

Машинное обучение в биг дата: как мы обрабатываем данные клиентов и предсказываем, что они будут делать
В предыдущей статье мы описали задачи и проблемы, с которыми сталкиваемся при анализе данных клиента. Сегодня поговорим о следующем этапе работы с данными. Он включает в себя выявление признаков, формирование гипотез и построение моделей машинного обучения.
После обработки данных клиента аналитики готовят и формируют признаки, на основе которых модель будет выдавать предсказание. Здесь и далее, для определенности, мы рассмотрим задачу классификации.

В зависимости от специфики задачи, признаки могут быть трендами во времени, характеристиками клиента, фактами каких-либо событий. (см. рис. 1).
Так, наличие звонков в колл-центр оператора, смена тарифа или отказ от услуг могут являться маркерами каких-то изменений в поведении клиента. Кроме этого, различные статистики по платежам, балансу и расходам (средние, медианы, квантили) позволяют оценить, чем конкретный абонент отличается от абонентской базы или её какой-то части (вариант: чем приносящий высокий дополнительный доход абонент отличается от абонента, не приносящего дополнительный доход). К примеру, средние длительности звонков абонентов, склонных к оттоку, обычно падают к дате оттока. Но это верно лишь для абонентов с невысокими расходами.
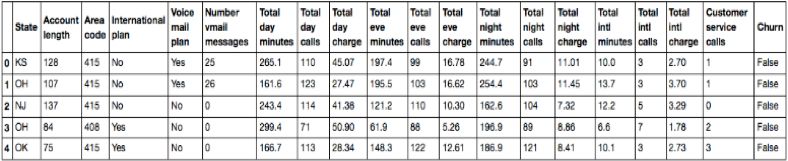
Рис.1. Пример матрицы объекты-признаки для задачи оттока
Дополнительно к исследованию могут подключаться сторонние источники данных: социальные сети, статистические показатели региона проживания абонента и т.д.
Для первичного визуального анализа мы строим распределения признаков в разрезе классов. Так мы находим возможные простые модели и за счет них определяем класс пользователя. Например, может оказаться, что у людей, которые не возвращают кредит – самый дешевый тариф и нет паспортных данных. При этом мы тестируем различные гипотезы (влияет ли стоимость звонков по данному тарифу на склонность человека к оттоку и т.д.), и на их основе выделяем целевой класс (оттекающих или тех, кто не вернет кредит и пр.). Зачастую многие идеи исходят от заказчика, который хочет проверить: верно ли он использует свою стратегию воздействия на своих клиентов и работают ли его специальные предложения.
Модель машинного обучения
После создания и фиксирования некоторого набора признаков мы приступаем к формированию модели машинного обучения.
Что такое модель машинного обучения? Упрощенно говоря, это алгоритм, который позволяет по имеющимся признакам найти различия между двумя (или более) классами.
Существует много алгоритмов классификации (логистическая регрессия, случайный лес, градиентный бустинг, нейронные сети и т.д.), которые определяют принадлежность к классу, исходя из различных предпосылок (см. рис.2). Модель обучается на данных, для которых известны ответы, и пытается оптимизировать некоторую функцию. Например, повысить процент правильных ответов.
Кроме выбора модели, необходимо выбрать метрику – показатель качества, на который мы будем ориентироваться. Таким показателем может быть общее количество правильных ответов алгоритма или какие-то более сложные метрики. Они могут учитывать количество неверных предсказаний, уверенность алгоритма и другие характеристики. Желательно предполагать примерный диапазон требуемой метрики заранее, связывая его непосредственно с бизнес-процессом (количеством заработанных или сэкономленных денег, например).
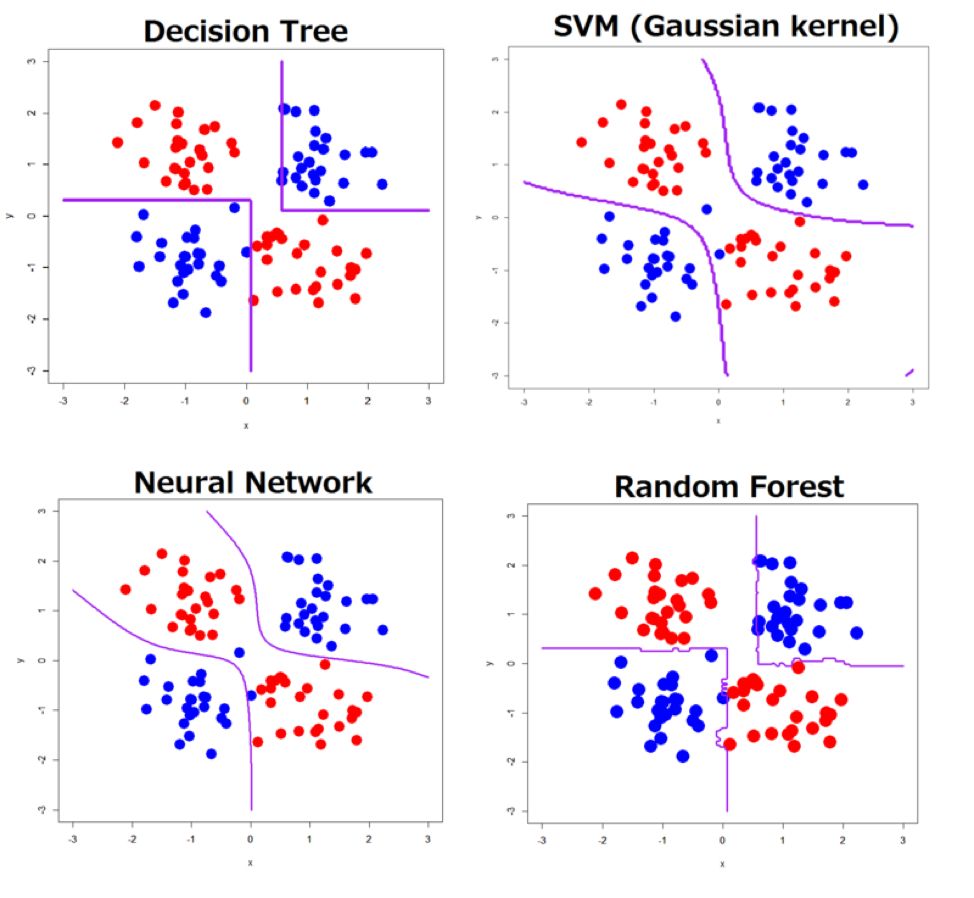
Рис.2. Работа различных алгоритмов по разделению классов.
Процесс обучения и тестирования модели
Для того чтобы проверить работу модели, необходимо оценить ее качество на данных, которые не участвовали в обучении модели. Часто (например, для задачи оттока) такую выборку для проверки нужно набирать еще и с учетом времени. Так мы учитываем различия в свойствах объектов: не заглядывая в будущее, разносим наши предсказания во времени (как это и будет происходить при использовании модели в production). В нашей практике мы проводим тестирование модели именно во времени, а не на исторических данных.
Мониторинг и тюнинг модели
Для контроля качества модели в EW Social Analytics мы предусмотрели систему мониторинга, которая позволяет ежедневно следить за метриками. Иногда стоит обучить модель заново: в случае появления дополнительных данных для обучения или некоторой просадки метрик. Благодаря модульной системе, повторное обучение модели, добавление признаков и тюнинг (подбор лучших параметров алгоритма) не влияют на текущие процессы и могут быть быстро включены в работу.
Так мы работаем с данными в Eastwind. Методы, которые мы применяем для анализа биг дата – универсальны и подходят для применения практически во всех отраслях, имеющих значительные объемы данных: ритейл, маркетинг и реклама, юридическое дело и т.д.
