

Кейс по Fault-Tolerant Systems: Формирование графа состояний объекта управления для потока неисправностей
В случае, когда неотработанные той или иной системой неисправности могут нести большие потери для бизнеса, важно понимать, какие цепочки событий и некритичных сбоев могут к ним привести. Имея возможность отcлеживать свое положение в пространстве «работоспособности» относительно критических состояний, можно избегать фатальных последствий.
Таким системами могут быть как различного рода технические процессы, так и социальные агентные системы, где в роли управляющих воздействий выступают управленческие решения, и они же могут приводить к сбоям.
Небольшое предварительное разъяснение
В данной статье я не буду претендовать на чрезмерную оригинальность изложения. Значительная часть статьи взята из различных статей, которые писались по этому вопросу мной и коллективом авторов из ЛЭТИ с 2012 по 2017 год. Ссылки на эти статьи находятся ниже в библиографии (и это еще не все). Всю глубину вопроса, который изучался 5 лет, я поднять, конечно, не сумею и не буду пытаться. Расскажу только о небольшой своей части связанной с автоматическим построением графа неисправностей.
Заодно тут я высказываю свою признательность всем, кто со мной работал. В особенности своему научному руководителю, с которым я работал начиная с 2003 года — Леониду Борисовичу Пошехонову.
Постановка задачи и контекст
В 2012 году научный руководитель вызвал меня к себе, решив рассказать о своем нежданном счастье. Его попросили нарисовать математическую модель процесса нанесения композиционных покрытий на подложку и синтезировать над ней систему управления (СУ), которая бы гарантировала отсутствие отказов на главном этапе — собственно на этапе нанесения покрытия. В случае проблем на этом этапе на свалку отправлялась куча дорогого материала, а этого не хотелось. С созданием математических моделей технологических процессов проблем не было, а вот управляющая часть давалась плохо, потому что процесс разбивался на 13 зависимых стадий, каждая из которых могла начать неадекватно работать по-своему и обладала собственной внутренней подсистемой управления.
В течение полугода общими усилиями СУ, которая параноидально готовилась к главной стадии процесса, чтобы не дай бог ее не завалить, была сделана, а дальше встал один из самых довлеющих над научно-инженерным сообществом вопросов — «А что собственно мы сделали? Как это можно обобщить, можно ли, насколько это связано с существующим мировым опытом?»
Некоторое дополнительное рытье в источниках позволило охарактеризовать сделанное как отказоустойчивую систему управления иерархическим многостадийным процессом. Достаточно оригинальную в своей узости концепцию. Немного про это все написано в такой нашей статье. Однако стоит учитывать, это достаточно старая статья, и формализации успели пару раз смениться. Чисто для ознакомления. Улучшенный вариант описывается в этой докторской диссертации (можно ее где-то здесь скачать).
Моя часть, в конечном итоге, относительно всей этой работы была довольно скромная. Я пытался математическими символами записать идеологию подхода к синтезу, которая получилась в конечном итоге.
Тут написано об одной части подхода, который используется при составлении СУ какой-то одной стадией процесса на самом низком уровне показаний с датчиков с объекта управления (ОУ). Впрочем, ничто не мешает использовать тот же подход на более высоких уровнях и других масштабах времени.
Суть подхода заключается в том, что система диагностики, на которую приходят данные с датчиков ОУ, регистрирует «симптомы» неисправностей в рамках текущей системы и передает системе, которая называется Супервизор. Супервизор на основе множества и порядка прихода «симптомов» ставит «диагноз» и назначает «лечение», передавая управляющий сигнал системе реконфигурации, которая перестраивает структуру объекта управления таким образом, чтобы функциональность системы не терялась. И этот процесс работает параллельно тому, который следит, чтобы система делала что-то полезное. Довольно просто.
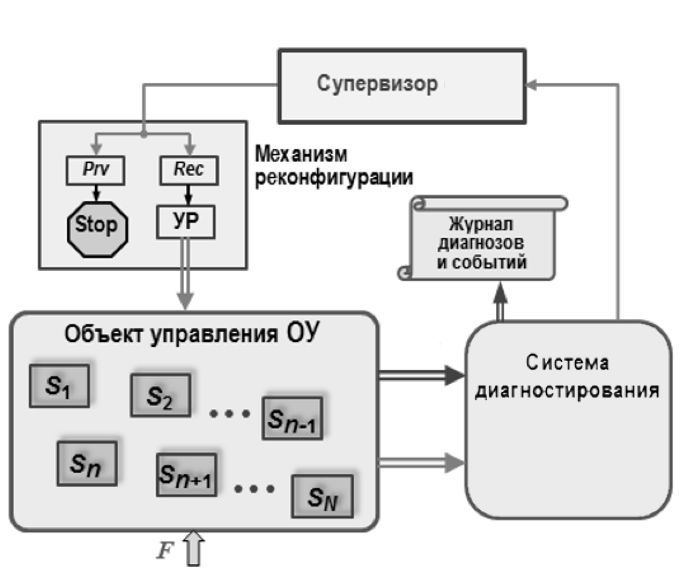
F на рисунке это всякие неприятные внешние воздействия и другие вещи, которые могут способствовать появлению неисправностей. Разные S это разные объекты управления, которые получаются в ходе реконфигурации при неисправности. Это в целом и без деталей.
А в частности…
В момент, когда люди думают над тем, как строить систему отказоустойчивого управления, они начинают выписывать все неисправности, которые могут происходить и раздумывать, как эти неисправности друг на друга влияют в рамках технологического процесса. Полностью красиво и автоматически все сделать за человека в этом вопросе не получается, но кое-какие моменты удается сделать изящно.
Например, построить автоматически граф «диагнозов», который будет основой работы супервизора. И по которому супервизор будет определять, какие действия по избежанию фатальных последствий надо совершить.
Некоторые требования и ограничения
Как и любой метод, этот имеет ряд ограничений и требований. Сформулируем те, которым будем следовать:
- Формируется состав из N потенциальных неисправностей
- Порядок следования неисправностей – произвольный
- Неисправности – не кратные (отсутствуют повторяющиеся)
- Последующая неисправность может появиться только после окончания реакции системы на предыдущую
- Неисправность диагностируемая, если она может быть обнаружена и идентифицирована (определен ее индекс в составе неисправностей)
- Неисправность восстанавливаема, если существует такое управляющее воздействие системы реконфигурации, которое восстанавливает возможность успешного завершения (продолжения) технологического цикла
- Неисправность актуальна, если она может оказать влияние на успешное завершение (продолжение) технологического цикла
- Образование нового объекта управления в результате действия неисправности и/или реконфигурации можно трактовать как приход ОУ в новое состояние
- Приход очередной неисправности как правило сопровождается уменьшением ресурсов по диагностированию потенциально возможных оставшихся неисправностей, а также по восстанавливаемости системы.

Выражение означает, что объединение влияний первой и второй неисправности на третью равно влиянию на третью неисправность ситуации, когда эти обе первые неисправности уже произошли.
Алгоритм формирования графа состояний объекта управления для потока неисправностей
Определим неисправность как тройку логических значений flt = {δ, ρ, θ}, где:
δ — неисправность диагностируема в текущей системе,
ρ — неисправность восстанавливаема в текущей системе,
θ — неисправность одновременно восстанавливаема и диагностируема в текущей системе, но она порождает возможность недиагностируемой неисправности.
Пусть система управления рассчитана на поток из N неисправностей. Тогда в каждый момент времени возможность развития событий в ней может быть описана тремя векторами
 Известно состояние неисправностей в начальный момент времени.
Известно состояние неисправностей в начальный момент времени.
d₀, r₀, a₀ — векторa диагностируемости, восстанавливаемости, актуальности номинальной системы (предполагается, что рассмотрение начинается из состояния, когда никаких неисправностей нет, впрочем, это не так существенно). |d₀| = |r₀| = |a₀| = N.
Чтобы рассчитать текущие значения векторов относительно начального состояния, вводятся матрицы потери ресурсов:
D, R, A — матрицы N×N потери диагностируемости, восстанавливаемости и актуальности.
Каждая из этих матриц является обобщенной матрицей потери ресурса. Такого рода матрицы можно описать следующим образом. Матрица потери X– это матрица K×K, где i-я строка матрицы определяет, какие элементы вектора x размерности K должны быть заменены при i-й неисправности:
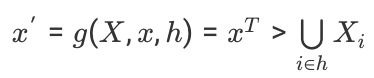
Здесь Xi — i-я строка матрицы h — множество индексов произошедших неисправностей, «>» — поэлементная булева функция больше (инверсия прямой импликации).
Пример использования матрицы потери ресурса.
Пусть:
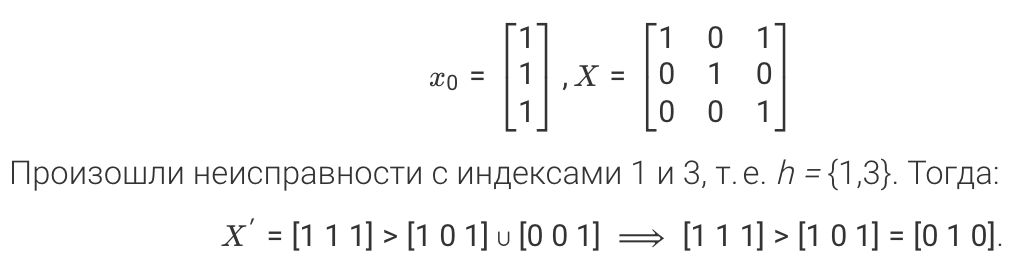
Таким образом, имея матрицы потери ресурсов для всех трех векторов и начальные состояния, можно построить граф, описывающий изменение ресурсов диагностируемости, восстанавливаемости и актуальности системы при потоке неисправностей, используя следующий алгоритм:


Динамика в процесс легко добавляется заданием исходного вектора вероятностей неисправностей за период и матрицей условных вероятностей неисправностей при условии произошедшей неисправности в течение какого-то периода. Таким образом весь процесс можно будет еще и промоделировать.
В ходе синтеза системы управления это не обязательно, но важно иметь в виду в ходе эксплуатации. Например, у нас появляется недиагностируемая, но крайне маловероятная неисправность. Возможно, имеет смысл не сразу останавливаться после возникновения такой ситуации, а с помощью анализа выживаемости оценить общую вероятность неисправности к концу какого-нибудь важного технологического цикла, который тяжело откатить. Но это зависит от конкретной системы и ее рисков.
Пример 1
Пусть возможны 4 пронумерованные неисправности. Вследствие первой неисправности все остальные становятся недиагностируемыми (например, неисправен датчик). Вторая неисправность приводит к тому, что остальные становятся невосстанавливаемыми (например, сломался агрегат, который отвечает за восстановление неисправностей). Третья неисправность делает все остальные неактуальными (такого, конечно, не бывает). Векторы d, r, a в начальный момент времени составлены из единиц. В результате работы алгоритма получается граф, который изображен на рисунке ниже. Номинальному состоянию системы отвечает вершина Nom. Белые вершины отвечают состояниям, в которых возможно восстановление системы. Красными вершинами дерева обозначены невосстанавливаемые системы, бежевыми — недиагностируемые. Бежевые с белым ободом – состояния, в которых возможно появление недиагностируемых неисправностей. Красные с белым ободом — недиагностируемые и невосстанавливаемые неисправности (их в этом примере нет).
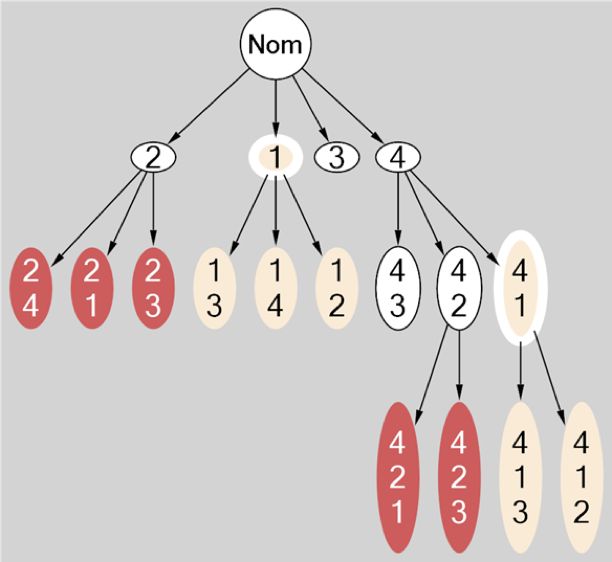
Пример 2
Попробуем привести пример повеселее. Например, построить граф косяков в личной жизни и иерархию их исправимости.
Пусть есть три косяка, которые человек может совершить в пятницу вечером. Он может нажраться, изменить, и выключить телефон. Сами по себе все косяки «исправимы». Про измену можно не сказать, за телефон можно извиниться и протрезветь к утру. Но проблема возникает, когда они встречаются вместе.
Если человек нажрался, может не отследить измену. Она станет недиагностируемой. Если изменил и телефон был выключен, то обязательно на этом запалят и выгонят из дома. И наоборот. Если выключил телефон, а потом изменил, тоже самое. При этом надо отметить, что такая симметричность далеко не обязательна.
Вот что выходит:
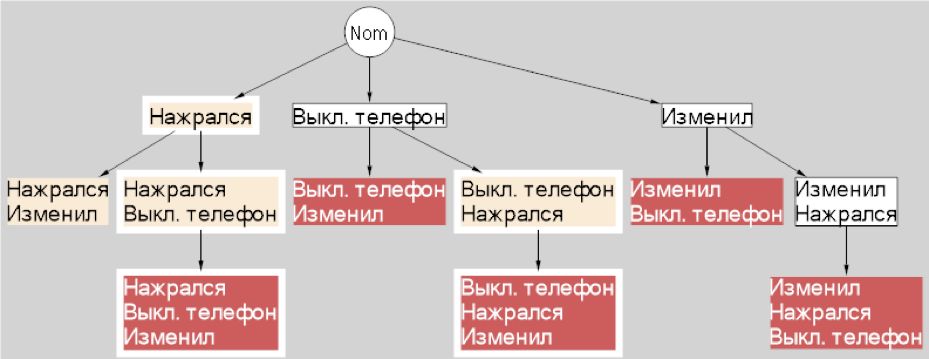
Результат не столько моральный, сколько жизненный. Нажираться не следует, а то мало ли что. А уж если нажрался, надо сразу прекращать праздник и пилить домой, дабы избежать недиагностируемых последствий. Но если сначала трезвый изменил, а потом нажрался, надо внимательно следить, чтобы телефон при этом не выключался.
Если вы посмотрите статьи, то найдете там более выразительные примеры со всякими серьезными техническими системами, реальными объектами, дифференциальными уравнениями и всякое такое.
Библиография
- Шестопалов М.Ю., Пошехонов Л.Б., Беспалов А.В., Альшуль С.Д., Гузаев Е.В., Тюгашев А.А. Разработка интерактивных систем отказоустойчивого управления сложными объектами. XX международная конференция по мягким вычислениям и измерениям (SCM’2017). С-Петербург, 24-26 мая 2017 г. /Сборник докладов/ СПб: Изд-во СПбГЭТУ «ЛЭТИ». С 171–176.
- Шестопалов М.Ю., Имаев Д.Х., Пошехонов Л.Б., Беспалов А.В. Проектирование супервизоров многоуровневых систем отказоустойчивого управления на основе конечных автоматов. Материалы 9-й конференции «Информационные технологии в управлении» (ИТУ-2016). – СПб.: АО «Концерн «ЦНИИ «Электроприбор», 2016. С. 276–282.
- Шевцов И.В., Шестопалов М.Ю. Моделирование ТП разложения паров тетракарбонила никеля// Сб. докладов 11-ой междунар. конф. по мягким вычислениям и измерениям (SCM’2008). С-Петербург, 25-27 июня 2008 г. т. 1. С. 100–102.
- Шестопалов М.Ю., Пошехонов Л.Б., Беспалов А.В. Отказоустойчивое управление подсистемой технологического процесса никелевого производства. XIX Международная конференция по мягким вычислениям и измерениям (SCM’2016). С-Петербург 25-27 мая 2016 г./Сборник докладов./ СПб: Изд-во СПбГЭТУ «ЛЭТИ». С 211–216.
- Шестопалов М.Ю., Имаев Д.Х., Пошехонов Л.Б., Беспалов А.В. Программа автоматического формирования графа состояний конечного автомата супервизора системы отказоустойчивого управления в условиях потока неисправностей. Свидетельство о государственной регистрации программы для ЭВМ № 2016663040 от 28.11.2016 г. Федеральной службы по интеллектуальной собственности РФ.
- Беспалов А.В., Гузаев Е.В., Кораблев Ю.А., Пошехонов Л.Б., Шестопалов М.Ю., Алгоритмы и программы формирования графа состояний отказоустойчивых систем управления в условиях потока неисправностей (CTS’2017). С-Петербург 25-27 октября 2017
Автор статьи: Alexander Bespalov, Research Data Analyst, Maxilect



