Бесплатные советы как продвинуть статью в Интернет
Задачу сформулировали так: «Какие приёмы увеличат просмотры текста в Сети». Сразу оговоримся: полагаем, что лучший способ наращивать количество читателей — писать качественные материалы. Загонять пользователей на страницу наращиванием кликбейта считаем недопустимым и аморальным.
Однако, как учёные и авторы с многолетним стажем, искренне уверены: полировка произведения перед публикацией позволит ярче засверкать тексту дополнительными гранями, увеличивая интерес и вовлечение в прочтение случайных посетителей, рыщущих поблизости в поисках вкусного.
1. Разбиение на целевые группы
В содержание текста не лезли, оставив на совесть авторов и редакторов. Анализировали параметры, на которые ведётся гость, выбирая что бы почитать на любимом портале. Для анализа выкачали со SPARK.RU и загрузили в базу данных 10’000 статей, выделив:
· количество просмотров, лайков, комментариев, ссылок, рисунков
· наименование, дату публикации, признак «Выбор редакции»
· поисковые теги и символы форматирования.
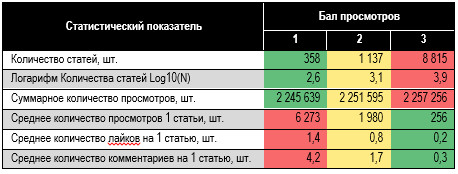
Целевой метрикой для измерения популярности материалов выбрали «Количество просмотров». Атрибут обладает неудобными особенностями: имеет числительный тип и экспоненциальное распределение. Квантировали его на три уровня: 1 — высокий, 2 — средний и 3 — низкий, назвав параметр «Бал просмотров».
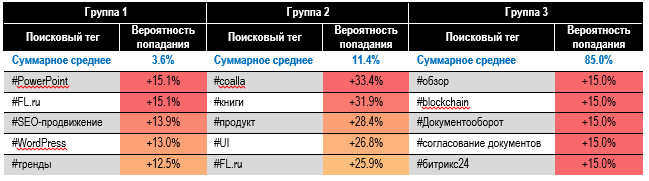
Первый бал присвоили популярным статьям, набравшим 33,3% от суммы просмотров всех статей в массиве. Второй — следующим 33,3% в порядке убывания просматриваемости. Остальным отвели третий бал. Получили неравные группы по численности (см. табл. 1), но это оказалось крайне оправданным, в чём убедимся ниже:
Таблица 1. Статистика группировки
публикаций по Балу просмотров Интересно, что 2,6% (358)
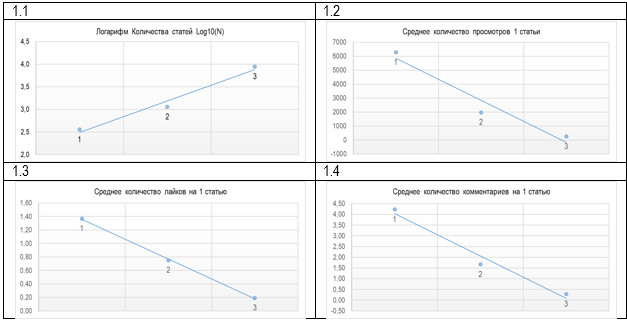
наиболее читаемых материалов дали ресурсу треть просмотров. Прологарифмировав
значение количества статей, получили практически прямую линию (см. рис. 1.1):
количество статей с высоким, средним и низким уровнями просмотров отличается на
половину порядка. Линейная зависимость
легка для моделирования и проста для прогнозирования. А установка равных границ
по сумме показателя (при экспоненциальном распределении) оправдала себя тем,
что средние показатели популярности текстов также легли на прямую (см. рис. 1.2
— 1.4), т.е. отличаются на одинаковую дельту. Рисунок 1. Соотношение
статистик популярности статей по группам просмотров Попадание в группу 1 (3,6%
наиболее просматриваемых статей) — лучший результат для публикации. Второй
диапазон (11,4% следующих по просматриваемости статей) — хороший результат,
т.к. группы 1+2 составляют топ-15% по читаемости. Третья группа — нецелевая:
желательно, чтобы ваш текст в неё не попадал. Рассмотрим зависимости,
отличающие статьи каждой из групп, чтобы сформулировать технические правила и приёмы
которые, при прочих равных, повышают шанс заинтересовать читателя своим
произведением. Знакомые с ABC анализом, могут заметить, что наше деление
оказалось похожим на используемые в маркетинговых исследованиях группы: 5%,
15%, 80%! Первый диапазон соответствует группе «А», представляющей 3,6% ценнейших
ресурсов, только не по продажам, а по читаемости. Стало понятнее откуда взялись границы 5%, 15%, 80%? Это
равное деление суммарных продаж компании в сортированном списке от самых реализуемым
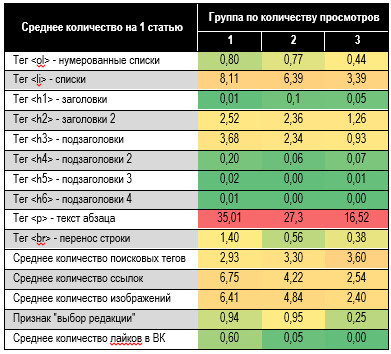
к наименее продаваемым товарам. 2. Оформление текста статьи Изучим отличие оформления
текстов на SPARK.RU по группам просмотров (Табл. 2). Обратим внимание на
динамику изменений атрибутов при переходе между группами. Разберём пример тега /ol/ (в html-страницах отображается нумерованным списком) и сформулируем рекомендации авторам по остальным атрибутам. Чем выше группа по
количеству просмотров, тем чаще статьи содержат нумерованные списки: 0.44 в группе
3 и 0.80 в группе 1. Двукратный рост! 0.77 списков на статью в группе 2
статистически незначимо отличается от группы 1, однако динамика очевидна и
группа 2 оказывается условно целевой для публикации. Сформулируем практические
правила оформления текстов: 1. В часто просматриваемых
статьях (групп 1 и 2) нумерованные списки /ol/ используются в два раза
чаще. Не стесняйтесь использовать подобное форматирование в своих текстах. Таблица 2. Статистика
форматирования текста статьи Остальные рекомендации по
табл. 2 относительно оформления текста с целью повышения просмотров: 2. «Выбор редакции» адресует
материал в первую или вторую группу по просмотрам. Атрибут с вероятностью 95% гарантирует
высокие показатели, оказавшись серебряной пулей в охоте на читаемость. 3. Популярные статьи не
показывают статистически достоверной динамики в использовании заголовков типа /h1/. Его применение не влияет на просмотры. По возможности, задействуйте
теги /h2/. 4. Подзаголовки с тегом /h4/ приветствуются. Остальные типы статистически незначимы. 5. Используйте ссылки на
другие ресурсы, изображения приветствуются. 6. Текст абзаца заключайте в
визуально отдельные блоки тегом /p/. 7. Используйте больше
маркированных списков /ul/ и /li/. 8. Отбивайте блоки текста
пустой строкой тегом /br/. 9. Лайки во ВК положительно
влияют на читаемость публикации. Влияние других соцсетей не доказано. Уровень
лайков оттуда практически нулевой. 10. Популярные статьи лучше
структурированы: содержат больше списков и абзацев, используют разное
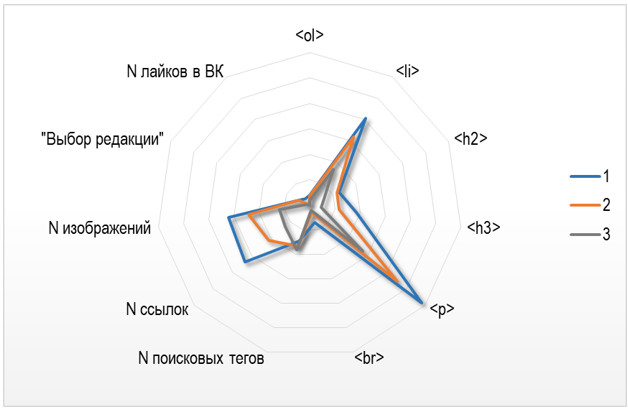
оформление для частей текста. Рисунок 1. Сравнение
форматов основного текста статей по группам 3. Название статьи От текста перейдём к заголовкам
статей. Главная строка может привлечь или отпугнуть читателя, несмотря на то,
какой текст окажется под ней. Большинство пользователей решает углубиться в
материал, основываясь только на названии, поэтому точность формулировки считаем
критически важной. По количеству слов
выраженной динамики нет. Стандартное отклонение составляет 2.5 слова: основная
масса названий колеблется в границах от 4 до 9 слов. Различия в длине заголовка
публикации как по словам, так и по среднему количеству символов в словах оказались
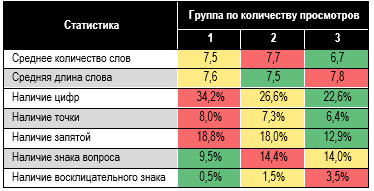
статистически не значимы. Таблица 3. Статистика
параметров названия статьи Рекомендации по табл. 3: 11 Точка в наименовании
(название из нескольких предложений) делает статьи популярнее. 12. Вопросительный и особенно
восклицательный знаки в заглавии плохи: снижают привлекательность. Повышенная
эмоциональность (экспрессия названия) отталкивает читателя. 13. Запятые (сложносочинённые
предложения) допустимы. 14. Статьи с цифрами в
названии читаются чаще. Посмотрим из каких частей
речи состоит наименование статьи. В табл. 4 приведена структура частей речи по
каждой группе просмотра. Ожидаемо, 60% — существительные, 14% — прилагательные,
13% — глаголы. По табл. 4 делаем вывод:
различия в использовании частей речи по группам нет. Советуем задействовать меньше
прилагательных и больше глаголов (есть выраженная динамика по группам), но это
правило слабое. Таблица 4. Использование
частей речи в названии статьи Мы анализировали смысл заголовков,
выделяя три значимых слова из названия. Методика расчёта важности блока текста
известна как TF-IDF (описание https://habr.com/ru/company/Voximplant/blog/446738/)
и относится к Natural Language Processing. Мы модифицировали подход,
использовав частотный словарь Национального корпуса русского языка (https://ruscorpora.ru/new/corpora-freq.html):
отбрасывали слова, встречающиеся в массиве названий статей до 40 раз, как статистически
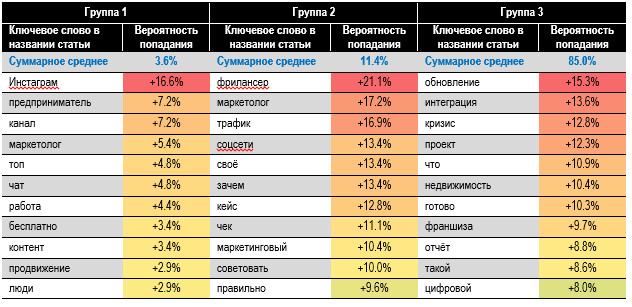
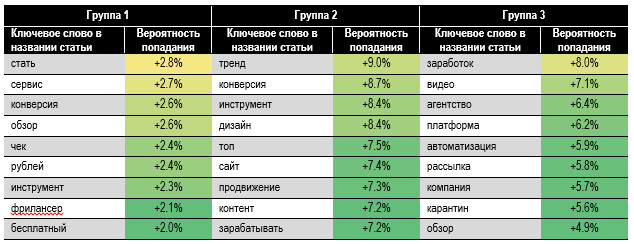
ненадёжные для выводов. В табл. 5 представлены
топ-20 ключевых слов для каждой группы по балу просмотров. Мы указали прирост
вероятности попадания статьи в группу, если в названии встречается конкретное слово.
Например, «Инстаграм» увеличивает вероятность статьи оказаться в самой читаемой
группе 1 на 16,6%: с 3,6% до 20,2%. Слово «обновление»
увеличивает вероятность попадания статьи в группу 3 на 15,3%, что снижает шансы
высоких просмотров: старайтесь избегать подобных терминов. Ударными словами в
группах 1 и 2 являются «Инстаграм» и «фрилансер» — дают самое большое
приращение к вероятности. Похоже, важные слова
наименований из групп 1 и 2 относятся больше к личным или индивидуальным
интересам читателей, а для группы 3 — это, скорее, бизнес-тема. Но это
собственное ощущение авторов. Таблица 5. Вероятность
попадания статьи в группу от наличия ключевого слова в названии 15. Включайте в название
статьи слова, дающие высокую вероятность попасть в первые две группы по
просмотрам (см. табл. 5). И избегать слов с высокой вероятностью для группы
три. Терминам заголовков присваивали
ранги: 1) по суммарной частоте просмотров и 2) по частоте встречаемости в
названиях статей. Первый характеризует насколько интенсивно читают материал с
этим словом в названии: интерес читателей. Второй — как часто пишут статью с
этим термином в названии: любовь писателей. Отрицательная разница
(дельта) между рангами указывает на неудовлетворённый «голод» по статьям с этим
ключевым словом в названии, положительная — про перекормленность темой.
Примерное совпадение рангов (дельта близка к нулю) свидетельствует о сбалансированности
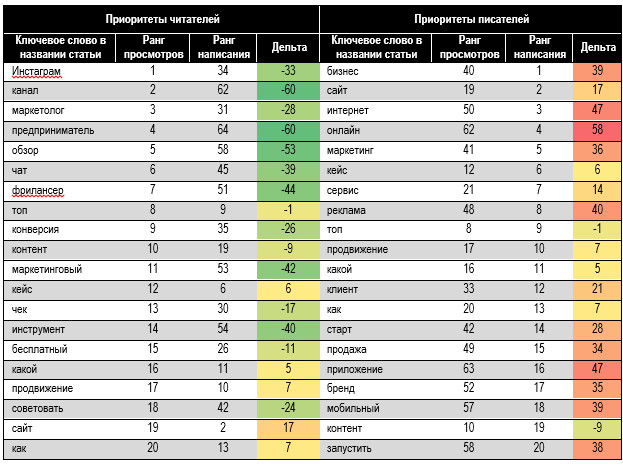
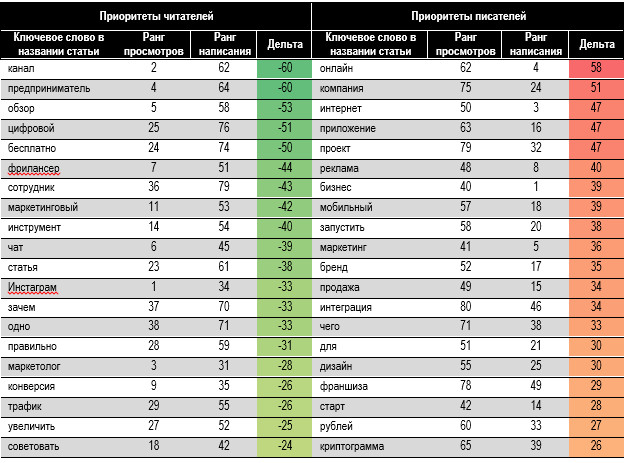
спроса и предложения по теме. В табл. 7 покажем топ-20
важных слов в названии отдельно по рангу просмотров и рангу написания статей.
Порядок ранга по просмотрам хорошо коррелирует со словами с высокой
вероятностью попадания в группу 1 из табл. 5. Ранги по просмотрам и по
написанию статей часто сильно отличаются, т.е. интересы писателей и читателей
разбалансированы. Кстати, если обратили внимание на цифры возле слов в названии
нашей статьи — это их ранги по просмотрам. Заглавие выстраивалось по
рассчитанным здесь рангам прочтения. Таблица 6. Ранги ключевых
слов в названии для читателей и писателей Существует неудовлетворённый
спрос на темы «канал», «предприниматель», «обзор», «бесплатно». У них сильно
отрицательная дельта по рангам. Термины существенно пересекаются со словами,
повышающими вероятность попадания в группу 1 из табл. 5. Это подтверждает
перспективность терминов для заголовков. Некоторые слова, заезженные
авторами, неинтересны читателям: «онлайн», «компания», «интернет»,
«приложение», «проект». Об этом много пишут, но мало читают. Не факт, что это
плохо. Возможно, темы слишком специализированы для широкого читателя. Согласно результатам
таблицы 7 на ресурсе SPARK.RU: 16. Включайте в заголовки слова,
имеющие сильную отрицательную дельту: мало пишут, много читают. 17. Избегайте тем, со словами
положительной дельты: ориентируйтесь на дефицит, а не на избыток. 18. Избегайте слов с сильной
положительной дельтой: читатель уже крайне перегружен. 19. Включайте в заголовки
слова с высоким рангом по просмотрам. Таблица 7. Самые
расходящиеся интересы писателей и читателей 4. Поисковые теги к статье Если ключевые слова в заголовки
авторы включали неосознанно, ориентируясь на ожидаемую литературную ценность,
то поисковые теги придумываются и добавляются с пониманием особенностей
использования. Авторы полагают, что
поисковые теги помогают классификации текста, а также используются поисковыми алгоритмами
для индексирования. Другими словами, ключевые слова в названии статьи —
интуитивно выраженная суть материала, где поисковые теги выражены сознательно. В изучаемом корпусе публикаций
разнообразие поисковых тегов намного выше, чем ключевых слов, входящих в наименования:
11 тыс. тегов против 7 тыс. слов. Интересный феномен! Интуитивное выражение
более скованное? Или привлечение интеллекта к формулированию сути более
«хаотично» и «разбросано»? Частично сложившееся
положение можно объяснить тем, что термины из названия проходили лемматизацию —
приведение словоформ к единому нормальному виду. Но это не могло дать 40%
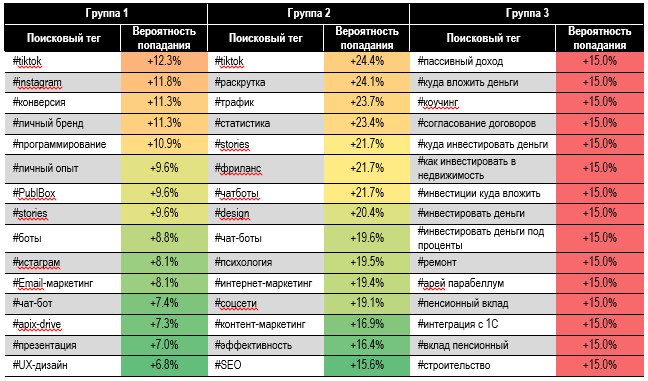
сокращения разнообразия. Нам ещё предстоит покопаться в этом глубже и отдельно. В табл. 8 представлены
поисковые теги, увеличивающие вероятность попадания статьи в определенную
группу по просмотрам. Результаты удивляют: самыми ударными тегами для попадания
в целевую группу 1 оказались «#PowerPoint» и «#FL.ru», которые увеличивают
вероятность на 15,1%. Ценными для группы 2 оказались
«#coalla» и «#книги». Если к популярности второго тега вопросов нет, то причём
здесь «#coalla» — милый австралийский медведь, намеренно написанный с ошибкой?
Оказалось, что есть агентство разработки веб-сайтов с таким названием, которое
активно публикуется на SPARK.RU. Повторение 15,0% роста
вероятности попадания в группу 3 — не ошибка. Все 100% статей с указанными
тегами гарантировано попадают в группу 3: получить высокие просмотры по ним
невозможно. В группе 1 много тегов с
названием приложений: «#PowerPoint», «#WordPress», «#PublBox» и интернет-платформ:
«#FL.ru», «#tiktok», «#instagram». Статьи с тегами про вклады и пассивный доход
не читаются: Таблица 8. Вероятность
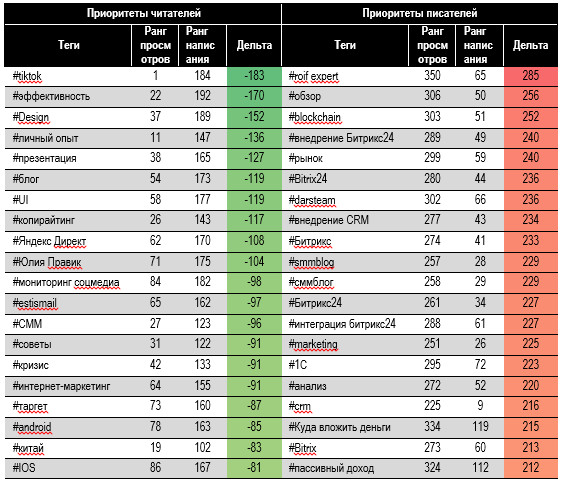
попадания статьи в группу в зависимости от указанного тега Изучим дельту рангов по
просмотрам и написаниям поисковых тегов (табл. 9). Сильный неудовлетворенный
спрос на: «#tiktok», «#эффективность», «#Design», «#личный опыт». Большое
перепроизводство статей с тегами: «#обзор», «#blockchain», «#Битрикс24»,
«#внедрение CRM». Читателям интереснее
ресурсы по личному продвижению в интернете и соцсетях, а писатели концентрируются
на темах для компаний и бизнеса: Таблица 9. Расходящиеся интересы писателей и читателей
(по поисковым тегам) Представим, статья
наконец написана, оформлена, отредактирована, оптимизирована по предложенным
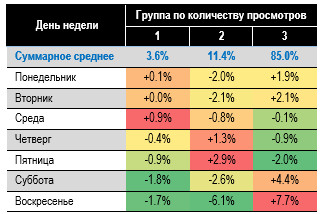
правилам. Скорее публиковать? Нет! Надо выждать момент. День недели имеет
значение (табл. 10): Таблица 10. Вероятность
попадания статьи в одну из групп в зависимости от дня публикации 20. Жаждете попадания
произведения в группу 1 — отправляйте на публикацию в среду. 21. Для группы 2 имеет смысл
рассмотреть размещение в четверг или пятницу. 22. Ни в коем случае не спешите
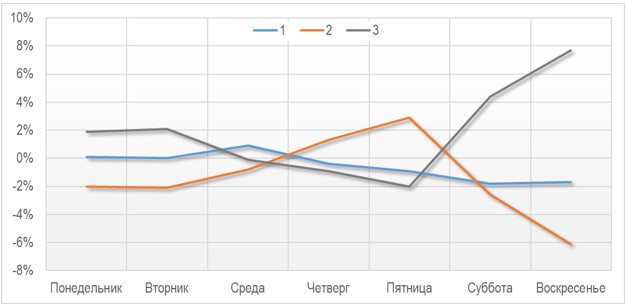
в печать в выходные и праздники. Рисунок 3. Вероятность
попадания статьи в одну из групп в зависимости от дня публикации Судя по распределению
вероятностей, целевой ресурс читают в рабочие дни. Основное число просмотров
статьи получают в первые несколько дней после публикации. Исходя из результатов
табл. 10, предположим, что SPARK.RU — не для развлекательного чтения, а экспертный
ресурс обмена профессиональным опытом. 5. Композитные правила от деревьев решений Мы рассмотрели простые
правила формирования повышенного интереса пользователей к прочтению статей в
Сети. С помощью алгоритма классификации деревьями решений можно вычислить более
действенные композитные правила привлечения читателей к тексту. Алгоритм отбирает
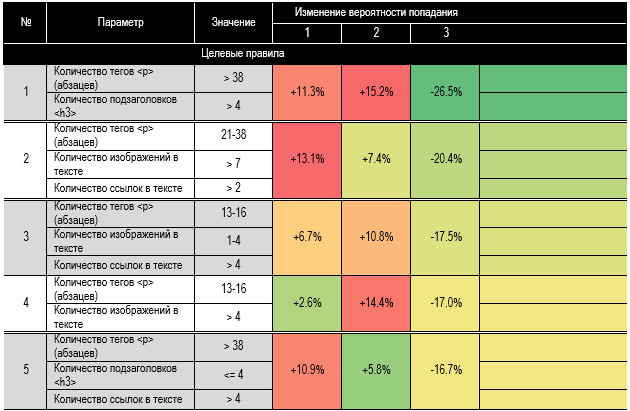
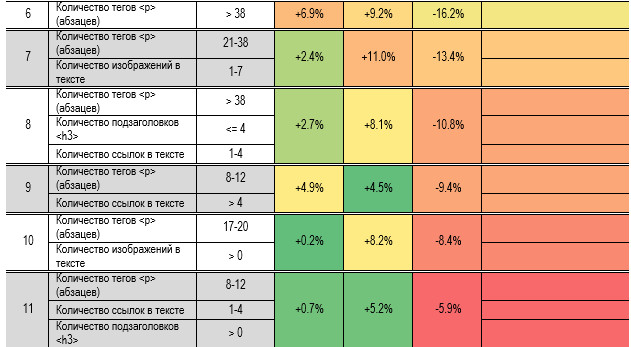
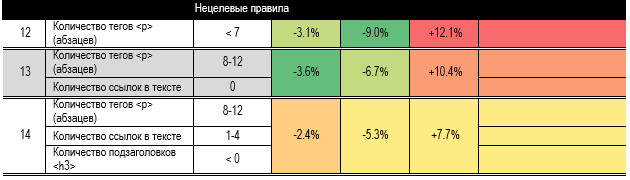
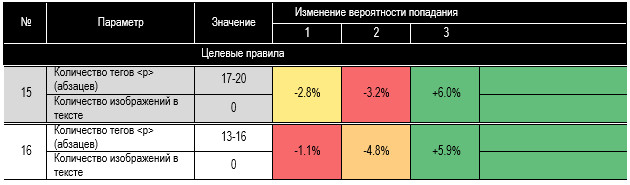
влияющие факторы и вычисляет границы для наибольшего эффекта. В табл. 11
приведены наиболее влияющие правила: в начале — целевые, в конце —
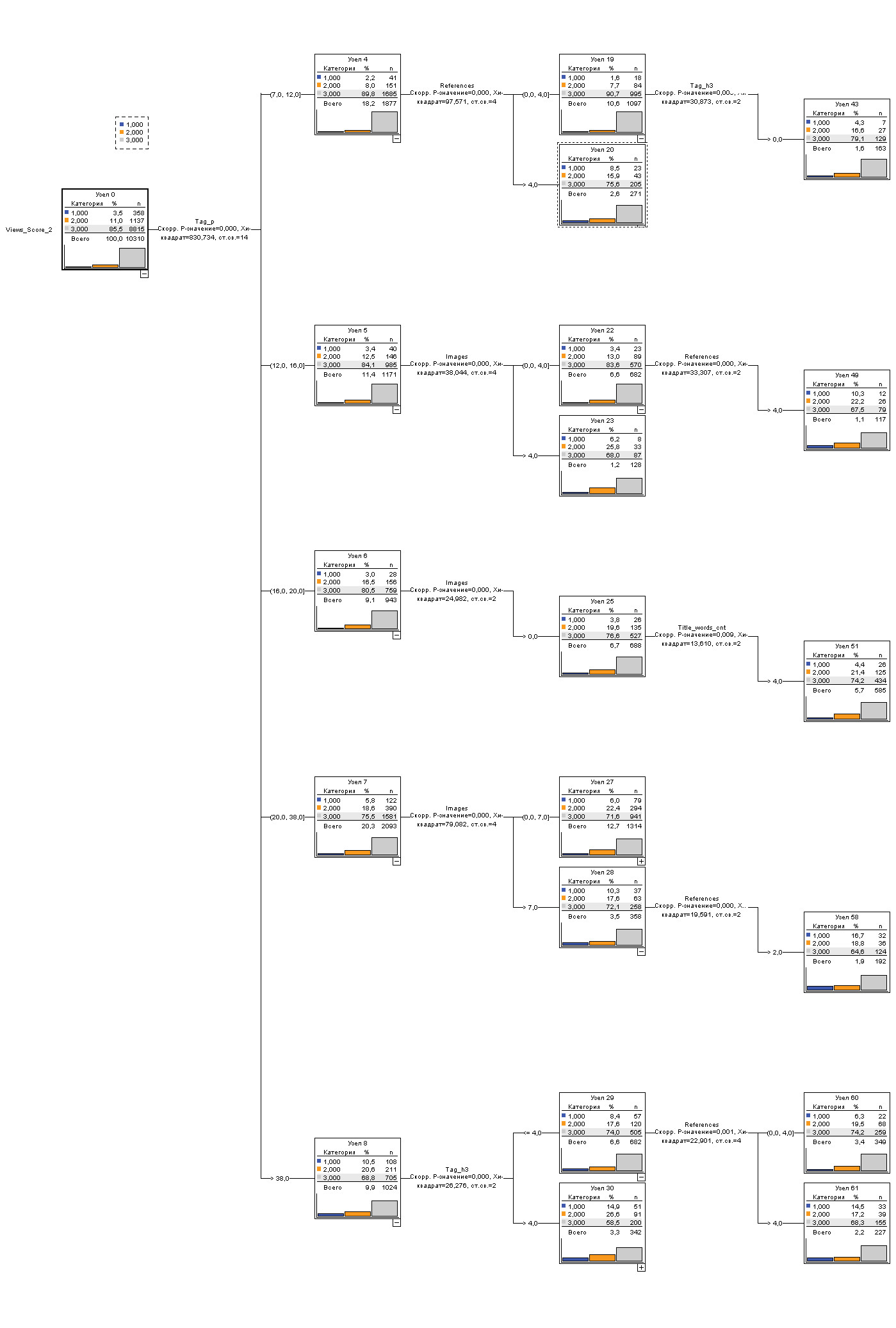
отрицательные, снижают вероятность прочтения. На рисунке 4 приводим граф дерева
решений (из SPSS) по
которому формулировали целевые правила. Например, правило № 2
звучит так: если абзацев в тексте будет от 21 до 38 и изображений больше 7 и
ссылок больше 3, то вероятность вхождения статьи в группу 1 по просмотрам
повышается на 13,1%, в группу 2 — на 7,4%, в группу 3 — уменьшается на 20,4%. Таблица 11. Наиболее
действенные правила увеличения вероятности попадания в группы читаемости Алгоритм деревьев решений не посчитал значимо
влиятельными ключевые слова названия или поисковые теги. Это связано с тем, что
группировка по ним даёт слишком малые выборки: наиболее частое ключевое слово
«бизнес» встречается 258 раз, но правило не может составлять менее 50
наблюдений. Рисунок 4. Дерево решений
поиска правил повышения просмотров Заключение В статье мы использовали 14 простых правил из 22
предложенных выше. Часть правил оказалась неприменима: выбор темы, часть не
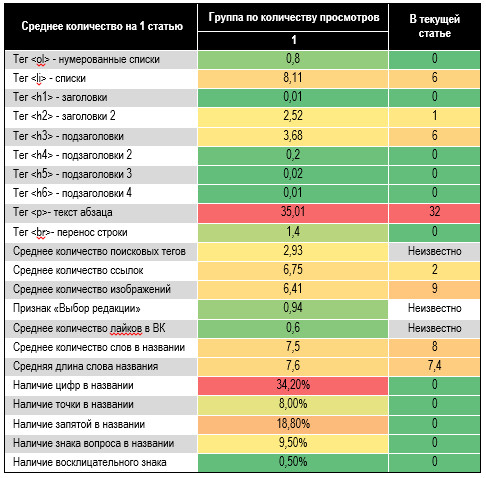
известна: день недели публикации (надеемся на четверг). В табл. 12 приведены средние технические показатели
текста статей из группы 1 и такие же показатели для текущей статьи. Уровень исполнения
оцениваем в 86%. Ради интереса, посмотрите статистику просмотров
публикации: гарантируем, что нам удастся войти в группу 1, набрав более 3’100
просмотров/ Таблица 12. Сравнительная
таблица рекомендаций и их применения