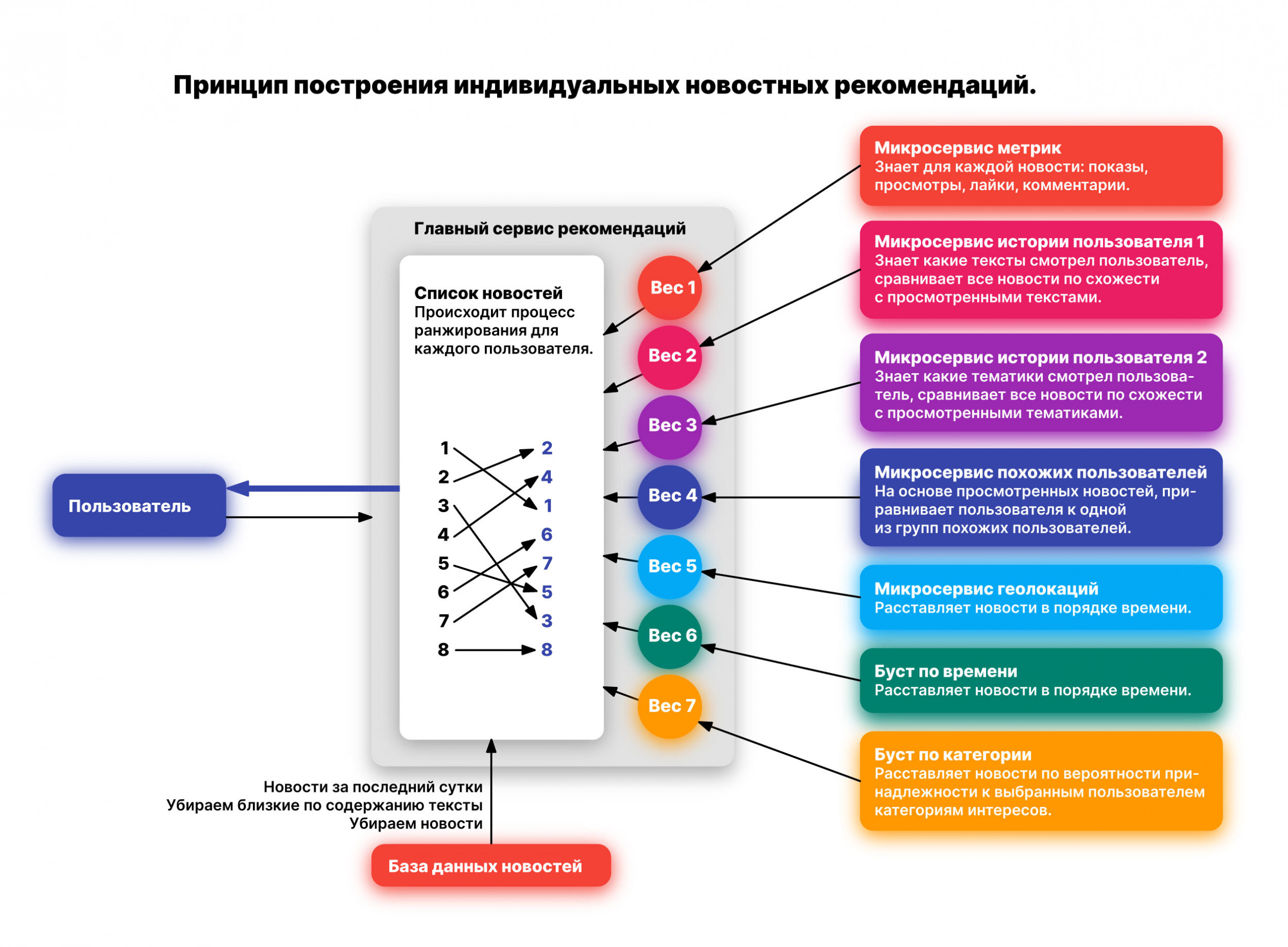
— Эта рекомендательная система работает по всему приложению? — Со всем текстовым контентом. Больше всего ее влияние заметно в разделе «Новости». Ежедневно во вкладке с новостями собирается около 56 000 записей из 10 000 источников, поэтому без фильтрации контента здесь не обойтись. Этим также занимается наша система, которая на основе нескольких критериев вычищает весь поток от информационного шума. — Что это за критерии? — Для начала происходит выборка по объему текста. Если текст состоит из 2-3 предложений или только из картинки, мы определяем его как некачественный и не учитываем в формировании выдачи. Дальше мы смотрим на язык и убираем все не русскоязычные материалы. Следующий шаг − фильтруем новости, где много коротких слов. Обычно такие материалы состоят только из перечислений, нам же нужны литературные и цельные тексты. Дополнительным критерием мы выделили сборку новостного сюжета. Несколько источников часто переписывают одно и то же событие разными словами и, чтобы не выдавать много одинаковых новостей читателям, система группирует похожие тексты в подборку. Из этой подборки выбирается одна новость в зависимости от ее объема и времени публикации − обычно это самая крупная или свежая по времени запись. Проходя через эти этапы, мы формируем единую базу из неповторяющихся новостей. — Что дальше происходит с этой базой? — Дальше мы пропускаем ее через алгоритмы для определения веса каждого материала. На всех этапах первоначальная выборка новостей перестраивается, чтобы конечный пользователь увидел только интересный ему контент. — Расскажи подробнее об этих этапах. — Всего их семь. На первом происходит перестройка списка по базовым метаданным: количество показов (сколько раз эта новость появилась в ленте), просмотров (сколько раз ее открыли), эмоций и комментариев. Если бы мы формировали пользовательскую ленту только по этому критерию, в топ попали бы самые обсуждаемые и просматриваемые новости. Однако дальше разные алгоритмы уже начинают персонализировать ленту и смотрят на действия пользователя в приложении: один алгоритм учитывает просмотренные посты, а второй — тематики. В приложении на данный момент выделено около 100 тем, по которым автоматически происходит разделение новостей. Если человек часто открывает посты с итогами футбольных матчей, то, скорее всего, ему будет интересна вся околофутбольная тема, поэтому он будет видеть подобные материалы чаще. Еще один алгоритм объединяет пользователей в группы по интересам и дополнительно сортирует первоначальный список новостей, но уже по запросам той или иной группы. Наши алгоритмы также могут учитывать время выхода материала и геолокацию пользователя. Свежие материалы встают выше по списку, но здесь также учитывается и местоположение человека − как далеко он находится от выпустившего новость СМИ. Многие источники в наших списках региональные и материалы, которые они публикуют, будут интересны только людям из этих регионов. Но, если местная газета города A разместила на сайте новость и она успела устареть, а газета города Б из того же региона написала что-то свежее, но по-прежнему затрагивающие интересы пользователя, мы покажем ему материалы из второго источника. Так мы стараемся выдерживать баланс между географией и временем выхода материала, чтобы люди получали актуальную информацию о происходящих вокруг событиях. Еще один немаловажный процесс — категоризация новостей. Мы обучили алгоритм на большом количестве текстов и категорий понимать, куда можно отнести ту или иную запись и теперь можем выдавать релевантные статьи по ключевым словам. Это также влияет на сортировку базового списка новостей перед итоговым формированием пользовательской ленты. Все эти шаги можно представить простой последовательностью: сбор новостей, их фильтрация и составление базы с неповторяющимися записями, а после — персонализация этой базы в зависимости от пользовательских интересов и группы, к которой он принадлежит. — А выдача новостей как-то меняется со временем или зависит от первых действий пользователя? — Алгоритмы постоянно сортируют новости. Чем больше времени проводит человек в приложении и чем больше совершает действий внутри, тем точнее становится его индивидуальная выборка. Например, я в последнее время интересовался конференцией Apple. Алгоритмы это поняли и теперь чаще выдают новости по теме. Говоря об интересах, нужно также рассказать о нашей системе оценивания материала. Мы не стали использовать привычные лайк-дизлайк и добавили пять эмоций. Все эти реакции мы тоже оцениваем как интерес. Даже если вы поставили посту злобную эмоцию, алгоритм продолжит подмешивать в ленту похожие материалы. Если бы мы сразу убирали из выборки посты со злыми и грустными смайликами, пользователи могли бы пропустить что-то интересное для них в следующий раз. Иначе работают рекомендации «холодного старта» — это когда человек только зашел в приложение и первый раз открыл ленту. Мы изначально не знаем, что ему может понравиться, поэтому определяем его к большинству. То есть ранжирование выстраивается в зависимости от интересов остальных пользователей и в топ попадают посещаемые и свежие новости. — Сколько времени у вас ушло на разработку такой системы? — В разработке первой модели участвовали люди, которые уже были в теме и работали с похожими алгоритмами, поэтому на написание технической базы у нас ушло примерно два месяца. Большую часть времени заняло удаление лишнего мусора для категоризации тематик. Нам нужно было проанализировать огромное количество текстов и научиться автоматически приводить слова из них к начальной форме, чтобы потом точнее определять запросы пользователей. Через два месяца мы приступили к тестированию и настройке параметров, которые позже задавали бы вес новостям при их ранжировании. Сначала мы отдавали больший приоритет количеству просмотров и комментариев, но тогда обсуждаемые новости всегда оказывались наверху выдачи, забивая собой остальные материалы. Заметив проблему, мы перераспределили приоритеты и дали больше значимости остальным алгоритмам, чтобы они разбавляли ленту. Еще мы поняли, что не стоит делать акцент на геолокации. Если человек сейчас находится в Рязани, нам не следует выдавать ему только региональные новости, иначе мы не поймем его интересы. — Что планируете сделать в будущем? — Мы уже научились определять, откуда к нам пришел пользователь, и хотим использовать эти данные для улучшения персонализации ленты. Например, человек перешел в приложение с автомобильного сайта. Зная эту информацию, мы можем подстроить алгоритм, чтобы выдавать рекомендации по автомобильной тематике. Еще хотим доработать систему отметок неинтересных материалов, потому что сейчас она работает не в полной мере. До конца года мы также планируем расширить рекомендательную систему и на видео контент. Таким образом, скоро в ленте люди увидят не только интересные для себя новости, но и ролики. О том, как мы это реализуем, я расскажу уже в следующий раз. — Спасибо тебе за интервью. Жди нас скоро за подробностями о рекомендательной системе для видео. — Приходите, буду рад рассказать о работе моего отдела.