

DWH без иллюзий. Три реальных кейса внедрения корпоративного хранилища в ритейле, производстве и госсекторе
24 июня на открытой онлайн-встрече «Три реальных проектных истории внедрения DWH. Сложности и вызовы» эксперты Qlever Solutions рассказали о настоящих трудностях, с которыми сталкиваются команды при внедрении корпоративных хранилищ данных — от технических ограничений до управленческих конфликтов.
Спикером мероприятия выступил технический директор Qlever Андрей Харлак. Обширный опыт внедрений хранилищ данных позволил Андрею поделиться техническими деталями и нюансами управления DWH-проектами в промышленности, ритейле, госсекторе.
В статье делимся кейсами, представленными на вебинаре и рассказываем, что делать, когда проект внедрения корпоративного хранилища идёт не по плану.
Индивидуальный подход как основа успешного проекта DWH
Data Warehouse — корпоративное хранилище, объединяющее структурированные исторические и текущие данные для последующей аналитики.
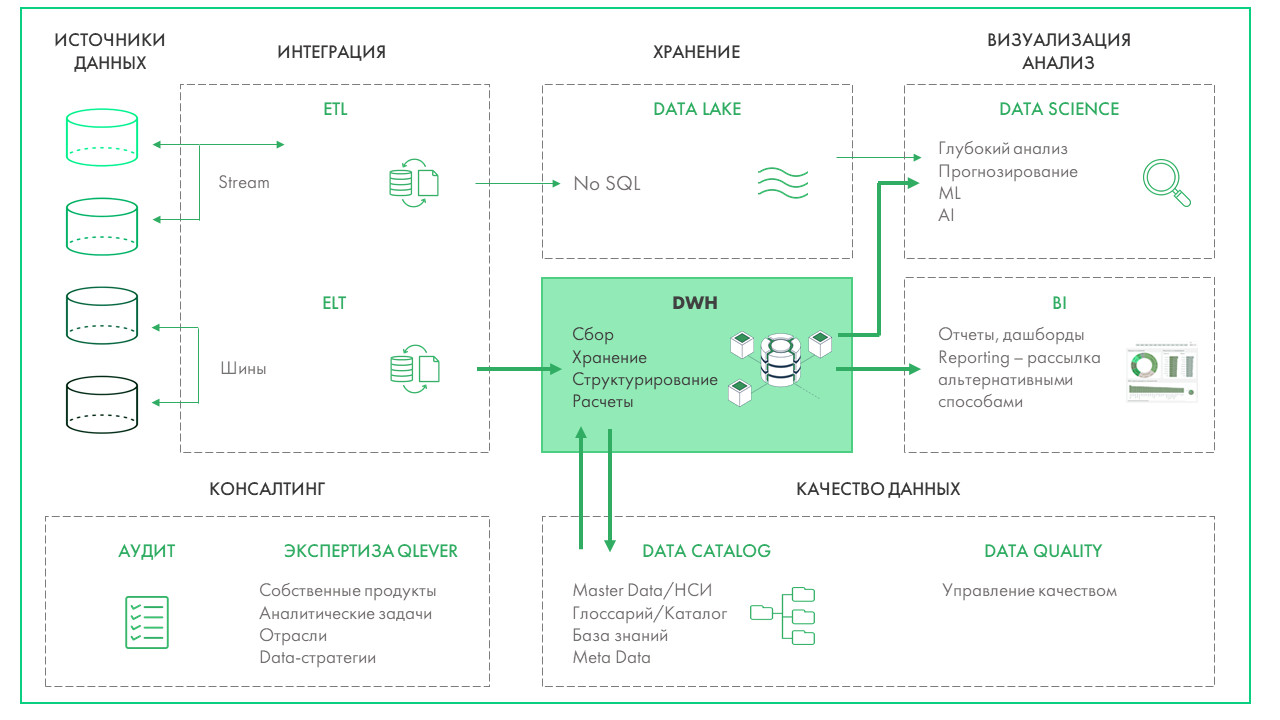
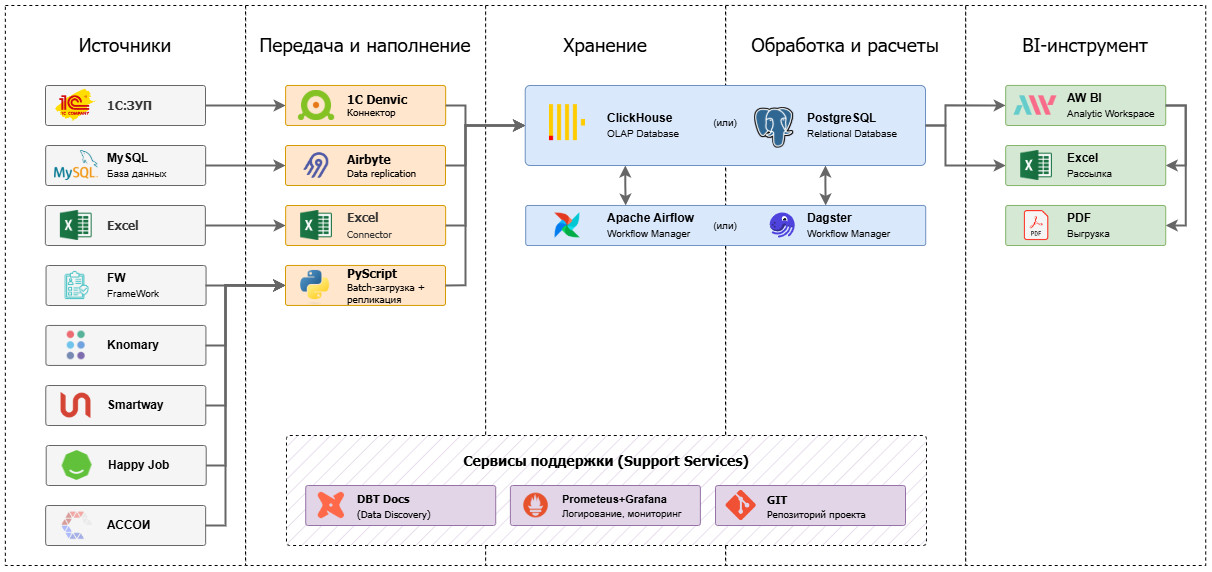
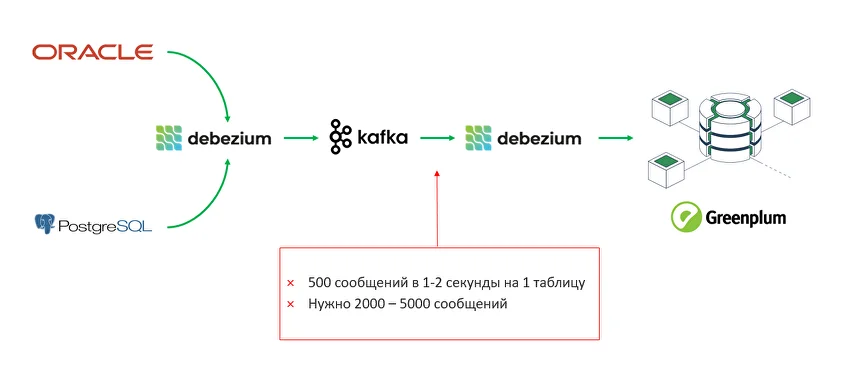
Что такое DWH, и какие задачи бизнеса решает корпоративное хранилище данных Проект создания корпоративного хранилища данных (DWH) отличается значительными масштабами и сроками реализации. Архитектурно хранилище представляет собой сложную многоуровневую структуру, каждая из частей которой состоит из технологий и инструментов, выполняющих функции экстракции, процессинга, хранения, сопровождения, оркестрации, логирования, визуализации данных. При чем одну и ту же задачу можно решить сразу несколькими open-source или проприетарными инструментами, выбор которых зависит от уже существующей инфраструктуры, требований к скорости обработки данных, бюджета, потребностей в визуализации и интеграции с другими системами. Помимо этого, сложность DWH-проектов заключается в том, что каждая компания достигает своего уровня зрелости в управлении данными. Один бизнес только начинает путь — у них отсутствует централизованная аналитика, данные разрознены, отчеты готовятся вручную или локально. Другой уже внедрил современные подходы к управлению качеством данных, ввел стандарты, выстроил Data Governance. В зависимости от этого уровня на старте проекта DWH у компаний возникают уникальные задачи и потребности: от сокращения времени на подготовку текущей операционной отчетности, до масштабирования продвинутой аналитики на новые направления бизнеса. Проект построения хранилища данных — это не просто внедрение технологий, а глубокая трансформация подходов к данным и аналитике, учитывающая текущее состояние процессов, стратегические цели, ресурсы и компетенции команды. Продемонстрируем важность индивидуального подхода к реализации на примере реальных проектов из практики Qlever. С задачей построения корпоративного хранилища данных в Qlever обратилась крупная компания из отрасли ритейл. На этапе пресейла были определены два источника данных для интеграции: ERP-система на базе Oracle и кассовая система на PostgreSQL. В дальнейшем на стадии обязательного предпроектного обследования и сбора требований, наши эксперты выявили три ключевых фокуса заказчика: При этом обязательным требованием клиента стала реализация хранилища с использованием только open-source инструментов. Для обеспечения KPI по скорости передачи данных из источника в DDS изначально был выбран инструмент Debezium, который позволяет реализовать практику Change Data Capture (CDC) — стриминга изменений данных с низкой задержкой. Debezium читал данные из логов Oracle и Postgres, отправлял сообщения в Kafka и в дальнейшем должен был записать их в хранилище на Greenplum. При такой реализации команда столкнулась с «бутылочным горлышком» — на этапе передачи из Kafka количество сообщений вызывало очередь. Debezium не мог справиться с 5000 сообщений за 1–2 секунды на 1 таблицу и писать такой объем данных в Greenplum. Ситуация требовала поиска альтернативного решения, которое бы заменило Debezium. Создать свой коннектор, который писал бы в csv, далее передавал файлы в Greenplum Решение не подошло из-за ограничений, которые предполагает формат csv: Реализовать архитектуру Kafka — Rabit MQ — Greenplum Streaming Server — Greenplum Несмотря на гибкость маршрутизации, решение не подошло из-за ряда факторов: Использовать утилиту Greenplum GPFdist для работы с csv-файлами Помимо вышеперечисленных ограничений csv, такое решение показало слабую производительность, задержки и отсутствие real-time обновления. Подобные решения хорошо применять, когда требования к обновлению более мягкие. Использовать External web tables, которые бы наполнялись из топиков в Kafka — выбранный вариант В спроектированном коннекторе Airflow запускает скрипт на Python, который проводит сериализацию сообщений из Kafka в бинарную строку и пишет в External web tables. Так как External web tables работает напрямую с сегментами, а не с мастер-нодами Greenplum, данный вариант помог повысить производительность до 150 000 сообщений за 30 секунд. Кроме того, скрипт на Python дал определенную гибкость в параметризации и простоту тестирования и отладки. Несмотря на возможность реализации требований клиента, при создании коннектора специалисты Qlever столкнулись с некоторыми трудностями: Для решения задачи реализован дополнительный функционал Connectivity tool на Python и Airflow, который отслеживает изменения метаданных таблиц и корректирует состав полей как на уровне Kafka, так и на уровне Greenplum. Остальные 120 таблиц из Oracle реплицировались отдельным потоком, к которому не было жестких требований по скорости появления в DDS. Потеря репликации при сетевых сбоях Для того, чтобы определить все возможные точки отказа, специалисты Qlever создали и протестировали Disaster recovery plan — план аварийного восстановления, который учитывает все возможные случаи сбоя настроенной цепочки обновления данных. Архивация логов Из-за большого объема данных 40–50 тыс. сообщений Debezium не всегда успевал найти события в online логах Oracle. Для решения задачи специалисты Qlever провели настройки параметров Debezium, определяющих ожидание логов и поиск новых строк. Перекачка первичных данных Стандартный коннектор Debezium не может забрать весь объем данных. Для загрузки первоначального объема данных и настройки репликации была применена технология PXF (Platform Extension Framework) в Greenplum и настроен параметр Snapshot no data в Debezium. Таблицы без ключей На уровне источника данных Oracle существуют таблицы, обновляемые напрямую ERP-системой. В этих таблицах может быть несколько одинаковых строк заказов с одним набором атрибутов (заказ, палета, товар), но с разной себестоимостью. При этом товары могут быть указаны как одной строкой, по пять штук, так и пятью строками, по одной штуке в каждой. Для этих таблиц без ключа необходимо было обеспечить полную репликацию с версионностью, чтобы можно было отслеживать истории изменений напрямую в Greenplum. Первичное обновление данных загружает всю комбинацию заказ-палета в Greenplum. В дальнейшем, при обновлении любой из строк заказа в ERP-системе, заказ еще раз выгружается полностью в хранилище через PXF с новой датой обновления, а старые строки помечаются как неактивные. То есть, если таблица обновляется N раз, в Greenplum остается N копий данных, каждая со своей меткой обновления, но активная версия существует только одна — в источнике данных. Задачей следующего клиента Qlever из производственной отрасли было мигрировать с аналитической системы на базе Qlik Sense на PIX BI с готовым DWH. На старте проекта выяснилось, что DWH не было внедрено, а фактически только строилось. Ситуацию осложняло количество команд, задействованных в проекте: Для решения возникших сложностей эксперты Qlever провели аудит внедренного хранилища данных. По результатам аудита: Одним из важных итогов проекта стали установленные правила взаимодействия с клиентом: Задачей Qlever стало внедрение хранилища в дочерней компании, входящей в состав большой разветвленной холдинговой структуры со строгими регламентами. Дочерняя компания и холдинг работают в разных часовых поясах (4 часа) Часть информации при коммуникации теряется, а оперативность в решении вопросов отсутствует В проекте участвуют разные команды Компания входит в холдинг, где уже есть собственная техподдержка и команда архитекторов В проекте участвует внешний подрядчик Подрядчик должен был настраивать один из источников данных — брокер сообщений Kafka, в итоге функционал был недостаточным для начала наших работ, сроки сдвигались Дополнительные согласования Из-за большого количества стейкхолдеров в дочерней компании и холдинге процесс согласования затягивался Обезличивание данных Одно из требований службы безопасности компании — обезличивание данных в тестовой среде Каждый DWH-проект уникален и требует не только своего набора инструментов, но и индивидуального подхода к клиенту, взаимодействия между командами, нестандартных решений. Практика управления изменениями и управления проектами — это важная часть работы компании, внедряющей хранилище, наравне с глубоким знанием технологий и методологий построения DWH. Команда Qlever всегда нацелена на результат, при котором клиент получает именно то решение, которое выполнит поставленные задачи, даже если старт работ был запущен еще год назад, и требования к проекту успели поменяться. Обратитесь к опытной команде, специализирующейся на проектировании хранилищ данных Составим дорожную карту проекта и решим специфические задачи вашего бизнеса

Кейс 1. Свой коннектор к Oracle: когда Debezium подвел
Предпосылки
Варианты решения
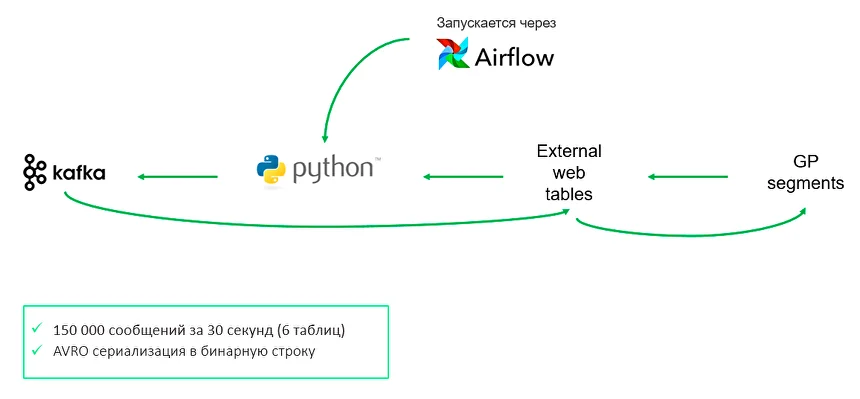
Вызовы при создании коннектора и пути их решения
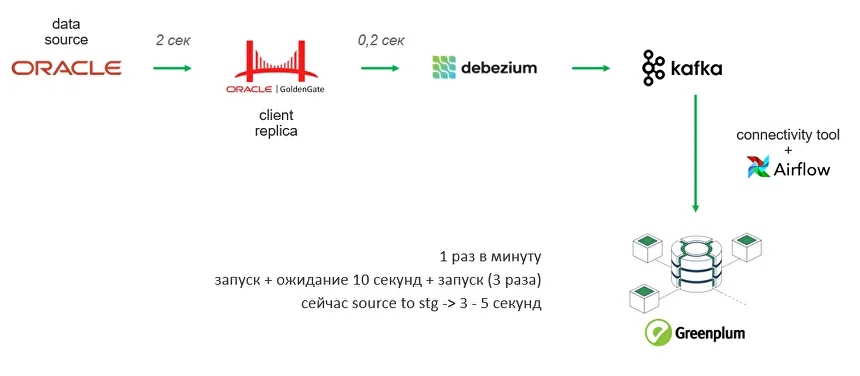
Где оказались узкие места производительности коннектора и как их обошли
Итоги
Кейс 2. Миграция с Qlik: DWH между командами (в условиях командной фрагментации)
Предпосылки
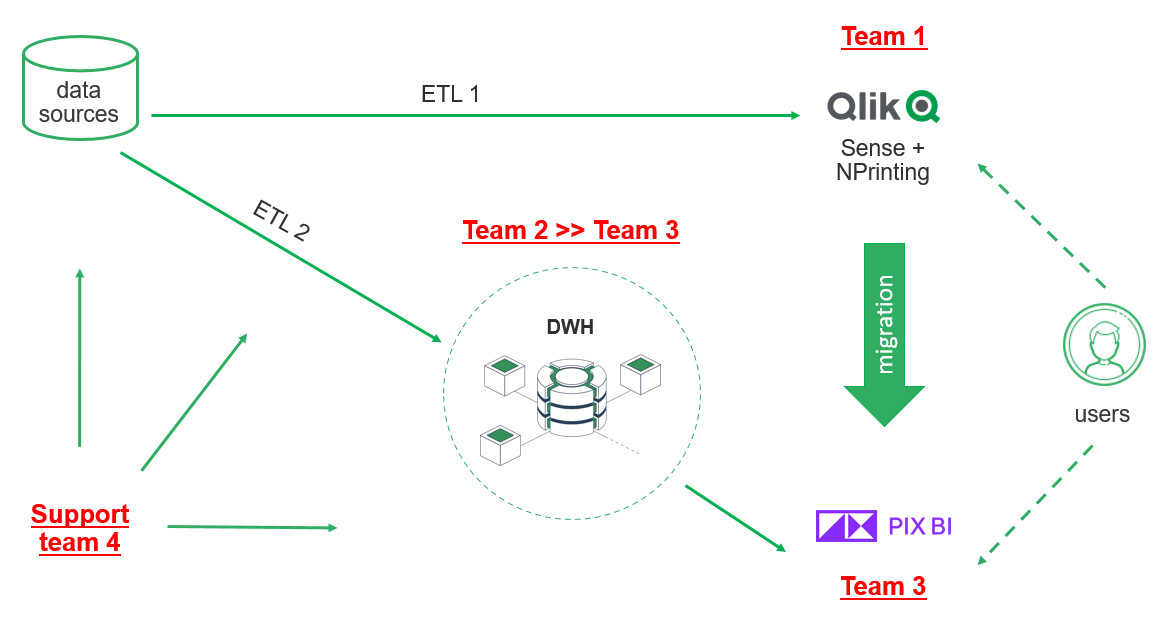
Проблематика проекта
Решение
Итоги
Кейс 3. Бюрократия против DWH: проект в около-госсекторе
Предпосылки
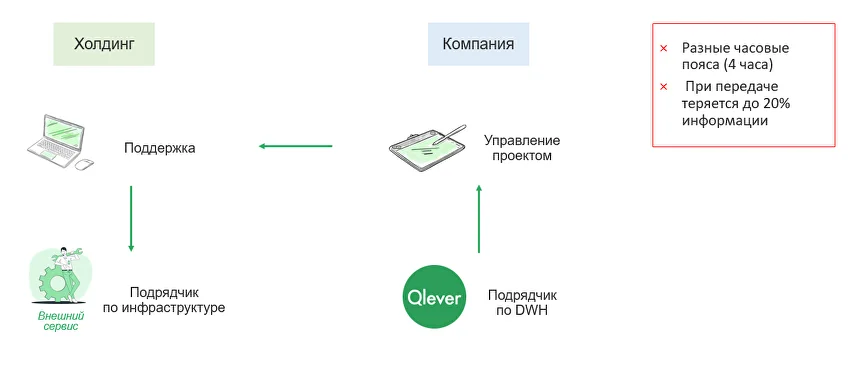
Проблематика проекта
Решение
Что делать, когда внедрение DWH — это больно?
