

Векторные инструкции. Часть 2: Векторизация
В качестве входных данных во всех примерах выступят блоки пикселей некоторого изображения. Для простоты возьмем монохромное изображение, а значения пикселей пусть лежат в диапазоне 0...2^bitdepth — 1, где bitdepth — разрядность пикселей. Изображение представлено одномерным массивом; в примерах значение разрядности либо равно 8 бит, либо лежит в диапазоне 9–16 бит включительно. Следовательно, изображение представлено либо массивом байтов, либо массивом беззнаковых 16-битных целочисленных переменных.
Программный код намеренно упрощён: во всех примерах блоки изображения квадратные, и их размер равен 4, 8 или 16 пикселям. Каждая функция работает с блоками одного выбранного размера и выбранной разрядности пикселей.
Во всех примерах приняты следующие обозначения: src и dst — указатели на левый верхний угол блока-источника и блока-приёмника соответственно; stride — действительная длина одной строки изображения в пикселях, которая может быть равной видимой ширине изображения, либо может превышать её (например, для выравнивания, чтобы адрес пикселя в начале любой строки был кратен 16); bitdepth — разрядность пикселей изображения в том случае, если она отличается от 8 бит.
Копирование блоков
Одна из самых простых задач обработки изображения — копирование фрагмента изображения. Ниже приведена реализация функции копирования блока 8-битного изображения, оформленная в виде шаблона C++.
Пример 1. Копирование данных из src в dst
template void copy_mb(const uint8_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { for(int i = 0; i < SIZE; i++) { for(int j = 0; j < SIZE; j++) { dst[ j ] = src[ j ]; } src += src_stride; dst += dst_stride; } } Копирование происходит во внутреннем цикле, который можно заменить, например, вызовом стандартной функции memset. Но вместо вызова этой функции воспользуемся векторными инструкциями, которые считывают данные из оперативной памяти в регистр, а затем записывают обратно в оперативную память. Для копирования блоков данных в наборе инструкций SSE2 имеются три пары инструкций: _mm_cvtsi32_si128 и _mm_cvtsi128_si32 для блоков длиной 4 байта, _mm_loadl_epi64 и _mm_storel_epi64 для блоков длиной 8 байт, _mm_loadu_si128 и _mm_storeu_si128 для блоков длиной 16 байт. В последнем случае также можно воспользоваться парой _mm_load_si128 и _mm_store_si128 cпри условии, что адрес чтения и записи выровнен по границе (кратен) 16 байтам. Получаем три реализации функции копирования для блоков разных размеров. Пример 2. Копирование данных из src в dst (с векторизацией) #include void copy_mb_4(const uint8_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0; for(int i = 0; i < 4; i++) { x0 = _mm_cvtsi32_si128(*(int32_t*) src); *(int32_t*) dst = _mm_cvtsi128_si32(x0); src += src_stride; dst += dst_stride; } }// copy_mb_4 void copy_mb_8(const uint8_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0; for(int i = 0; i < 8; i++) { x0 = _mm_loadl_epi64((__m128i*)src); _mm_storel_epi64((_m128i*)dst, x0); src += src_stride; dst += dst_stride; } }// copy_mb_8 void copy_mb_16(const uint8_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0; for(int i = 0; i < 16; i++) { x0 = _mm_loadu_si128((__m128i*)src); _mm_storeu_si128((_m128i*)dst, x0); src += src_stride; dst += dst_stride; } }// copy_mb_16 Можно избавиться и от внешнего цикла, как показано ниже в примере 3. Такое «развёртывание цикла» — известный приём, полезный в тех случаях, когда количество итераций невелико и заранее известно, а тело цикла сравнительно небольшое. Пример 3. Копирование данных из src в dst (с векторизацией, без циклов) #include void copy_mb_4(const uint8_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0, x1, x2, x3; x0 = _mm_cvtsi32_si128(*(int32_t*)(src + 0 * src_stride)); x1 = _mm_cvtsi32_si128(*(int32_t*)(src + 1 * src_stride)); x2 = _mm_cvtsi32_si128(*(int32_t*)(src + 2 * src_stride)); x3 = _mm_cvtsi32_si128(*(int32_t*)(src + 3 * src_stride)); *(int32_t*)(dst + 0 * dst_stride) = _mm_cvtsi128_si32(x0); *(int32_t*)(dst + 1 * dst_stride) = _mm_cvtsi128_si32(x1); *(int32_t*)(dst + 2 * dst_stride) = _mm_cvtsi128_si32(x2); *(int32_t*)(dst + 3 * dst_stride) = _mm_cvtsi128_si32(x3); } Функции копирования блоков разрядностью 9–16 бит реализуются аналогично тому, как это сделано для восьмибитных блоков. Нужно просто воспользоваться инструкцией, копирующей большее количество байтов (например, _mm_loadl_epi64 вместо _mm_cvtsi32_si128), либо одной и той же инструкцией несколько раз (лучше всего для блоков 16×16 пикселей). Рассмотрим сложение пикселей двух блоков. Это неотъемлемая часть декодирования видео, в ходе которого один блок пикселей (в нашем случае dst) вычисляется путём интерполяции из пикселей текущего или предыдущих кадров, а другой блок (в нашем случае src) вычисляется с помощью обратного дискретно-косинусного преобразования из декодированных коэффициентов. Вычисление блоков src и dst в примерах не показано, а приведена только заключительная компенсация, то есть сложение значений пикселей указанных блоков и запись результата в блок dst. В простейшем случае (одинаковый тип переменных блоков пикселей и отсутствие целочисленного переполнения) компенсация реализуется следующим образом. Пример 4. Компенсация пикселей (16 бит) template void compensate_mb(const uint16_t * src, uint16_t * dst, size_t src_stride, size_t dst_stride) { for(int i = 0; i < SIZE; i++) { for(int j = 0; j < SIZE; j++) { dst[ j ] = dst[ j ] + src[ j ]; } src += src_stride; dst += dst_stride; } } Инструкции копирования блоков данных мы уже рассматривали ранее. Дополним их инструкцией сложения (в нашем случае это_mm_add_epi16). Тогда векторный вариант кода выглядит как в следующем примере. Для примера взят блок 8×8 пикселей. Пример 5. Компенсация пикселей (16 бит), блок 8×8, с векторизацией void compensate_8(const uint16_t * src uint16_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0, x1; for(int i = 0; i < 8; i++) { x0 = _mm_loadu_si128((__m128i*)src); // 8 pixels x1 = _mm_loadu_si128((__m128i*)dst); x0 = _mm_add_epi16( x0, x1); _mm_storeu_si128((_m128i*)dst, x0); src += src_stride; dst += dst_stride; } } На практике, при декодировании видео разрядность блока, полученного путём обратного дискретно-косинусного преобразования (src), превышает разрядность блока, полученного путём интерполяции (dst). Кроме того, элементы блока src могут принимать и отрицательные значения. В этом случае более реалистичный вариант компенсации выглядит следующим образом. Пример 6. «Реалистичная» компенсация пикселей (16 и 8 бит) template void compensate_mb(const int16_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { for(int i = 0; i < SIZE; i++) { for(int j = 0; j < SIZE; j++) { int tmp = dst[ j ] + src[ j ]; if(tmp > MAX(uint8_t)) dst[ j ] = MAX(uint8_t); else if (tmp < 0) dst[ j ] = 0; else dst[ j ] = tmp; } src += src_stride; dst += dst_stride; } } Здесь значение переменной tmp не должно выходить за пределы допустимых значений пикселей dst (в данном случае 0...255), оно ограничивается верхним либо нижним пределом. Векторная реализация по сравнению с Примером 5 усложняется: необходимо преобразовать значения dst из 8-битных в 16-битные со знаком или без знака. Необходимо также реализовать обратное преобразование в 8-битное значение без знака с ограничениями сверху и снизу. Преобразование беззнаковых целых чисел в целые с вдвое большей разрядностью легче всего осуществляется при помощи инструкций _mm_unpacklo_epiX и_mm_unpackhi_epiX (X = 8, 16, 32, or 64). Например, вектор 8-битных беззнаковых целых чисел преобразуется в два вектора 16-битных целых следующим образом: zero = _mm_setzero_si128(); x1 = x0; x0 = _mm_unpacklo_epi8(x0, zero); x1 = _mm_unpackhi_epi8(x1, zero); Аналогично преобразуются величины большей разрядности. Чтобы преобразовать 16-битные величины в беззнаковые 8-битные, используется инструкция _mm_packus_epi16 , которая упаковывает содержимое двух векторных регистров в один. Она также производит усечение по границам диапазона 0...255, если значение какого-нибудь 16-битного элемента выходит за указанные границы. Тогда векторная реализация для блока 8×8 выглядит, как показано в Примере 7. Пример 7. «Реалистичная» компенсация пикселей (8 бит), блок 8×8, с векторизацией void compensate_8(const int16_t * src, uint8_t * dst, size_t src_stride, size_t dst_stride) { __m128i x0, x1, zero; zero = _mm_setzero_si128(); for(int i = 0; i < 8; i++) { x0 = _mm_loadu_si128((__m128i*)src); // 8 pixels x1 = _mm_loadl_epi64((__m128i*)dst); // 8 bit ! x1 = _mm_unpacklo_epi8(x1, zero); // from 8 to 16 bit x0 = _mm_add_epi16( x0, x1); x0 = _mm_packus_epi16(x0, x0); // back to 8 bit _mm_storel_epi64((_m128i*)dst, x0); src += src_stride; dst += dst_stride; } } Пусть теперь разрядность пикселей изображения (dst) равна некоторому значению из диапазона 9–16 бит, а блок src, вычисленный путём обратного дискретно-косинусного преобразования представлен 32-битными значениями. Преобразовать 32-битную величину в величину из диапазона 0...2bitdepth−1 не так просто, так как нет инструкции, аналогичной _mm_packus_epi16, но для произвольной разрядности данных. Преобразование выполняется в два шага: сначала с помощью инструкции _mm_packs_epi32 два вектора 32-битных целых со знаком упаковываются в один вектор, содержащий 16-битные целые со знаком (диапазон — 32768..32767). Затем, при помощи инструкций _mm_min_epi16 и _mm_max_epi16 (сравнивают пару соответствующих элементов двух регистров и выбирают минимальную и максимальную соответственно) производится усечение значений, лежащих за пределами диапазона. (Обратите внимание, если воспользоваться инструкцией_mm_packus_epi32 iиз набора SSE4.1, которая преобразовывает 32-битные величины в беззнаковые 16-битные, то достаточно всего одного сравнения). Полностью код для блока 4×4 выглядит приведён далее (предполагается, что переполнения при 32-битном сложении не происходит). Пример 8. «Реалистичная» компенсация пикселей (9-16 бит), блок 4×4, с векторизацией void compensate_4(const int32_t * src, uint16_t *dst, size_t src_stride, size_t dst_stride, int bitdepth) { __m128i x0, x1, zero, max_val; zero = _mm_setzero_si128(); max_val = _mm_set1_epi16((1 << bitdepth) — 1); for(int i = 0; i < 4; i++) { x0 = _mm_loadu_si128((__m128i*)src); // 4×32 x1 = _mm_loadl_epi64((__m128i*)dst); // 4×16 x1 = _mm_unpacklo_epi16(x1, zero); // from 16 bit to 32 bit x0 = _mm_add_epi32(x0, x1); x0 = _mm_packs_epi32( x0, x0 ); // from 32 bit to 16 bit /* if x0[k] < max_val, then x0[k]. else max_val */ x0 = _mm_min_epi16(x0, max_val); x0 = _mm_max_epi16(x0, zero); _mm_storel_epi64((_m128i*)dst, x0); src += src_stride; dst += dst_stride; } } В функции используется _mm_set1_epi16, которая устанавливает значения 16-битных элементов векторного регистра равными одной и той же величине. В действительности _mm_set1_epi16 является псевдоинструкцией (как и другие, аналогичные ей), реализация которой зависит от компилятора. Когда требуется высокая производительность, следует избегать подобных псевдоинструкций. Чтобы определить, насколько отличаются изображения, применяют метрики — выражения, использующие значения пикселей обоих изображений. С помощью метрик можно определить оптимальный способ кодирования. Рассмотрим вычисление двух метрик: суммы разностей абсолютных значений (SAD) и средне-квадратичной ошибки (MSE). Для двух изображений одинакового размера они определяются следующими формулами: где w and h — высота и ширина изображений соответственно. Код на «чистом» C/С++, вычисляющий эти выражения, вполне очевиден и не приводится здесь. Рассмотрим построение кода с использованием векторных инструкций. Чтобы рассчитать сумму абсолютных значений двух блоков восьмибитных данных, есть специальная инструкция SSE2 _mm_sad_epu8. Она вычисляет SAD по отдельности для старшей и младшей половин регистров и размещает суммы соответственно. Поскольку модуль разности двух восьмибитных величин не превосходит 255, то каждая из сумм не превосходит 2040. Для блока 16×16 пикселей вычисление SAD приведено в следующем примере. Пример 9. Вычисление SAD для блока 16×16 пикселей, 8 бит #include #include int32_t sad_16_8bit(const uint8_t* src0, const uint8_t* src1, size_t src0_stride, size_t src1_stride) { __m128i x0, x1, sum; sum = _mm_setzero_si128(); for(int i = 0; i < 16; i++) { x0 = _mm_loadu_si128((__m128i*)src0); x1 = _mm_loadu_si128((__m128i*)src1); x0 = _mm_sad_epu8(x0, x1); sum = _mm_add_epi32(sum, x0); // sum for lower and upper halves src0 += src0_stride; src1 += src1_stride; } x0 = _mm_shuffle_epi32(sum, _MM_SHUFFLE(1,0,3,2)); sum = _mm_add_epi32(sum, x0); int32_t s = _mm_cvtsi128_si32(sum); // result return s; } Поскольку _mm_sad_epu8 вычисляет две отдельные суммы для правой и левой половин блока, то и в регистре sum также накапливаются две суммы. Тогда искомый результат равен сумме всех 32-битных элементов регистра sum (точнее, первого и третьего). Меняем местами с помощью _mm_shuffle_epi32 aмладшую и старшую половины регистра sum и записываем результат в регистр x0. Сложив регистры x0 и sum, получаем в младших 32 битах последнего искомый результат. Для блоков меньшего размера вычисление производится аналогичным образом. Только старшая половина регистра sum равна нулю, и дополнительное суммирование не требуется. Это происходит потому, что операции _mm_cvtsi32_si128 и _mm_loadl_epi64 заполняют нулями старшие 96 и 64 бита регистров соответственно. Инструкции, аналогичной _mm_sad_epu8, для данных с разрядностью больше 8 бит не существует. Для входных данных с разрядностью 9–15 бит вычислить модуль разности просто: x0 = _mm_sub_epi16(x0, x1); // x0 — x1 x0 = _mm_abs_epi16(x0); // SSE3 Этот способ требует, чтобы процессор поддерживал набор инструкций SSE3, и не подходит, если разрядность входных данных равна 16 битам ровно (на практике этот случай встречается редко). Тогда модуль разности можно получить следующим образом: x2 = x0; x0 = _mm_subs_epu16(x0, x1); // x0 — x1 or 0 x1 = _mm_subs_epu16(x1, x2); // x1 — x2 or 0 x0 = _mm_xor_si128(x0, x1); // | x0 — x1 | or 0 Инструкция _mm_subs_epu16 (беззнаковое вычитание с насыщением) даёт нуль, если вычитаемое больше уменьшаемого. Тогда _mm_subs_epu16(x0,x1)и _mm_subs_epu16(x1,x2) дают либо абсолютные значения разностей, либо нули для всех пар элементов x0 и x1. Остаётся только объединить значения элементов с помощью логического (либо исключающего) ИЛИ. Подобным образом можно получить модули разности и для случая восьмибитных данных, если заменить 16-битные инструкции восьмибитными (а именно _mm_subs_epu8). Приведём пример вычисления SAD для блока изображения 8×8 пикселей и разрядностью 16 бит на пиксель. Пример 10. Вычисление SAD для блока 8×8 пикселей, 16 бит __m128i x0, x1, x2, sum, zero; zero = _mm_setzero_si128(); sum = zero; for(int i = 0; i < 8; i++) { x0 = _mm_loadu_si128((__m128i*)src0); x1 = _mm_loadu_si128((__m128i*)src1); /* | x0 — x1 | */ x2 = x0; x0 = _mm_subs_epu16(x0, x1); x1 = _mm_subs_epu16(x1, x2); x0 = _mm_xor_si128(x0, x1); x1 = x0; x0 = _mm_unpacklo_epi16(x0, zero); // 16 bit to 32 bit x1 = _mm_unpackhi_epi16(x1, zero); sum = _mm_add_epi32(sum, x0); sum = _mm_add_epi32(sum, x1); src0 += src0_stride; src1 += src1_stride; } /* sum is a0,a1,a2,a3 */ x0 = _mm_shuffle_epi32(sum, _MM_SHUFFLE(2,3,0,1)); // x0 is a1,a0,a3,a2 sum = _mm_add_epi32(sum, x0); x0 = _mm_shuffle_epi32(sum, _MM_SHUFFLE(1,0,3,2)); sum = _mm_add_epi32(sum, x0); int32_t s = _mm_cvtsi128_si32(sum); // result Здесь способом, приведённым выше, вычисляются модули разностей значений пикселей. Но суммировать их в этом виде (16 бит) нельзя из-за возможного переполнения. Поэтому модули преобразуются в 32-битные значения и суммируются в таком виде. После завершения цикла остаётся только вычислить сумму всех 32-битных элементов регистра sum. Эту сумму возможно вычислить не только способом, показанным в примере, но и с использованием инструкций _mm_hadd_epi32 (сложение соседних 32-битных элементов регистра. Требует поддержки процессором инструкций SSSE3). zero = _mm_setzero_si128(); sum = _mm_hadd_epi32(sum, zero); // sum is a0+a1,a2+a3,0,0 sum = _mm_hadd_epi32(sum, zero); // sum is a0+a1+a2+a3,0,0,0 Строго говоря, во всех приведённых ниже примерах будет вычисляться не MSE, а величина Поскольку производится возведение в квадрат, то уже для разрядности 8 бит (и, тем более, для большей разрядности) необходимо учитывать возможность переполнения. Это значит, потребуются дополнительные преобразования разрядности данных. Ниже приведён пример вычисления SED для блока восьмибитных данных. Пример 11. Вычисление SED для блока 8×8 пикселей, 8 бит __m128i x0, x1, x2, sum, zero; zero = _mm_setzero_si128(); sum = zero; for(int i = 0; i < 8; i++) { x0 = _mm_loadl_epi64((__m128i*)src0); x1 = _mm_loadl_epi64((__m128i*)src1); x0 = _mm_unpacklo_epi8(x0, zero); // 8 to 16 bit x1 = _mm_unpacklo_epi8(x1, zero); x0 = _mm_sub_epi16(x0, x1); // x0 — x1 x0 = _mm_madd_epi16(x0, x0); // (x0 — x1)^2 sum = _mm_add_epi32(sum, x0); src0 += src0_stride; src1 += src1_stride; } // sum of sum elements В этом примере сначала восьмибитные данные преобразуются в 16-битные, а затем вычисляется разность значений пикселей. Чтобы получить квадрат разности, удобнее всего воспользоваться инструкцией _mm_madd_epi16: она преобразует 16-битные данные сразу в 32-битные и производит часть необходимых сложений. После выполнения цикла остаётся только сложить значения всех элементов регистра sum как в Примере 10. Аналогичным образом можно вычислить SED для данных разрядностью до 12 бит включительно и для блока 16×16 пикселей. Для данных большей разрядности необходимо преобразование 32 бита — 64 бита при суммировании в цикле. В случае разрядности 16 бит, к тому же, нельзя использовать _mm_madd_epi16 из-за возможного переполнения. Вместо этого необходимо воспользоваться _mm_mullo_epi16 и _mm_mulhi_epu16. В Примере 12 используются эти инструкции, а также вместо разности значений двух пикселей вычисляется абсолютная разность для того, чтобы избежать лишнего преобразования разрядности. Пример 12. Вычисление SED для блока 8×8 пикселей, 16 бит __m128i x0, x1, x2, sum, zero; zero = _mm_setzero_si128(); sum = zero; for(int i = 0; i < 8; i++) { x0 = _mm_loadu_si128((__m128i*)src0); x1 = _mm_loadu_si128((__m128i*)src1); /* | x0 — x1 | */ x2 = x0; x0 = _mm_subs_epu16(x0, x1); x1 = _mm_subs_epu16(x1, x2); x0 = _mm_xor_si128(x0, x1); /* x0^2 */ x1 = x0; x0 = _mm_mullo_epi16( x0, x0 ); x1 = _mm_mulhi_epu16( x1, x1 ); x2 = x0; x0 = _mm_unpacklo_epi16( x0, x1 ); // x0[ i ]^2, i = 0..3 x2 = _mm_unpackhi_epi16( x2, x1 ); // x0[ i ]^2, i = 4..7 x0 = _mm_add_epi32( x0, x2 ); x2 = x0; x0 = _mm_unpacklo_epi32(x0, zero); // from 32 to 64 bit x2 = _mm_unpackhi_epi32(x0, zero); sum = _mm_add_epi64(sum, x0); sum = _mm_add_epi64(sum, x2); src0 += src0_stride; src1 += src1_stride; } // sum of sum elements x0 = _mm_shuffle_epi32(sum, _MM_SHUFFLE(1,0,3,2)); sum = _mm_add_epi64(sum, x0); uint64_t result; _mm_storel_epi64((__m128i*)&result, sum); В предыдущих примерах размеры блоков изображения были фиксированными: 4, 8 или 16 пикселей. В случае произвольных размеров векторизация также не представляет трудности. Обратимся к Примерам 1 и 6: все действия по обработке и копированию данных выполняются в обоих примерах во внутреннем цикле, а во внешнем цикле только указатели смещаются на следующую строку пикселей. Здесь во внутреннем цикле всего одна итерация, и поэтому оператор цикла опускается. Если же блок имеет произвольную ширину, то нужно сделать несколько итераций по ширине, и при этом столько же раз сместить указатели. В общем случае внутренний цикл выглядит как в Примере 13, в котором реализовано вычисление SAD для восьмибитных изображений. Пример 13. Вычисление SAD для блока WxH пикселей, 8 бит #include #include #include uint64_t sad_8bit(const uint8_t* src0, const uint8_t* src1, size_t width, size_t height, size_t src0_stride, size_t src1_stride) { size_t width16 = width — (width % 16); // width16 == 16*x __m128i x0, x1, sum; sum = _mm_setzero_si128(); uint64_t sum_tail = 0; for(int i = 0; i < height; i++) { for(int j = 0; j < width16; j += 16) { x0 = _mm_loadu_si128((__m128i*)(src0 + j)); x1 = _mm_loadu_si128((__m128i*)(src1 + j)); x0 = _mm_sad_epu8(x0, x1); sum = _mm_add_epi64(sum, x0); } for(int j = width16; j < width; j ++) { sum_tail += abs(src0[j] — src1[j]); } src0 += src0_stride; src1 += src1_stride; } x0 = _mm_shuffle_epi32(sum, _MM_SHUFFLE(1,0,3,2)); sum = _mm_add_epi64(sum, x0); uint64_t sum_total; _mm_storel_epi64((__m128i*)&sum_total, sum); sum_total += sum_tail; return sum_total; } В общем случае длина обрабатываемой строки не кратна 4, 8, или 16 байтам. Поэтому получившийся «хвост» обрабатывается отдельно. Инструкций, позволяющих загрузить произвольное количество байтов из памяти, не существует. Самый простой выход: оставить этот участок кода без векторизации, как это сделано в Примерах 9 и 13. В этом примере длина «хвоста» никогда не превышает 15 байт, и для достаточно больших блоков изображения производительность функции снижается незначительно. В случае, когда реализуется алгоритм, требующий больших затрат процессорного времени, желательно, чтобы как можно меньшее количество данных обрабатывалось кодом без векторизации. Тогда можно воспользоваться приёмом, показанным в Примере 14. Пример 14. Вычисление SAD для блока WxH пикселей, 8 бит (вариант) #include #include #include uint64_t sad_8bit(const uint8_t* src0, const uint8_t* src1, size_t width, size_t height, size_t src0_stride, size_t src1_stride) { size_t width_r = width % 16; size_t width16 = width — width_r; // width16 == 16*x size_t width8 = width_r — (width_r % 8); // 8 or 0 width_r -= width8; size_t width4 = width_r — (width_r % 4); // 4 or 0 width_r -= width4; // 0, 1, 2, or 3 __m128i x0, x1, sum; sum = _mm_setzero_si128(); uint64_t sum_tail = 0; for(int i = 0; i < height; i++) { for(int j = 0; j < width16; j += 16) { /* SAD calculation */ } if( width8) { x0 = _mm_loadl_epi64((__m128i*)(src0 + width16)); x1 = _mm_loadl_epi64((__m128i*)(src1 + width16)); x0 = _mm_sad_epu8(x0, x1); sum = _mm_add_epi64(sum, x0); } if( width4) { x0 = _mm_cvtsi32_si128(*(int32_t*)(src0 + width16 + width8)); x1 = _mm_cvtsi32_si128(*(int32_t*)(src1 + width16 + width8)); x0 = _mm_sad_epu8(x0, x1); sum = _mm_add_epi64(sum, x0); } for(int j = width — width_r; j < width; j ++) { sum_tail += abs(src0[j] — src1[j]); } src0 += src0_stride; src1 += src1_stride; } /**/ } В этом примере количество пикселей, которые обрабатываются без векторизации, никогда не превышает трёх. Инженер Elecard. Занимается оптимизацией аудио- и видеокодеков, а также программ для обработки аудио- и видеосигналов с 2015 года.
Компенсация
Вычисление метрик
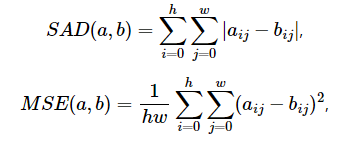
Вычисление SAD
Вычисление MSE
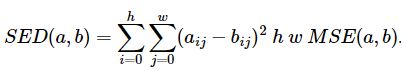
Произвольные размеры области изображения
Источники
Автор

