

Системный подход к подбору ключевых слов для Яндекс Директ и Google Adwords
Прочитав статью вы сможете подобрать ключевые слова для систем Яндекс Директ и Google Adwords на базовом уровне.
Какой раздел знаний охватывает статья:
Сбор информации → Стратегия → Первичная настройка аналитики → Сбор ключевых слов → Сортировка ключевых слов → Разработка объявлений → Разработка рекламных кампаний → Анализ данных → Оптимизация → Масштабирование → Поддержка
Каких тем коснемся: карта покрытия, перемножение, парсинг, wordstat.yandex.ru
Вы могли заметить, что перед сбором ключевых слов стоит еще 3 пункта, так как материалов по ним у нас еще нету, то изложим их в тезисах:
- Вы должны понимать, кто ваш покупатель и какие запросы он будет вводить в поиск.
- Общие концепции стратегии можно почерпнуть из первой части статьи “Как бесплатно сделать лендинг за вечер?”
- Установите код Яндекс Метрики и Google Analytics себе на сайт, настройте цели
Статья подразумевает, что вы уже разбираетесь в понятиях: вордстат, показы, клики, минус-слова, кросс-минусовка, типы соответствий ключевых слова, частота слов, релевантность. А если и не разбираетесь, то cможете найти их в интернете.
Как выбрать ключевые слова? Существует много приемов и инструментов для сбора ключевых слов: выгрузка из счетчиков, сбор с сайтов конкурентов, генерация из YML, поиск похожих по ТОПу фраз, автоматический подбор фраз на основании вашего сайта в поисковой выдаче и другие. Мы поговорим об основных методах, а точнее о wordstat.yandex.ru.
Алгоритм
- Создаем таблицу Excel (советую использовать Google Docs, вот наш шаблон) и делаем в ней матрицу, как на скрине:
Для примера сделаем семантическое ядро для сайта schoolmasters.ru, который предлагает летнюю математическую школу в Болгарии.
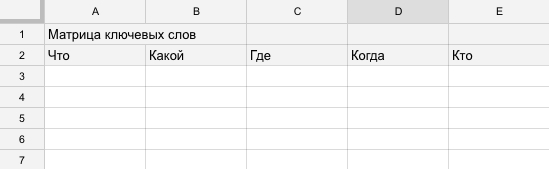
- Думаем, по каким бы запросам нас могли искать наши потенциальные клиенты, слова берем из головы и распределяем их по столбикам:
Яндекс различает части речи, поэтому «математика» и «математический», это 2 разных ключевых слова, но в то же время Яндекс не различает склонения и числа.
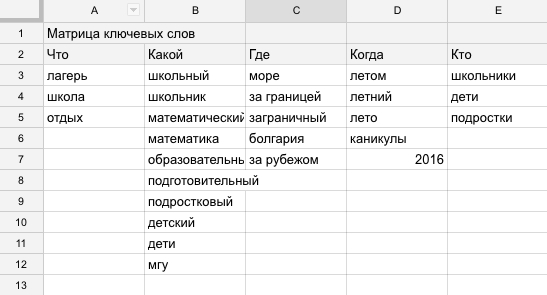 Расширяем матрицу новыми словами:
Расширяем матрицу новыми словами:
- ищем похожие слова на wordstat.yandex.ru в правом столбике
- добавляем имеющиеся слова в разных частях речи
- исследуем, по каким словам дают рекламу и находятся в ТОПе ваши конкуренты на сайте advse.ru
- добавляем специальные термины, жаргоны, которые можно найти на сайтах конкурентов и форумах
- схожие по ассоциациям слова на wordassociations.ru
Теоретический блок
Мы знаем, что такое ключевая фраза в wordstat, она имеет частоту (показы в месяц), это среднее количество запросов за последние 3 месяца и 1 месяц год назад. Все фразы ниже, это входящие запросы, то есть запросы, которые содержат фразу, которую мы ввели, в разных склонениях и числах. Так же вы можете изучить частоту вашего запроса в разрезе регионов и сезонности во вкладках «По регионам» и «История запросов».
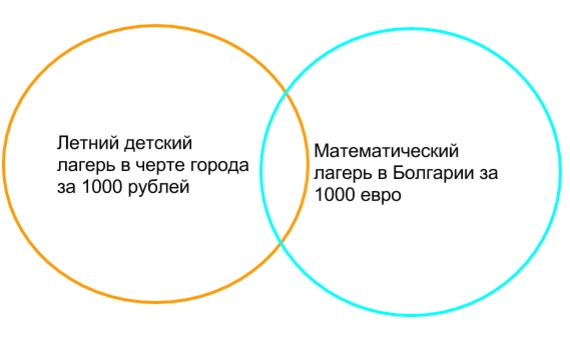
Рассматривайте ключевые слова, как сегменты одного бесконечного массива, из которого мы хотим выделить те сегменты, которые будут релевантны нашему сайту. Например, на картинке ниже, пересечение красного цвета содержит самые целевые запросы «математическая летняя школа», а зеленое пересечение «математическая школа» содержит запросы более широкого вида, а еще есть запрос «школа», который содержит 99% не релевантных для нас запросов.
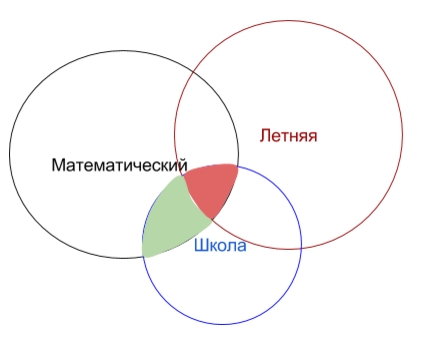
Так вот к чему я веду? Мы возьмем для ручной сортировки все входящие запросы фраз «математическая летняя школа» и «математическая школа», а «школа» не возьмем, так как мы не хотим сортировать 99% запросов, чтобы найти 1% своих.
Матрица нужна, как материал, для составления ключевых фраз (сегментов). Не стоит добавлять в матрицу все слова, которые только возможны. Например, мы не будем добавлять слова «2016», «купить», «погода», так как мы не берем для ручной сортировки сегмент «математическая летняя школа купить», он уже будет содержаться в сегменте «математическая летняя школа», как входящий запрос. Чтобы ориентировать в том, какие слова стоит добавлять в матрицу, а какие нет, нужен опыт.
Так же вы могли заметить, что сегменты «математическая летняя школа» и «математическая школа» пересекаются, следовательно, мы должны вычесть из запроса «математическая школа» слово «летний». Для этого существуют минус-слова, но об этом позже.
Я не могу описать весь процесс, так как нюансов бесконечно много, но могу подсказать вам ключевые точки, следуя которым вы будете двигаться в верном направлении.
- Составляем сегменты из матрицы. Открываем wordstat.yandex.ru и вводим первое слово из первого столбика «лагерь» - видим, что более 70-ти % входящих запросов нам не подходят. Попутно высматриваем новые ключевые слова и пополняем нашу матрицу, но учтите, что если вы добавляете новое хорошее слово, то оно может быть использовано в предыдущих сегментах.
Как определить ключевые слова, другими словами, что ищут пользователи, когда вводят конкретный запрос? Вбейте в Яндекс и посмотрите поисковую выдачу, как правило, на первых позициях содержится именно та информация, которая интересна пользователям.
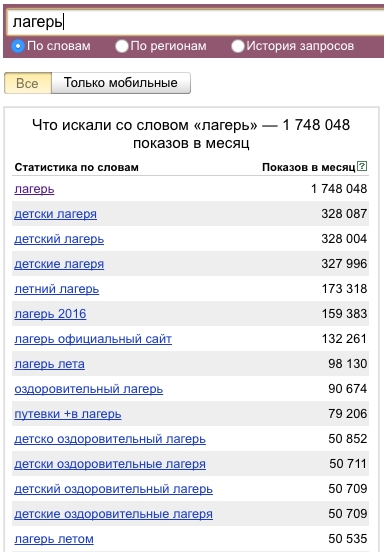
- Вы скажете, что аудитория, которая вводит «детский лагерь», могла бы заинтересоваться нашим предложением, но нет, потенциальных клиентов в этом сегменте не более 5%, следовательно, стоимость клиента будет такой высокой, что бы не сможем конкурировать с обычными детскими лагерями.
- Так как по запросу «лагерь» более 70% не релевантных ключевых слов, то мы начинаем усекать аудиторию, добавляя уточнения из других столбиков, например во фразе «лагерь математический» почти все внутренние запросы нам подходят, а значит добавляем их в сегменты для последующей обработки, такую операцию нам нужно проделать с каждым ключевым словом, идя от общего «лагерь» и сужая сегменты к частному «детский», «болгария».
Как правило в каждом сегменте есть слова, которые нам не подходят, например:
Мы добавляем эти слова в строку поиска с символом минус и снова нажимаем «Подобрать», чтобы получить тот же список ключевых слов, но уже без содержания минус-слов.
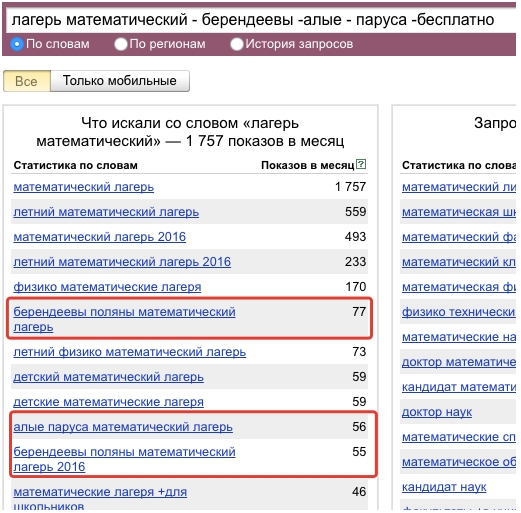
- Чтобы не запутаться, мы по-очередности ищем и добавляем сегменты ключевых слов в отдельное место справа от матрицы, как в шаблоне. К каждому сегменту добавляем минус-слова.
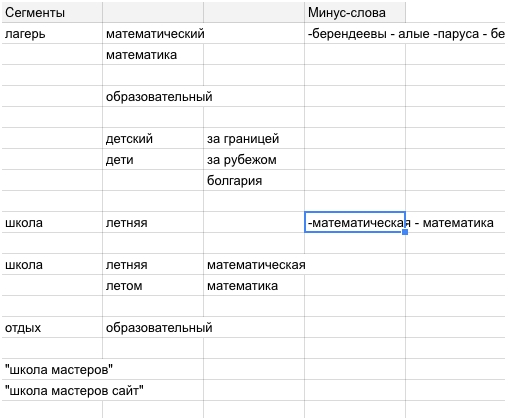 Помните про пересечение сегментов, на данном этапе нам нужно провести кросс-минусовку между сегментами.
Таким образом, получается карта охвата, смотря на нее, мы четко представляем по каким ключевым словам будут показываться наши объявления.
Помните про пересечение сегментов, на данном этапе нам нужно провести кросс-минусовку между сегментами.
Таким образом, получается карта охвата, смотря на нее, мы четко представляем по каким ключевым словам будут показываться наши объявления.
- Теперь нам нужно получить список ключевых слов из этой карты, для этого мы прибегнем к методу перемножения. Используем сервис py7.ru/tools/text/, но в нем нужно немного разобраться.
Суть метода перемножения ключевых в том, чтобы избежать ручной работы.
 В поле шаблон у нас сразу есть 4 переменные, если мы хотим перемножить 2 столбика, то нам нужно оставить только переменные %(a)s и %(b)s, а %(c)s и %(d)s удалить. Если мы хотим перемножить 3 столбика, то нужно удалить только %(d)s - количество переменных равно количество столбиков.
В поле шаблон у нас сразу есть 4 переменные, если мы хотим перемножить 2 столбика, то нам нужно оставить только переменные %(a)s и %(b)s, а %(c)s и %(d)s удалить. Если мы хотим перемножить 3 столбика, то нужно удалить только %(d)s - количество переменных равно количество столбиков.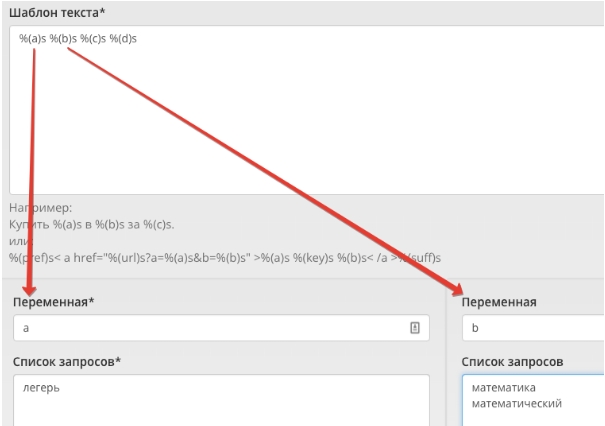 Нам нужно поочередно перемножить каждый сегмент, берем первый и распределяем слова по столбикам в сервисе py7.ru
Нам нужно поочередно перемножить каждый сегмент, берем первый и распределяем слова по столбикам в сервисе py7.ru Жмем кнопку «Генерация» и получаем результат:
лагерь математика
лагерь математический
Жмем кнопку «Генерация» и получаем результат:
лагерь математика
лагерь математический - Далее, на новом листе создаем столбики под каждый сегмент и в них распределяем ключевые слова после генерации.
Парсинг ключевых слов - сбор входящих запросов, аналогично тому, что мы введем ключевое слово в вордстат и скопируем все входящие запросы.
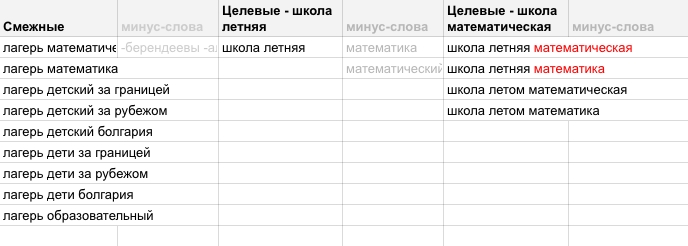 Вы можете заметить, что возле каждой группы у нас появился столбик «минус-слов», туда мы вручную переносим слова для кросс-минусовки наших сегментов и общие списки для каждого сегмента, например:
Вы можете заметить, что возле каждой группы у нас появился столбик «минус-слов», туда мы вручную переносим слова для кросс-минусовки наших сегментов и общие списки для каждого сегмента, например:
- Теперь нужно собрать входящие запросы (далее спарсить) для каждой группы, есть 3 варианта:
- вручную копировать из wordstat.yandex.ru
- использовать topvisor.ru, но придется вручную фильтровать и удалять минус-слова
- keycollector, несомненно лучший, но самый сложный вариант
 Обратите внимание, что мы выбираем параметр «все регионы», чтобы получить более усредненную статистику.
У нас выходит список входящих запросов на нескольких страницах, мы копируем запросы до значения показов в месяц 50
Обратите внимание, что мы выбираем параметр «все регионы», чтобы получить более усредненную статистику.
У нас выходит список входящих запросов на нескольких страницах, мы копируем запросы до значения показов в месяц 50
 И вставляем в нашу таблицу на тот же лист под сегментом.
И вставляем в нашу таблицу на тот же лист под сегментом.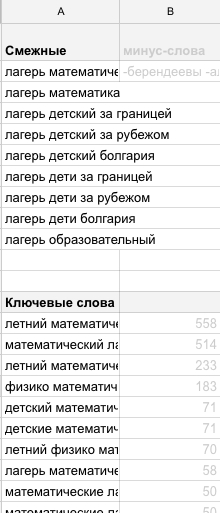 Почему до 50 показов в месяц, ведь все только что и говорят о количестве ключевых слов? Количество ключевых слов не является показателем качества рекламной кампании, чаще, это говорит о некомпетентности и непонимания механизмов работы контекстной рекламы.
Какой толк от низкочастотных запросов?
Почему до 50 показов в месяц, ведь все только что и говорят о количестве ключевых слов? Количество ключевых слов не является показателем качества рекламной кампании, чаще, это говорит о некомпетентности и непонимания механизмов работы контекстной рекламы.
Какой толк от низкочастотных запросов?
- Мы делаем для каждого ключевого слова свое объявление, что немного повышает его CTR, но и повышает объем работы, что не всегда оправдывается экономически.
- Чем больше ключевых слов, тем больше сегментов для аналитических систем, а значит больше возможностей для оптимизации, но тогда должно быть много статистики.
- Снижение стоимости клика, это миф, ниже 50-ти запросов можно снизить только в редки случаях.
Все ли вам понятно? Есть вопросы? Стоит ли нам запилить видео на эту тему?


