

Dagster или Airflow: что выбрать для оркестрации в DWH-проектах?
Перед аналитикой данные из корпоративных систем необходимо превратить в информацию, пригодную для бизнес-анализа:
- Извлечь из разрозненных источников
- Трансформировать — фильтровать, группировать, структурировать, агрегировать в датасет
- Загрузить в целевую систему — DWH, BI, Data Lake, СУБД, облако и т.д.
Вместе эти три процесса называются ETL (Extract, Transform, Load).

Для реализации ETL-процессов на рынке существует готовое ПО, однако оно не всегда может отвечать потребностям проекта.
При проектировании масштабных решений, например, корпоративных хранилищ данных, а также при необходимости встроить аналитические инструменты в имеющуюся сложную инфраструктуру Big Data, дата-инженеры обычно создают собственные конвейеры обработки данных — пайплайны.
Пайплайн может включать десятки шагов: извлечение данных из источников, очистку, трансформации, загрузку, агрегации, построение витрин. Он может выполняться раз в час, в конце дня, по триггеру, например, при поступлении нового файла.
Вручную управлять всеми этими условиями и настройками трудоемко.
Для автоматизации планирования, мониторинга и выполнения задач в рамках пайплайнов используются специальные программные решения — оркестраторы.
Когда речь заходит об оркестрации данных, почти всегда упоминаются два инструмента: Apache Airflow и Dagster. Оба стали своего рода стандартами в своей категории, но при этом отражают разные подходы к построению пайплайнов данных.
В статье рассказываем, какие задачи решают оркестраторы в проектах внедрения корпоративных хранилищ данных. Выясняем, в чём разница между инструментами, и почему Dagster становится всё популярнее в DWH-проектах, чем Airflow.
Роль оркестратора в архитектуре корпоративного хранилища данных
Корпоративное хранилище данных (DWH, Data Warehouse) — централизованная система, в которой хранятся и обрабатываются бизнес-данные из разных источников. Эти данные используются для аналитики и принятия управленческих решений.
Основная задача организации хранилищ данных в компании — создание хорошо спроектированного, централизованного и масштабируемого банка данных.
Зачем бизнесу нужны хранилища данных? Для этой цели недостаточно использовать простую базу данных, так как в отличие от БД корпоративные хранилища: Cохраняют исторические данные в хронологическом порядке и агрегированные значения, в отличие от БД, которые подходят только для обработки транзакций Данные в них хранятся в соответствии с описываемыми областями, а не используемыми приложениями Объединяют данные различной природы, форматов, типов, являющиеся аспектами предметной области, а не отдельных функций Для обеспечения единой версии правды и корректности аналитики данные в хранилище не создаются и не удаляются, изменения можно произвести только в источнике Транзакционные базы данных и OLTP- системы (системы оперативной обработки данных), к которым относятся ERP, SCADA, банковские системы и т.д., являются основным источником данных для хранилищ. Также данные в хранилище поступают из любых других источников структурированных данных: Excel, текстовых файлов с разделителями TXT, CSV, учетных систем 1С, API и прочих. Перенос данных из источников в хранилище и их предварительная обработка реализованы с помощью ETL/ELT-процессов. В хранилище данные распределяются на слои: Готовые для анализа данные поступают во внешние инструменты отчетности и визуализации, BI-платформы, аналитические системы. В результате получается многоуровневая слоеную архитектура LSA (Layered Scalable Architecture), где каждая из частей системы состоит из технологий и инструментов, выполняющих конкретные функции. Оркестраторы занимают центральное место в архитектуре хранилищ данных, обеспечивая управление и координацию всех процессов перемещения, обработки и загрузки данных. Оркестратор управляет полным циклом процессов: Оркестратор запускает все эти задачи строго в нужной последовательности, с учётом зависимостей и установленного расписания. В слоеной структуре хранилища LSA оркестраторы отвечают за перемещение данных между слоями Raw / Staging, Core / ODS, Data Marts, отслеживая, какие таблицы пересчитываются, и в каком порядке Оркестраторы могут отвечать за: Оркестраторы запускают и управляют ETL- процессами, которые формируют витрины данных для BI-дашбордов, запускают проверки качества данных, тесты и оповещают о нарушениях. Также оркестраторы управляют последовательностью до- и пост-обработок, обучением моделей, оценкой, бенчмарками, запускают процессы переобучения при расхождении данных, управляют деплоем моделей. Apache Airflow — один из самых известных и используемых open source оркестраторов ETL и DWH-пайплайнов. Был разработан в 2014 году и до сих пор считается «золотым стандартом» оркестрации процессов. Основная сущность Airflow — DAG (Directed Acyclic Graph) — направленный ациклический граф — набор задач, упорядоченных по зависимостям, где каждая задача может быть выполнена только после того, как завершатся все необходимые предыдущие. «Направленный» (directed) означает, что зависимости имеют чёткое направление (одна задача идет после другой), а «ацикличный» (acyclic) — что в графе нет циклов: одна и та же задача не может зависеть от самой себя, даже косвенно. DAG представляет собой Python-скрипт, который состоит из: Airflow предлагает как широкий выбор встроенных операторов, так и возможность добавления пользовательских. Начиная с версии 2.0. наряду с операторами можно использовать TaskFlow API, который упрощает создание пайплайнов. Вместо описания тасков через PythonOperator, вы описываете бизнес-логику как чистые функции. Airflow автоматически превращает эти функции в задачи DAG’а, отслеживает зависимости и обрабатывает обмен данными между ними через механизм XCom. Платформу легко встроить в любую корпоративную экосистему, так как Airflow поставляется с сотнями готовых операторов для интеграции с базами данных, облаками, API и BI-инструментами С помощью инструмента можно реализовать практически любую логику исполнения задач, включая динамические DAG’и (автоматически созданные из одинакового Python-кода) и кастомные плагины В основе Airflow — код на Python, который по умолчанию считается стандартом для дата-специалистов. Графическое отображение DAG’ов и простой интерфейс платформы будут понятны любому пользователю. Airflow имеет модульную архитектуру, поэтому легко масштабируется, подходит для работы с большими объемами данных и тысячами задач За более чем 10 лет существования сформировалось большое сообщество разработчиков, которые развивают платформу. Airflow имеет хорошо описанную документацию на разных языках Императивный подход дает гибкость и полный контроль, но с ростом числа задач и усложнением логики требует все больше усилий на поддержку, особенно при отладке или повторном запуске частей пайплайна. При изменении порядка шагов в процессе нужно переписывать связи между задачами, инкрементальное обновление тоже требует ручной реализации. Airflow оперирует задачами, а не данными или артефактами (таблицами, витринами, представлениями). DAG представляет собой структуру выполнения шагов, но не описывает, какие именно данные или структуры эти шаги создают. Это делает невозможным автоматическое определение какие таблицы зависят друг от друга, какие нужно пересчитать, и какие из них устарели. Каждая задача в Airflow создается как отдельный TaskInstance, требует коммуникации между scheduler, executor, worker и использует базу метаданных для контроля состояний. При большом количестве задач и DAG’ов возникает нагрузка на базу метаданных. В распределенных системах это приводит к задержкам в планировании, перегрузке Scheduler’а и формирует накладные расходы, особенно при частом запуске или необходимости обработки событий в режиме реального времени (меньше 1 секунды на событие). Airflow разработан для запуска задач по расписанию или по событиям с задержкой, что делает его хорошим выбором для ежедневных, ежечасных или других периодических ETL-процессов. Непрерывное потребление и обработка событий в реальном времени в Airflow архитектурно не предусмотрены. Airflow не имеет встроенной поддержки data lineage, версионирования данных, контроля целостности таблиц. Нет декларативного описания, какие именно данные производятся и от чего они зависят, что усложняет трассировку и контроль качества данных для DWH-проектов Apache Airflow остается мощным и гибким инструментом для оркестрации, но его архитектура и принципы проектирования ориентированы на опытных инженеров и зрелые инфраструктуры. Airflow не имеет встроенной модели data-lineage; для автоматического отслеживания зависимостей таблиц требуются дополнительные механизмы и интеграции. Такой подход становится ограничением для data-проектов, особенно внедрения DWH, где важно отслеживать происхождение, состояние и зависимости данных, поддерживать сценарии с высокой частотой событий или real-time обработкой. Dagster — сравнительно молодой оркестратор, публично представленный в 2019 году и созданный с фокусом на инженерную культуру обработки данных. Dagster используется в ETL, ML, BI, DWH-проектах. Основной архитектурный подход Dagster — это декларативное описание таблиц, моделей, отчетов. В отличие от императивного подхода Airflow, вы описываете, что должно получиться, а не как этого достичь. В Dagster пайплайны описываются как граф зависимых данных и состоит из компонентов: Пайплайны в Dagster описываются как зависимость активов, а не как цепочки отдельных задач, что особенно ценно в DWH-проектах, где важны структура данных, происхождение данных, повторяемость и прозрачность. Dagster позволяет описывать данные как активы (@asset), что позволяет поддерживать декларативную структуру пайплайна, основанную на данных, а не на задачах, автоматически строить граф зависимостей и отслеживать состояния и повторный запуск только устаревших активов Dagster автоматически строит граф зависимостей между активами, включая входы и выходы каждой функции, цепочки зависимости таблиц и моделей, визуализацию data lineage в интерфейсе Dagit. Происхождение данных сохраняется для каждого запуска и доступно через API и UI, что особенно важно в проектах DWH, где нужно понимать, откуда берутся бизнес-метрики и какие данные устарели Dagster поддерживает собственные механизмы валидации на уровне @asset или @op, интеграцию с Dagster expectations, где можно задавать условия, которые должны выполняться (например, «таблица не пуста», «все значения > 0»), нативную интеграцию с Great Expectations, если требуется расширенная валидация. Результаты проверок логируются, визуализируются и могут влиять на состояние активов (например, актив может отмечаться как невалидный). Dagster имеет официальный интеграционный модуль для dbt, который автоматически импортирует dbt-модели как активы Dagster, отслеживает статус каждой модели, позволяет запускать только те модели, которые требуют обновления. Модуль работает как с dbt CLI, так и с dbt Cloud. Dagster предлагает структурированный журнал событий для мониторинга, графов, логов, артефактов и истории запусков, встроенную визуализацию зависимостей между ops, assets, partitions, легкий просмотр всех ресурсов, подключений, конфигураций. Архитектура Dagster построена так, что все вычисления прозрачны, и можно отследить, какие данные созданы, кем и когда. Dagster позволяет назначать версию активам и ops (на основе кода и входных данных), отслеживать изменения кода, влияющие на выходы, пересчитывать только те части пайплайна, где изменилась логика и повторно выполнять исторические пайплайны с теми же параметрами и окружением. Решение поддерживает local, Celery, Kubernetes, Docker, Dask executors, а также конфиги и шаблоны для среды исполнения (@config, RunConfig). Механизм IOManager позволяет управлять сохранением артефактов из хранилищ (S3, DB, файловая система и т.д.) Dagster предлагает IOManager, resources и hooks для написания интеграций вручную, но это требует больше усилий, чем использование готового BashOperator, S3ToRedshiftOperator или BigQueryOperator в Airflow. Dagster — сравнительно новая платформа, поэтому примеров в продакшене, комьюнити, материалов гораздо меньше, чем у Airflow. К тому же Dagster использует декларативный подход: пользователи описывают не порядок задач, а структуру данных и зависимостей между активами. Для команд, привыкших к классическому императивному мышлению (как в Airflow, Prefect 1.x или Luigi), потребуется понимание дополнительных абстракций Dagster предлагает использовать assets, IOManager, resource-абстракции и графы зависимостей на уровне данных. Такой подход требует перестроить пайплайны, отказаться от чисто скриптовой логики, внедрить управление данными как системой, что может быть затруднительно в имеющихся проектах, особенно если архитектура построена вокруг Airflow или кастомных ETL-фреймворков. Dagster предлагает более логичный и удобный подход оркестрации для проектов, где присутствуют сложные зависимости между таблицами, модели данных, автоматические пересчеты при обновлении источников. Его модель ориентирована на данные, а не только на исполнение задач, что делает пайплайны проще для поддержки и визуализации. Dagster подойдет для проектирования DWH с нуля и обеспечит прозрачность, отслеживание data lineage, версионность и структурное управление данными. С другой стороны, если в проекте уже используется Airflow, построена инфраструктура и накоплен опыт команды, миграция на Dagster может быть затратной и трудной для специалистов. Airflow все еще остается лидером в зрелых средах и крупных компаниях с комплексной архитектурой данных и множеством нестандартных интеграций. В проектах внедрения DWH Qlever Solutions ориентируется на уникальные особенности, возможности и опыт клиента. При проектировании хранилища с нуля мы выбираем более современные, управляемые и функциональные инструменты, такие как Dagster. В ситуациях, когда команда клиента имеет накопленную экспертизу в Airflow, или по результатам оценки работ миграция потребует больших временных и финансовых затрат, мы стремимся оптимизировать текущие решения и сохранить привычный для клиента стек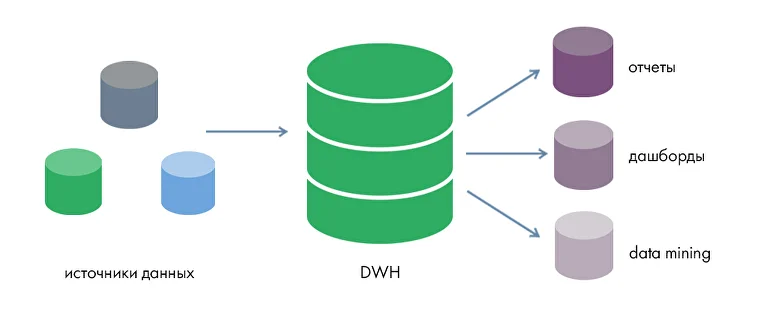

Оркестрация на уровне ETL/ELT процессов
Между слоями хранилища
В связке с мониторингом и alerting
На стыке с BI и ML
Без оркестратора невозможно эффективно поддерживать DWH
Что такое Apache Airflow: зрелость и гибкость для различных задач

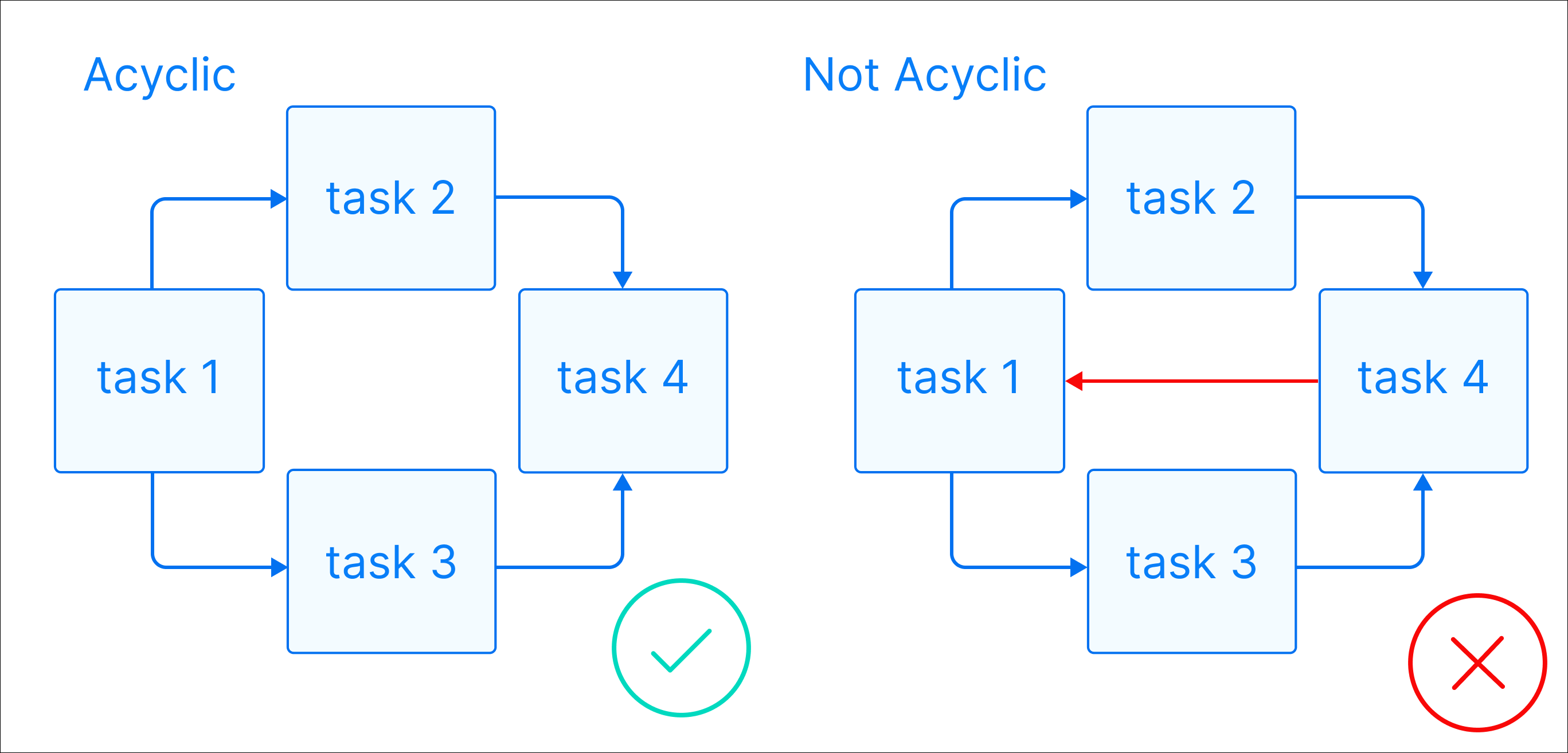
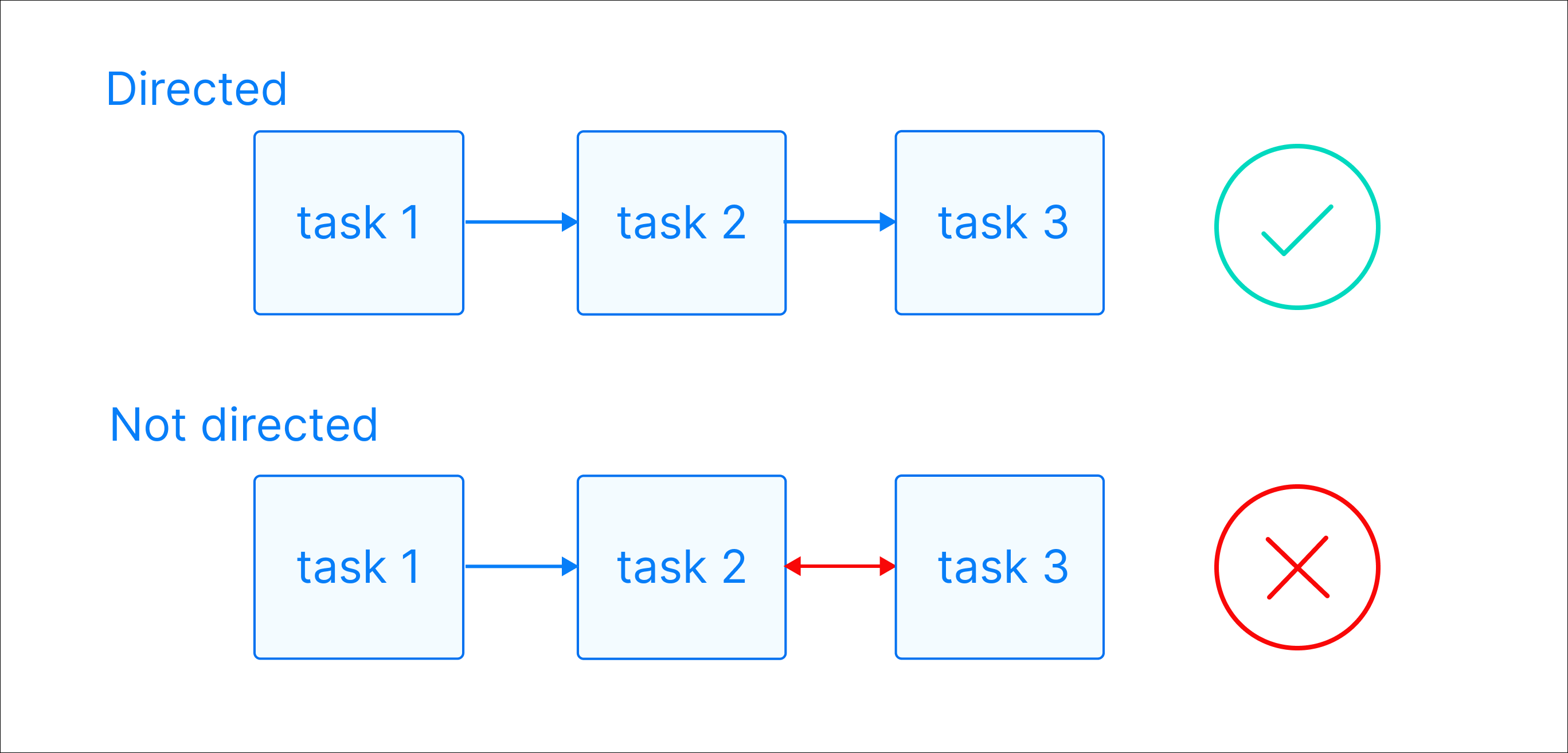
Как работает Airflow

Плюсы Airflow
Минусы Airflow
Что такое Dagster: структура, прозрачность и работа с активами

Как работает Dagster
Плюсы Dagster
Минусы Dagster
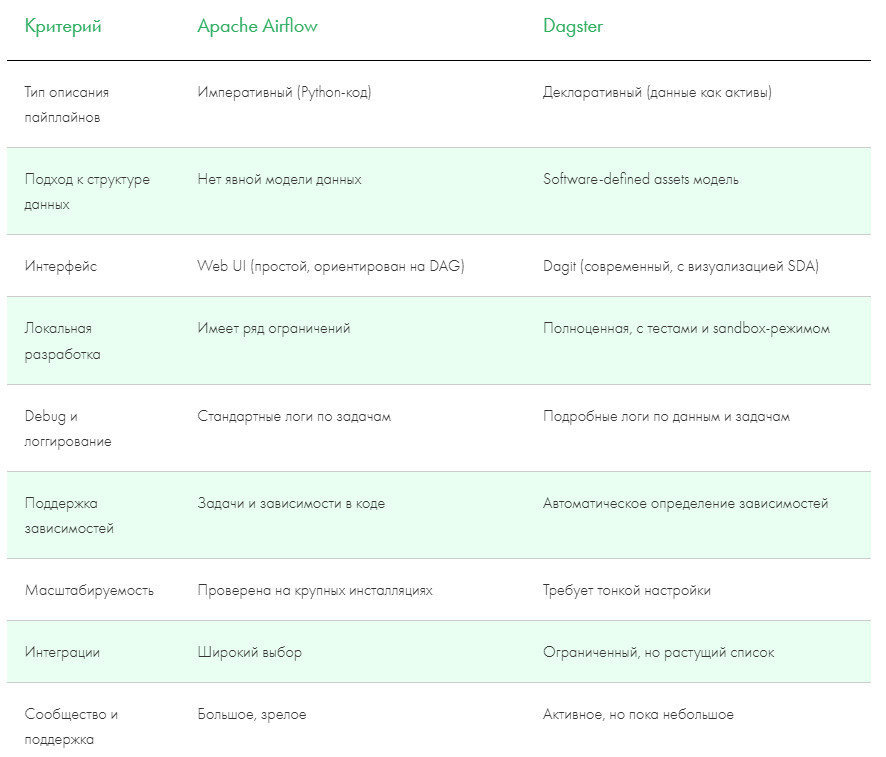
Сравнение Dagster и Airflow по ключевым параметрам
Что выбрать для DWH-проектов: Airflow или Dagster?
Проекты DWH любой сложности
