Как извлечь текст и изображения из PDF в Java
Одним из недостатков PDF-файлов является то, что пользователи не могут напрямую извлекать текст или изображения из документа, что создает проблемы для повторного использования полезной информации. В данной статье показано, как извлечь текст и изображения из PDF-документа с помощью Free Spire.PDF for Java.
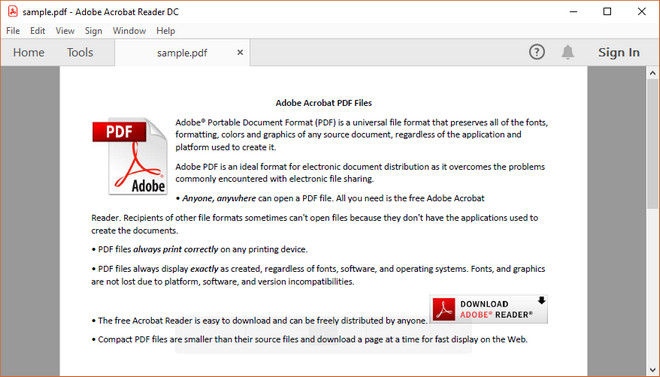
Ниже приведен снимок экрана примера PDF-документа.
Установка Spire.Pdf.jar
Если вы создали
Maven-проект, вы можете легко импортировать jar в свое приложение, используя
следующие конфигурации. Для проектов, не использующих Maven, загрузите jar-файл
по этой
ссылке и добавьте его в качестве зависимости в свое приложение.
import java.io.FileWriter; import java.io.IOException; public class ExtractText { public static void main(String[] args) { //create a PdfDocument instance PdfDocument doc = new PdfDocument(); //load a sample PDF file doc.loadFromFile("C:\Users\Administrator\Desktop\sample.pdf"); //create a StringBuilder instance StringBuilder sb = new StringBuilder(); //loop through PDF pages and extract text of each page PdfPageBase page; for (int i = 0; i < doc.getPages().getCount(); i++) { page = doc.getPages().get(i); sb.append(page.extractText(true)); } FileWriter writer; try { //write text into a .txt file writer = new FileWriter("C:\Users\Administrator\Desktop\ExtractText.txt"); writer.write(sb.toString()); writer.flush(); } catch (IOException e) { e.printStackTrace(); } doc.close(); } } import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; public class ExtractImage { public static void main(String[] args) throws IOException { //create a PdfDocment object PdfDocument doc = new PdfDocument(); //load a PDF file doc.loadFromFile("C:\Users\Administrator\Desktop\sample.pdf"); //declare an int variable int index = 0; //loop through the pages for (int i = 0; i < doc.getPages().getCount(); i++) { //extract images from a particular page for (BufferedImage image : doc.getPages().get(i).extractImages()) { //specify the file path and name File output = new File("C:\Users\Administrator\Desktop\ExtractedImages\" + String.format("Image_%d.png", index++)); //save image as .png file ImageIO.write(image, «PNG», output); } } } }
Пример 1. Извлечение текста из PDF

Пример 2. Извлечение изображений из PDF