

Веб скрапинг для веб разработчиков: краткое резюме
Для обработки больщих объемов данных был придуман скрапинг. Но что мы о нем знаем? Какие есть варианты программного извлечения данных с веб-страницы? Плюсы и минусы каждого подхода? Как использовать облачные ресурсы для увеличения степени автоматизации? Статья поможет получить ответы на эти вопросы.
Мнение автора может не совпадать с мнением редакции
Знание только одного подхода к веб скрапингу решает проблему в краткосрочной перспективе, но все методы имеют свои сильные и слабые стороны. Осознание этого экономит время и помогает решать задачу эффективнее.

Многочисленные ресурсы рассказывают об единственно верном методе извлечения данных с веб-страницы. Но реальность такова, что для этого можно использовать несколько решений и инструментов.
- Какие есть варианты программного извлечения данных с веб-страницы?
- Плюсы и минусы каждого подхода?
- Как использовать облачные ресурсы для увеличения степени автоматизации?
Статический контент
HTML источникиНачнем с простейшего подхода. Если вы планируете скрапить веб-страницы, это первое с чего нужно начать. Потребуется незначительная компьютерная мощность и минимум времени. Однако это работает только в том случае, если исходный HTML код содержит данные, на которые вы ориентируетесь. Чтобы проверить это в Chrome, щелкните правой кнопкой мыши страницу и выберите «Просмотр кода страницы». Теперь вы должны увидеть исходный код HTML.Как только найдете данные, напишите CSS селектор, принадлежащий wrapping элементу, чтобы позже у вас была ссылка.Для реализации вы можете отправить HTTP-запрос GET на URL-адрес страницы и получить обратно исходный HTML код.В Node можно использовать инструмент CheerioJS, чтобы парсить необработанный HTML и извлекать данные с помощью селектора. Код будет выглядеть так:<code>const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });</code>Динамический контент
Во многих случаях вы не можете получить доступ к информации из необработанного HTML-кода, потому что DOM управлялся JavaScript, выполняемым в фоновом режиме. Типичным примером этого является SPA (одностраничное приложение), где HTML-документ содержит минимальный объем информации, а JavaScript заполняет его во время выполнения.В этой ситуации решение состоит в том, чтобы создать DOM и выполнить сценарии, расположенные в исходном коде HTML, как это делает браузер. После этого данные могут быть извлечены из этого объекта с помощью селекторов.Headless браузерыHeadless браузер это то же самое, что и обычный браузер, только без пользовательского интерфейса. Он работает в фоновом режиме, и вы можете управлять им программно вместо того, чтобы щелкать мышью и печатать с клавиатуры. Puppeteer один из самых популярных headless браузеров. Это простая в использовании библиотека Node, которая предоставляет API высокого уровня для управления Chrome в автономном режиме. Он может быть настроен для запуска без заголовка, что очень удобно при разработке. Следующий код делает то же самое, что и раньше, но он будет работать и с динамическими страницами:<code>const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));</code>Конечно, можно делать более интересные вещи с Puppeteer, поэтому стоит посмотреть документацию. Вот фрагмент кода, который перемещается по URL, делает снимок экрана и сохраняет его:<code>const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);</code>Для работы браузера требуется гораздо больше вычислительной мощности, чем для отправки простого запроса GET и анализа ответа. Поэтому выполнение относительно медленное. Не только это, но и добавление браузера в качестве зависимости делает пакет массивным.С другой стороны, этот метод очень гибкий. Вы можете использовать его для навигации по страницам, имитации щелчков, движений мыши и использования клавиатуры, заполнения форм, создания скриншотов или создания PDF-страниц, выполнения команд в консоли, выбора элементов для извлечения текстового содержимого. В принципе, все, что может быть сделано вручную в браузере.Построение DOMВы подумаете, что излишне моделировать целый браузер только для создания DOM. На самом деле это так, по крайней мере, при определенных обстоятельствах.Jsdom — библиотека Node, которая анализирует передаваемый HTML, как это делает браузер. Однако это не браузер, а инструмент для построения DOM из заданного исходного HTML кода, а также для выполнения кода JavaScript в этом HTML.Благодаря этой абстракции Jsdom может работать быстрее, чем headless браузер. Если это быстрее, почему бы не использовать его вместо headless браузеров все время? Цитата из документации:У людей часто возникают проблемы с асинхронной загрузкой скриптов при использовании jsdom. Многие страницы загружают скрипты асинхронно, но невозможно определить, когда это произошло, и, следовательно, когда надо запустить код и проверить полученную структуру DOM. Это фундаментальное ограничение.Это решение показано в примере. Каждые 100 мс проверяется, появился ли элемент или произошел тайм-аут (через 2 секунды).Он также часто выдает сообщения об ошибках, когда Jsdom не реализует некоторые функции браузера на странице, такие как: “Error: Not implemented: window.alert…”или “Error: Not implemented: window.scrollTo…”. Эта проблема также может быть решена с помощью некоторых обходных путей (виртуальных консолей).Как правило, это API более низкого уровня, чем Puppeteer, поэтому нужно реализовать некоторые вещи самостоятельно.Это немного усложняет использование, как видно из примера. Jsdom для этой же работы предлагает быстрое решение.Давайте посмотрим на тот же пример, но с использованием Jsdom:
<code>const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));</code>Реверс-инжинирингJsdom — это быстрое и легкое решение, но можно всё сделать еще проще.Нужно ли нам моделировать DOM?Веб-страница, которую вы хотите скрапить, состоит из тех же HTML и JavaScript, тех же технологий, которые вы уже знаете. Таким образом, если вы найдете фрагмент кода, из которого были получены целевые данные, можно повторить ту же операцию, чтобы получить тот же результат.Если всё упростить, данные, которые вы ищете, могут быть:- частью исходного HTML кода (как видно из первой части статьи),
- частью статического файла, на который есть ссылка в документе HTML (например, строка в файле javascript),
- ответом на сетевой запрос (например, некоторый код JavaScript отправил запрос AJAX на сервер, который ответил строкой JSON).
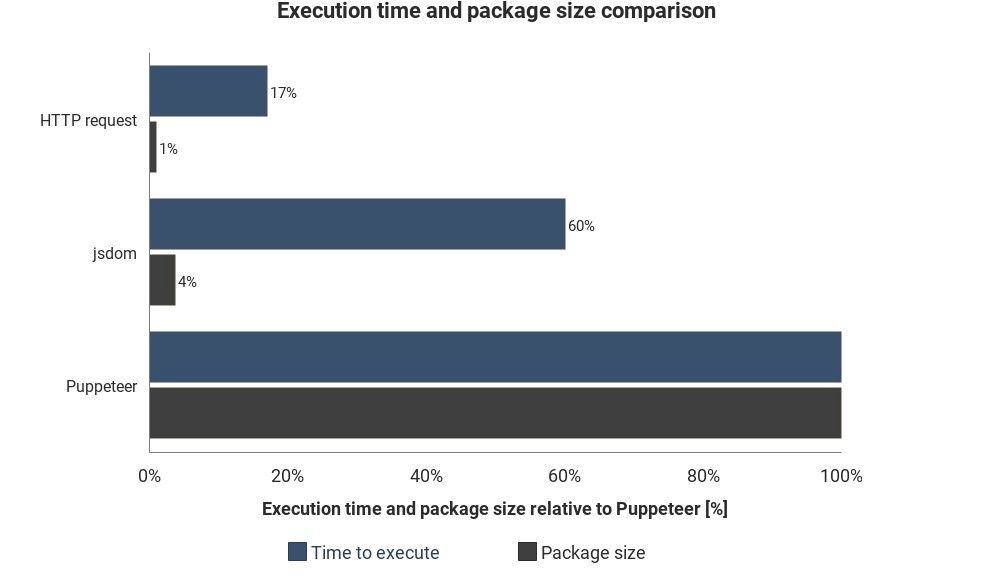 Результаты не основаны на точных измерениях и могут варьироваться, но хорошо показывают приблизительную разницу между этими методами.
Результаты не основаны на точных измерениях и могут варьироваться, но хорошо показывают приблизительную разницу между этими методами. Интеграция облачных сервисов
Допустим, вы реализовали одно из перечисленных решений. Один из способов выполнить скрипт — включить компьютер, открыть терминал и запустить его вручную. Но это станет раздражать и будет неэффективно, поэтому лучше, если бы вы могли просто загрузить скрипт на сервер, и он выполнял код регулярно в зависимости от настроек.Это можно сделать, запустив фактический сервер и настроив правила, когда выполнять скрипт. В других случаях, облачная функция более простой способ. Облачные функции — это хранилища, предназначенные для выполнения загруженного кода при возникновении события. Это означает, что вам не нужно управлять серверами, это делается автоматически выбранным вами облачным провайдером.Триггером может быть расписание, сетевой запрос и множество других событий. Вы можете сохранить собранные данные в базе данных, записать их в Google sheet или отправить по электронной почте. Все зависит от вашей фантазии.Популярные облачные провайдеры — Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure:Можно использовать эти сервисы бесплатно, но не долго. Если вы используете Puppeteer, облачные функции Google — самое простое решение. Размер пакета в формате Headless Chrome (~ 130 МБ) превышает максимально допустимый размер архива в AWS Lambda (50 МБ). Есть несколько методов, чтобы заставить его работать с Lambda, но функции GCP по умолчанию поддерживают Chrome без заголовка, вам просто нужно включить Puppeteer в качестве зависимости в package.json.Если вы хотите узнать больше об облачных функциях в целом, изучите информацию по архитектуре без серверов. На эту тему уже написано много хороших руководств, и большинство провайдеров имеют легкую для понимания документацию.Перевод статьи Web scraping for web developers: a concise summary от Digital Skynet.
0
