
редакции

Как поисковые системы нас понимают. Семантический анализ текста

Результаты семантического анализа могут применяться для решения задач в таких областях как психиатрия, политология, торговля, филология, поисковые системы, системы автоматического перевода и т.д.
Несмотря на свою востребованность практически во всех областях жизни человека, семантический анализ является одной из сложнейших математических задач. Вся сложность заключается в том, чтобы «научить» компьютер правильно трактовать образы, которые пытается передать автор текста.
В этой статье мы разберем, как поисковые системы извлекают из запроса его семантическое значение, метод TF-IDF и закон Ципфа. В первой части статьи вы можете узнать про основной способ обработки языка Bag-of-words, как поисковая система понимает отдельные слова и предложения и находит соответствующий документ. Читайте и становитесь настоящим гуру поисковой оптимизации...
TF-IDF и закон Ципфа
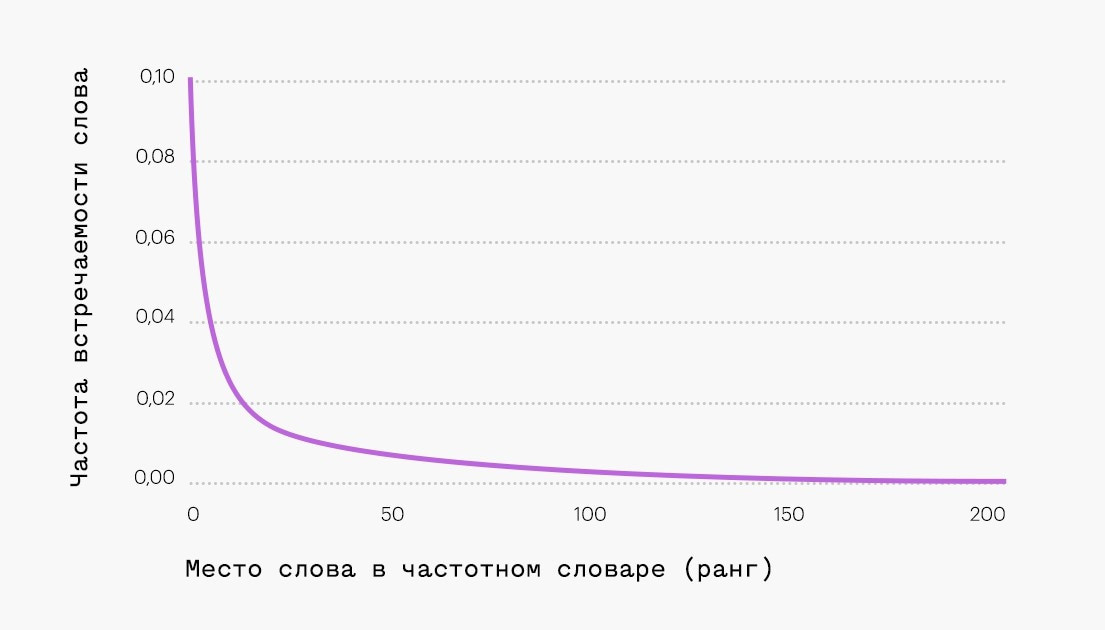
Проверка по закону Ципфа — это метод распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (так называемому рангу этого слова). Например, второе по используемости слово встречается примерно в два раза реже, чем первое, третье — в три раза реже, чем первое, и так далее. Наиболее часто используемые 18% слов (приблизительно) составляют более 80% объема всего текста.
Самые популярные слова будут отображаться в большинстве документов. В результате такие слова усложняют подбор текстов, представленных с помощью модели мешка слов. Кроме того, самые популярные слова часто являются функциональными словами без смыслового значения. Они не несут в себе смысл текста.
10 самых популярных слов в русском языке.
- и
- в
- не
- на
- я
- быть
- он
- с
- что
- а
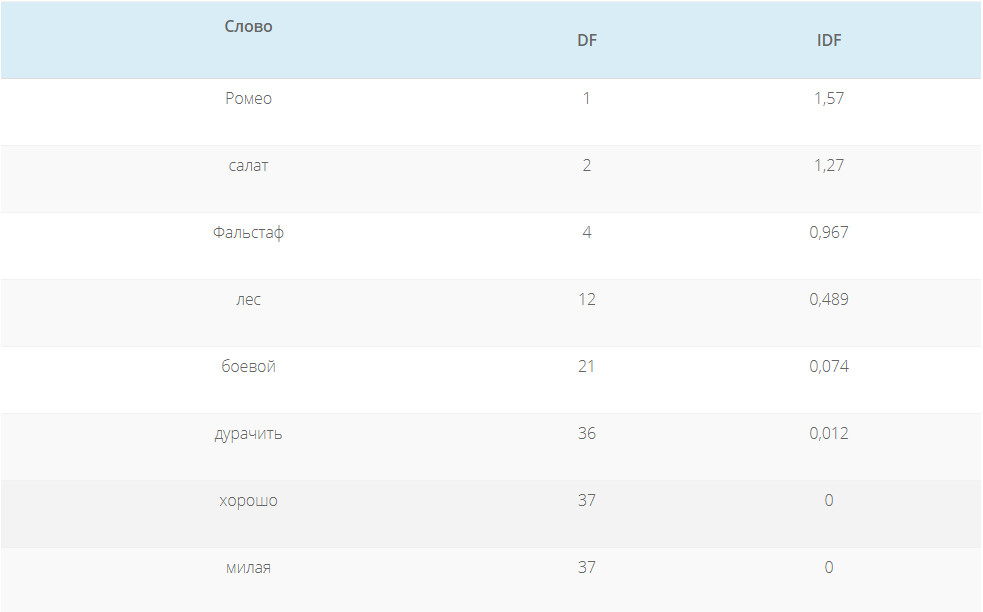
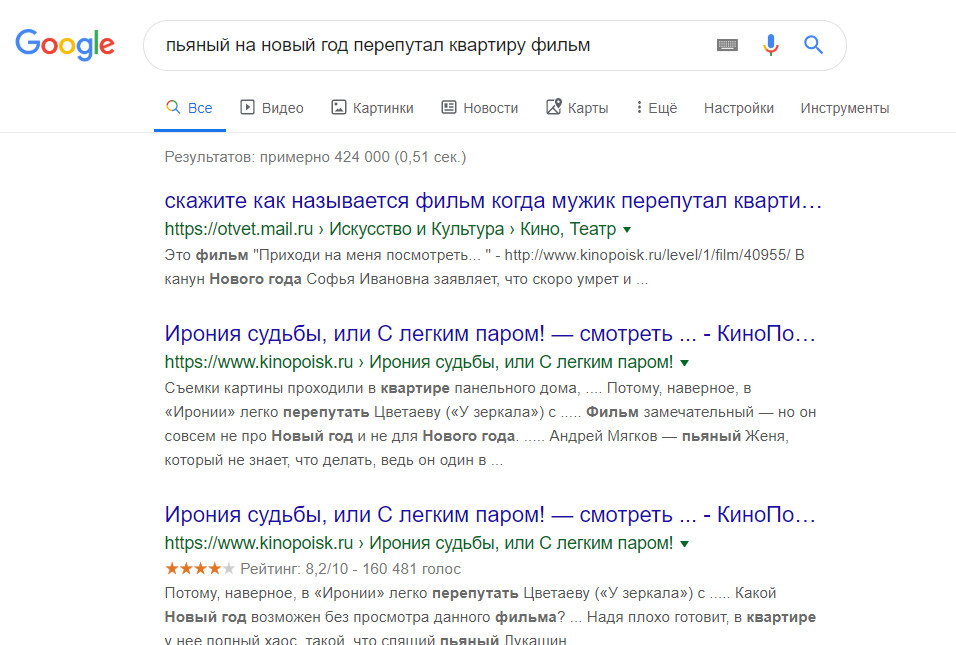
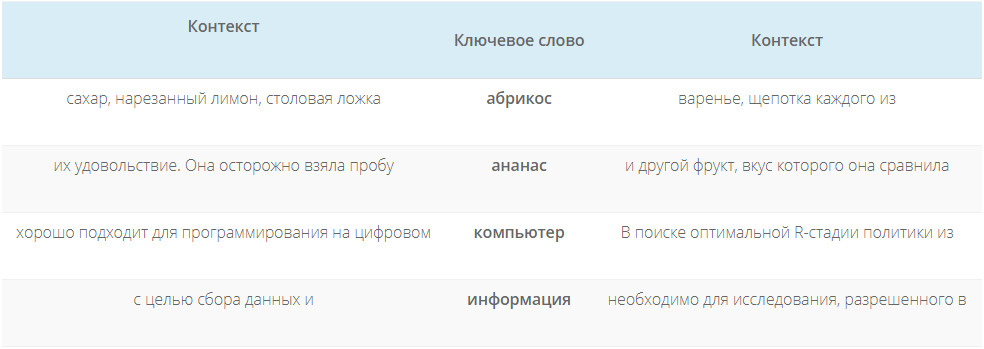
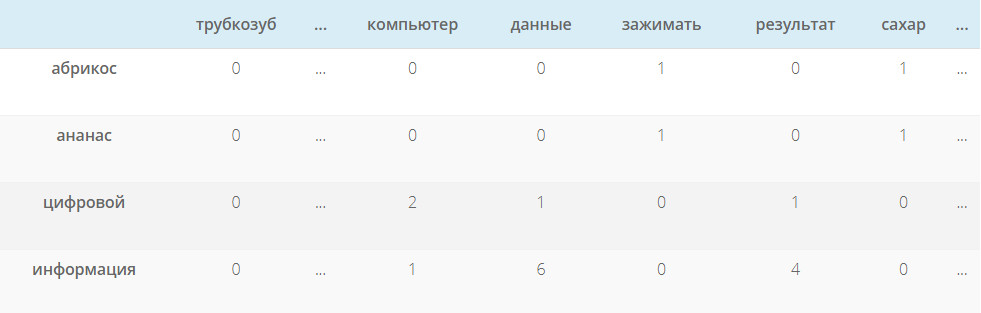
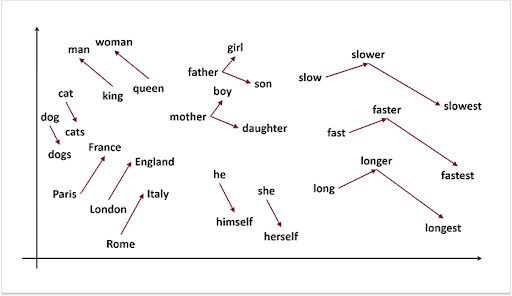
Мы можем применить статистическую меру TF-IDF (частота слова — обратная частота документа), чтобы уменьшить вес слов, которые часто используются в тексте и не несут в себе смысловой нагрузки. Показатель TF-IDF рассчитывается по следующей формуле: В таблице ниже приведены значения IDF для некоторых слов в пьесах Шекспира, начиная от самых информативных слов, которые встречаются только в одной пьесе (например, «Ромео»), до тех, которые настолько распространены, что они полностью не дискриминационные, поскольку встречаются во всех 37 пьесах. Такие как «хороший» или "сладкий".IDF самых распространенных слов равен 0, в результате их частоты в модели мешка слов также будут равны 0. Частоты редких слов будут наоборот увеличены. Семантический поиск стал ключевым словом в SEO сообществе с 2013 года. Семантический поиск — это поиск со смыслом, в отличие от лексического поиска, где поисковая система ищет буквальные совпадения слов или вариантов запроса, не понимая общего значения запроса. Приведем простой пример. Вводим запрос в Яндекс или Google — пьяный на новый год перепутал квартиру фильм. Результаты выдачи можете увидеть на фото. Вы же сразу поняли, о каком фильме идет речь? Как мы видим, поисковая система отлично справилась с задачей. Несмотря на то, что в нашем запросе нет слов ирония / судьба / с легким паром в выдаче мы видим «Иронию судьбы». Но как поисковая система может понять значение слова или смысл поискового запроса? Или как мы должны указать значение слова, чтобы компьютерная программа могла понять и практически использовать его в выдаче документов?Ключевой концепцией, которая помогает ответить на эти вопросы, является дистрибутивный анализ. Она была впервые сформулирована еще в 1950-х годах. Лингвисты заметили, что слова с похожим значением имеют тенденцию встречаться в одной и той же среде (то есть рядом с одними и теми же словами), причем количество различий в значении между двумя словами примерно соответствует разнице в их LSI-фразе. Вот простой пример. Допустим, вы сталкиваетесь со следующими предложениями, при этом не зная, что такое лангустин : Также вы определенно сталкиваетесь со следующим, так как большинство читателей знают, что такое креветка: Тот факт, что лангустин встречается с такими словами, как деликатес, мясо и макароны, может указывать на то, что он является своего рода съедобным ракообразным, в чем-то похожим на креветок. Таким образом, можно определить слово по среде, в которой оно встречается и по множеству контекстов. Как мы можем преобразовать эти наблюдения в нечто значимое для компьютерной программы? Можно построить модель, похожую на мешок слов. Однако вместо документов мы обозначим столбцы с помощью слов. Достаточно распространено использование небольших фраз в контексте целевого слова, но не более четырех слов. В этом случае каждая ячейка в модели обозначает количество, сколько раз слово встречается в контекстной фразе (например, плюс-минус четыре слова). Давайте рассмотрим эти контекстные фразы. В таблице ниже пример из книги Даниэля Джурафски и Джеймса Мартина «Обработка речи и языка». Для каждого слова в соседних колонках мы указываем тематические слова из текста, где оно используется. В результате получаем матрицу совпадения слов. Обратите внимание, что «цифровые» и «информационные» контекстные слова больше похожи друг на друга, чем на «абрикосовые». Количество слов может быть заменено другими показателями. Например, показатель взаимной информации. Каждое слово и его семантическое значение представлены вектором. Семантические свойства каждого слова определяются его соседями, то есть типичными контекстами, в которых оно встречается. Такая модель может легко уловить синонимию и родственность слов. Векторы двух одинаковых слов будут проходить рядом. Векторы слов, которые появляются в одном и том же тематическом поле, будут образовывать кластеры. В семантическом поиске нет магии. Концептуальное различие заключается в том, что слова представляются в виде векторных вложений, а не лексических элементов. Компьютерная лингвистика — это увлекательная и быстро развивающаяся наука. Концепции, представленные в этой статье, не новы и не революционны. Однако они довольно просты и помогают получить общее представление о проблемном поле. Вопросы, предложения и критика приветствуются в комментариях.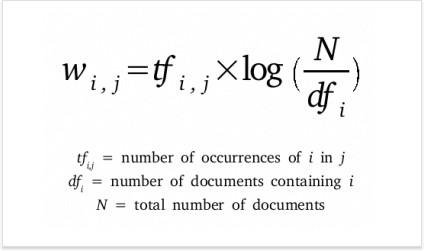
Что нужно знать SEO-специалисту
Семантические слова
Что нужно знать SEO-специалисту