

Внутренние механизмы ТСР, влияющие на скорость загрузки — часть 1
IP (Internet Protocol) обеспечивает маршрутизацию между хостами и адресацию. TCP (Transmission Control Protocol) обеспечивает абстракцию, в которой сеть надежно работает по ненадежному по своей сути каналу.
Протоколы TCP/IP были предложены Винтом Серфом и Бобом Каном в статье «Протокол связи для сети на основе пакетов», опубликованной в 1974 году. Исходное предложение, зарегистрированное как RFC 675, было несколько раз отредактировано и в 1981 году 4-я версия спецификации TCP/IP была опубликована как два разных RFC:
- RFC 791 – Internet Protocol
- RFC 793 – Transmission Control Protocol
TCP обеспечивает нужную абстракцию сетевых соединений, чтобы приложениям не пришлось решать различные связанные с этим задачи, такие как: повторная передача потерянных данных, доставка данных в определенном порядке, целостность данных и тому подобное. Когда вы работаете с потоком TCP, вы знаете, что отправленные байты будут идентичны полученным, и что они придут в одинаковом порядке. Можно сказать, что TCP больше «заточен» на корректность доставки данных, а не на скорость. Этот факт создает ряд проблем, когда дело доходит до оптимизации производительности сайтов.
Стандарт НТТР не требует использования именно TCP как транспортного протокола. Если мы захотим, мы можем передавать НТТР через датаграммный сокет (UDP – User Datagram Protocol) или через любой другой. Но на практике весь НТТР трафик передается через TCP, благодаря удобству последнего.
Поэтому необходимо понимать некоторые внутренние механизмы TCP, чтобы оптимизировать сайты. Скорее всего, вы не будете работать с сокетами TCP напрямую в своем приложении, но некоторые ваши решения в части проектирования приложения будут диктовать производительность TCP, через который будет работать ваше приложение.
Тройное рукопожатие
Все TCP-соединения начинаются с тройного рукопожатия (рис. 1). До того как клиент и сервер могут обменяться любыми данными приложения, они должны «договориться» о начальном числе последовательности пакетов, а также о ряде других переменных, связанных с этим соединением. Числа последовательностей выбираются случайно на обоих сторонах ради безопасности.SYN
Клиент выбирает случайное число Х и отправляет SYN-пакет, который может также содержать дополнительные флаги TCP и значения опций.SYN ACK
Сервер выбирает свое собственное случайное число Y, прибавляет 1 к значению Х, добавляет свои флаги и опции и отправляет ответ.АСК
Клиент прибавляет 1 к значениям Х и Y и завершает хэндшейк, отправляя АСК-пакет.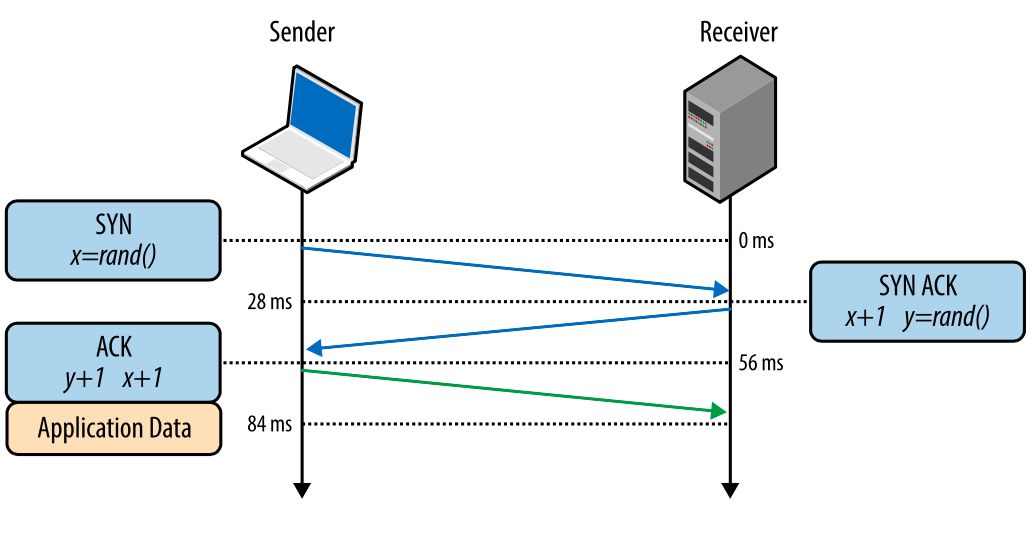 Рис. 1. Тройное рукопожатие.
Рис. 1. Тройное рукопожатие.После того как хэндшейк совершен, может быть начат обмен данными. Клиент может отправить пакет данных сразу после АСК-пакета, сервер должен дождаться АСК-пакета, чтобы начать отправлять данные. Этот процесс происходит при каждом TCP-соединении и представляет серьезную сложность плане производительности сайтов. Ведь каждое новое соединение означает некоторую сетевую задержку.
Например, если клиент в Нью-Йорке, сервер – в Лондоне, и мы создаем новое TCP-соединение, это займет 56 миллисекунд. 28 миллисекунд, чтобы пакет прошел в одном направлении и столько же, чтобы вернуться в Нью-Йорк. Ширина канала не играет здесь никакой роли. Создание TCP-соединений оказывается «дорогим удовольствием», поэтому повторное использование соединений является важной возможностью оптимизации любых приложений, работающих по TCP.
TCP Fast Open (TFO)
Загрузка страницы может означать скачивание сотен ее составляющих с разных хостов. Это может потребовать создания браузером десятков новых TCP-соединений, каждое из которых будет давать задержку из-за хэндшейка. Стоит ли говорить, что это может ухудшить скорость загрузки такой страницы, особенно для мобильных пользователей.TCP Fast Open (TFO) – это механизм, который позволяет снизить задержку за счет того, что позволяет отправку данных внутри SYN-пакета. Однако и у него есть свои ограничения: в частности, на максимальный размер данных внутри SYN-пакета. Кроме того, только некоторые типы HTTP-запросов могут использовать TFO, и это работает только для повторных соединений, поскольку использует cookie-файл.
Использование TFO требует явной поддержки этого механизма на клиенте, сервере и в приложении. Это работает на сервере с ядром Linux версии 3.7 и выше и с совместимым клиентом (Linux, iOS9 и выше, OSX 10.11 и выше), а также потребуется включить соответствующие флаги сокетов внутри приложения.
Специалисты компании Google определили, что TFO может снизить сетевую задержку при HTTP-запросах на 15%, ускорить загрузку страниц на 10% в среднем и в отдельных случаях – до 40%.
Контроль за перегрузкой
В начале 1984 года Джон Нейгл описал состояние сети, названное им как «коллапс перегрузки», которое может сформироваться в любой сети, где ширина каналов между узлами неодинакова.Когда круговая задержка (время прохождения пакетов «туда-обратно») превосходит максимальный интервал повторной передачи, хосты начинают отправлять копии одних и тех же датаграмм в сеть. Это приведет к тому, что буферы будут забиты и пакеты будут теряться. В итоге хосты будут слать пакеты по нескольку раз, и спустя несколько попыток пакеты будут достигать цели. Это называется «коллапсом перегрузки».
Нейгл показал, что коллапс перегрузки не представлял в то время проблемы для ARPANETN, поскольку у узлов была одинаковая ширина каналов, а у бэкбона (высокоскоростной магистрали) была избыточная пропускная способность. Однако это уже давно не так в современном интернете. Еще в 1986 году, когда число узлов в сети превысило 5000, произошла серия коллапсов перегрузки. В некоторых случаях это привело к тому, что скорость работы сети падала в 1000 раз, что означало фактическую неработоспособность.
Чтобы справиться с этой проблемой, в TCP были применены несколько механизмов: контроль потока, контроль перегрузки, предотвращение перегрузки. Они определяли скорость, с которой данные могут передаваться в обоих направлениях.
Контроль потока
Контроль потока предотвращает отправку слишком большого количества данных получателю, которые он не сможет обработать. Чтобы этого не происходило, каждая сторона TCP-соединения сообщает размер доступного места в буфере для поступающих данных. Этот параметр — «окно приема» (receive window – rwnd).Когда устанавливается соединение, обе стороны задают свои значения rwn на основании своих системных значений по умолчанию. Открытие типичной страницы в интернете будет означать отправку большого количества данных от сервера клиенту, таким образом, окно приема клиента будет главным ограничителем. Однако, если клиент отправляет много данных на сервер, например, загружая туда видео, тогда ограничивающим фактором будет окно приема сервера.
Если по каким-то причинам одна сторона не может справиться с поступающим потоком данных, она должна сообщить уменьшенное значение своего окна приема. Если окно приема достигает значения 0, это служит сигналом отправителю, что не нужно более отправлять данные, пока буфер получателя не будет очищен на уровне приложения. Эта последовательность повторяется постоянно в каждом TCP-соединении: каждый АСК-пакет несет в себе свежее значение rwnd для обеих сторон, позволяя им динамически корректировать скорость потока данных в соответствии с возможностями получателя и отправителя.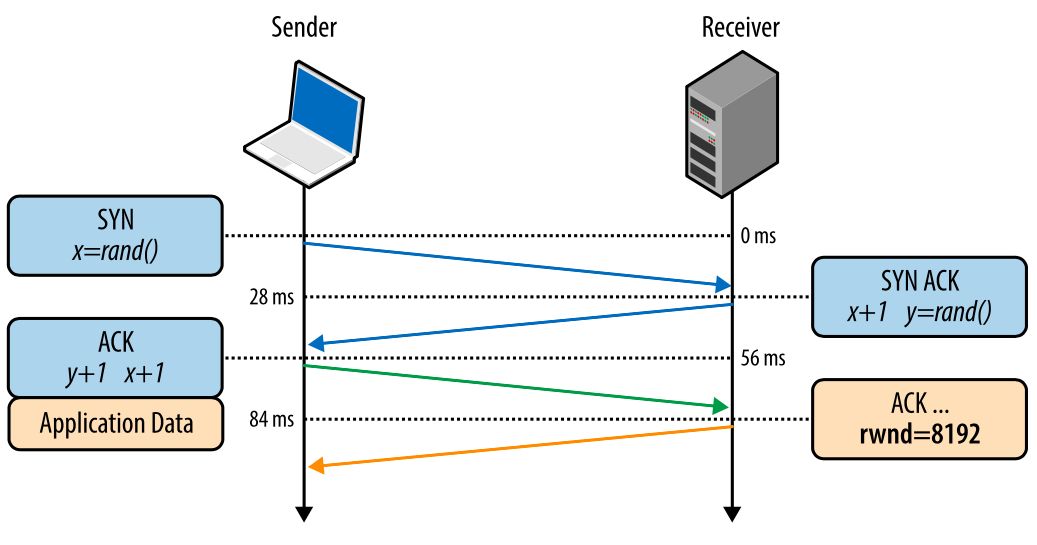 Рис. 2. Передача значения окна приема.
Рис. 2. Передача значения окна приема.
Масштабирование окна (RFC 1323)
Исходная спецификация TCP ограничивала 16-ю битами размер передаваемого значения окна приема. Это серьезно ограничило его сверху, поскольку окно приема не могло быть более 2^16 или 65 535 байт. Оказалось, что это зачастую недостаточно для оптимальной производительности, особенно в сетях с большим «произведением ширины канала на задержку» (BDP – bandwidth-delay product).Чтобы справиться с этой проблемой в RFC 1323 была введена опция масштабирования TCP-окна, которая позволяла увеличить размер окна приема с 65 535 байт до 1 гигабайта. Параметр масштабирования окна передается при тройном рукопожатии и представляет количество бит для сдвига влево 16-битного размера окна приема в следующих АСК-пакетах.
Сегодня масштабирование окна приема включено по умолчанию на всех основных платформах. Однако промежуточные узлы, роутеры и сетевые экраны могут переписать или даже удалить этот параметр. Если ваше соединение не может полностью использовать весь канал, нужно начать с проверки значений окон приема. На платформе Linux опцию масштабирования окна можно проверить и установить так:
$> sysctl net.ipv4.tcp_window_scaling $> sysctl -w net.ipv4.tcp_window_scaling=1В следующей части мы разберемся, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.