

SEO-инсайты, которые можно достать из логов серверов
Супер доклад Алексея Рылко, Senior SEO-консультанта в iProspect, про SEO-инсайты из логов сервера на конференции 8P-2016.
Когда мы говорим о том, как работает поисковая система, в голову приходят три больших этапа:
1
Краулинг — процесс, при котором поисковый робот (спайдер) ищет новые страницы и пересканирует старые, но обновленные страницы. Его основная задача — в спокойном состоянии найти как можно больше сайтов и страниц.
2
Индексация — процесс, при котором поисковая система разбирает найденные документы, классифицирует их и помещает в базу данных.
3
Ранжирование — процесс, при котором поисковая система рассчитывает релевантность и авторитетность ресурса, и определяет его место в поисковой выдаче.
Чаще всего говорят про второй и третий путь, однако про первый забывают. А зря. Краулинг — это основа основ, на чем строится все остальное.
Что собой предоставляют логи серверов?
Абсолютно любое обращение к сайту фиксируется на сервере в специальных файлах — логах сервера — в виде специальных строк. Если детально изучить, что они из себя представляют, то можно сказать, что каждое посещение сайта робота и человека отображается в них полностью. Рассмотрим одну из таких строк:
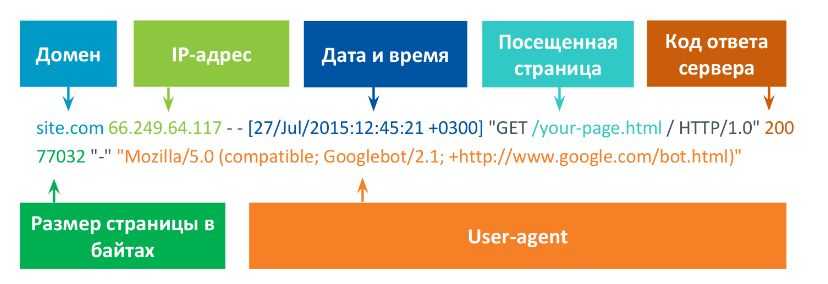
Данный пример и все последующие относятся к поисковой системе Google.
Мы видим:
- домен,
- IP-адрес, с которого был переход,
- точное время посещения запроса,
- сама страница, которая была посещена скраулером,
- код ответа, с которыми сталкиваются и роботы, и люди,
- размер страницы в байтах,
- user-agent — имя клиента, который обратился к серверу. Находится в HTTP-заголовке. Так по имени можно узнать какой браузер или робот обращался к странице.
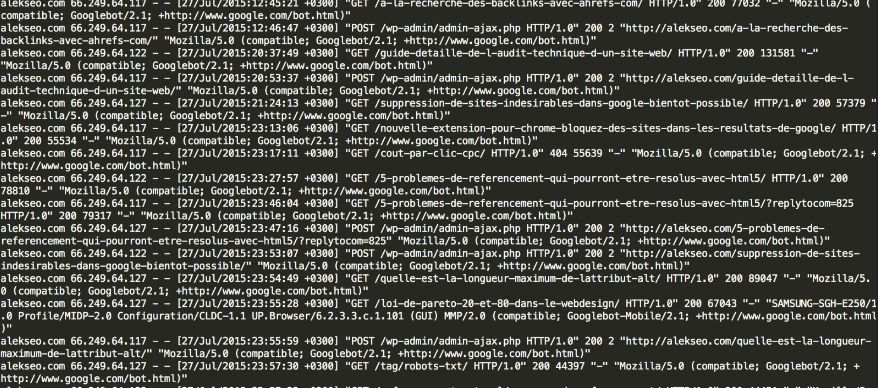
Когда происходят несколько сотен посещений, все такие строки суммируется в непонятное мессиво, которое на первый взгляд абсолютно не читабельно и неоперабельно. Оно выглядит примерно так:
Где искать серверные логи? Если логи имеются у вас на сервере, их можно найти по одному из следующих адресов:
Apache /var/log/apache/access.log Nginx /var/log/nginx/access.log IIS %SystemDrive%\inetpub\logs\LogFiles
Есть несколько видов веб-серверов (программ): Nginx, Apache и т.д.У каждого из них логи лежат в разных местах + путь к ним можно переопределить в настройках виртуальных хостов. Например, у nginx логи могут лежать в /var/log/nginx/ или /usr/local/nginx/logs/Это зависит от того, как именно он был установлен. Чаще всего, путь к логам переопределяют в настройках, эти настройки можно найти в каталоге /etc/nginx/ Лучше всего сделать поиск по всему каталогу "access_log". Это настройка, которая отвечает за путь к логам. На многих серверах её отключают для экономии места на диске.В apache ситуация аналогичная, путь к нему /etc/apache2/Только за логи отвечают настройки ErrorLog и CustomLog
Проверяем сами: что можно узнать с помощью Googlebot?
Начнем с самых базовых вещей. C тех разных гипотез и мнений, которые бывают в сфере интернет-маркетинга, которые мы хотим проверить, но не можем. И логи помогают ответить на эти вопросы. Например, можно отследить Панду по резкому падению объема краулинга.Аналитика логов сервера — самый надежный источник данных о том, как поиск относится к нашим сайтам.
Googlebot и неактивные ссылки
Существует огромная доля людей, которые ссылки ставить не умеют — они просто копируют адрес страницы, без возможности кликнуть на ссылку. Соответственно, возникает вопрос: как робот ходит по ссылкам? Может ли он их читать? Это легко узнать с помощью простого теста:
- Нужно иметь небольшой сайтик,
- использовать Google Search Console (нужно принудительно пригласить робота на эту страницу),
- и там уже посмотреть, какие страницы у нас правильно или неправильно отображаются.
Эксперимент: Я сделал обычную страничку и разместил на ней несколько ссылок. Некоторые из них были активными, а некоторые просто выглядели как текст.
Что получилось на выходе? Файл был добавлен в Search Console и робот перешел по всем ссылкам, которые были активны. Но через несколько дней в логах сервера появились такие адреса:
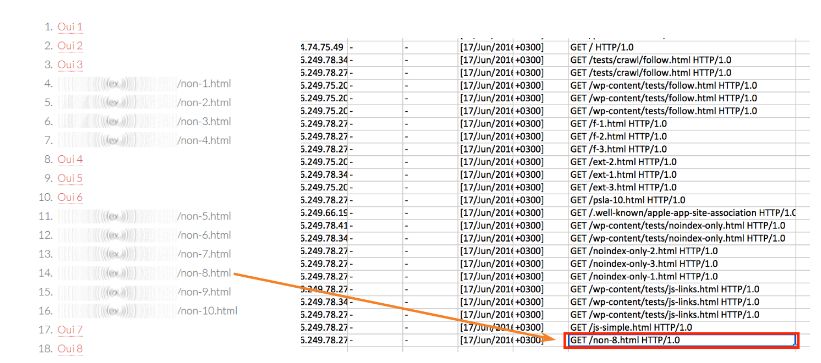
Это адреса, URL которых были указаны текстом. То есть Googlebot может видеть неактивные ссылки, и возможно они используются им для каких-то дальнейших вычислений внешних сигналов.
Googlebot и robots.txt
Файл robots.txt — это текстовый файл, который находится в корневой директории сайта и в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте и т.д. При работе с файлом robots.txt нужно запомнить важные моменты:
- Googlebot следует инструкциям в файле robots.txt.
- Googlebot блокирует доступ, но не управляет индексацией.
- Иногда Googlebot может показывать в результатах поиска страницы, закрытые в robots.txt, при том, что он никогда их не посещал и не индексировал.
Поясним третий пункт подробнее.Нередко случается, что многие страницы, которые мы закрыли robots.txt, могут встречаться в результатах выдачи. В заголовке сниппета указано не то, что мы писали в Тайтле, а в описании отмечено, что не возможно его показать по ограничению файла robots.txt

На самом деле в справке Google говорится, что такое случается. И это нормально. Все дело в том, что Googlebot может видеть страницы, которые закрыты инструкциями robots.txt, но не может переходить на них. Он использует внешние сигналы — анкоры внешних ссылок, которые ведут на нашу страницу в robots.txt. То есть он показывает пользователю, что этот файл существует, но не может к нему постучаться. Он лишь отображает заголовок страницы, который он высчитал из анкоров входящих ссылок и говорит о том, что страница закрыта в файле robots.txt. И сохраненной копии такой страницы нет.
4. Ошибки в названии файла, в инструкциях, в хронологии
Начинающие seo-специалисты считают, что когда робот приходит на наш сайт и посещает каждую страницу, он обязательно перед этим будет проверять открыта ли страница в robots.txt. Но это не так.
Пример: Если мы посмотрим срез по одному проекту с посещаемостью около 100 000 в день (сайт по недвижимости), то увидим посещаемость страниц robots.txt. Их примерно от 50 до 100 в день.
Фактически это обычная страница и все директивы, которые были указаны, учлись. Когда вы обновляете сайт в robots.txt, ее также нужно добавлять через Search Console на принудительное сканирование. Часто начинающему специалисту приходит такая задача: на сайте обнаружено большое количество мусорных страниц, и их нужно удалить.
Что он делает? Он берет весь возможный арсенал средств, сначала закрывает страницу в robots.txt, размещает метатег , а потом начинает удивляться: почему некоторые страницы все еще остаются в индексе.
А это случилось потому, что возник конфликт: с одной стороны мы говорим, что страница не в индексе, с другой стороны мы блокируем доступ робота к этой странице. Фактически Googlebot не увидит того содержания документа. Поэтому для того, чтобы избавиться от мусорных страниц лучше всего использовать директивы meta name="robots". Робот все просканирует, узнает, что нужно выкинуть, а вы потом добавьте это в robots.txt.
Задача: удалить из индекса много ненужных страниц.
Частая ошибка: robots.txt + meta name="robots" "noindex".
Правильный вариант: meta name="robots" content="noindex", убедиться, что страницы не в индексе, а потом robots.txt.
Googlebot и адреса с решеткой
В SEO-среде часто обсуждают вопрос: переходит ли Googlebot по URL с хешем (#) — "якорным ссылкам". Эту информацию, как и все выше сказанное, можно проверить в логах.
Эксперимент: я создал страницу со следующими "типами" ссылок:
- Ссылка с решеткой, которая стоит в одиночку и указывает на отдельной место нашей страницы.
- Ссылка с решеткой и восклицательным знаком.
Что получилось на выходе? Все, что после хэш # в URL точно не распознается гуглботом, а может быть распознано только если хэшбэнг #! Google преобразовал страницу следующим образом: вместо #! добавил ?_escaped_fragment_=/
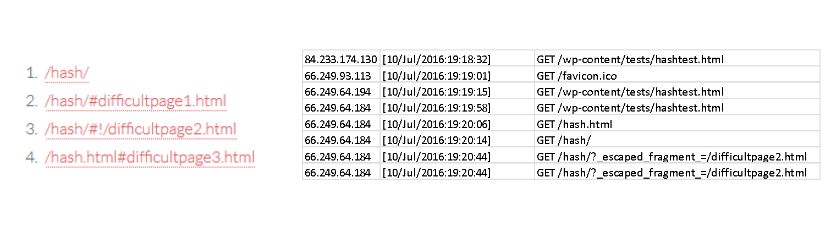
А случилось это потому, что 6 лет назад в отношениях между серверами и роботами поисковых систем было принято соглашение. Когда контент на странице обновляется без перезагрузки, то робот ПС не сможет его найти. Роботу нужны отдельные URL. Чтобы дать отдельные URL при использовании ajax, серверы и роботы поисковиков договорились, что Google будет добавлять ?escaped_fargment в URL и по такому можно адресу получить контент страницы. Использование ?_escaped_fragment_ все еще работает при сканировании объектов документа, но уже не рекомендуется Гуглом с октября прошлого года.
Что такое краулинговый бюджет и куда он уходит?
Не так давно Google опубликовал у себя на сайте интересную информацию о том, как работает его поиск. Он в частности указал, что интернет сегодня состоит из 60 000 000 000 000 страниц. Перед всеми поисковыми системами стоит очень сложная задача — находить и поддерживать эти страницы в актуальном состоянии. А это значит, для того чтобы робот Google посещал хотя бы раз в три месяца каждую из этих страниц, он должен каждую секунду сканировать 77 млн страниц. Это очень сложная задача, поэтому был введен так называемый краулинговый бюджет.
Краулинговый бюджет — процессорное время, выделяемое поисковой системой для сканирования определенного сайта за единицу времени. И основной фактор влияния в нем является эффективность документа.
В наших руках — руках каждого оптимизатора, правильно распределить микроквоту, которая дается нашему сайту.
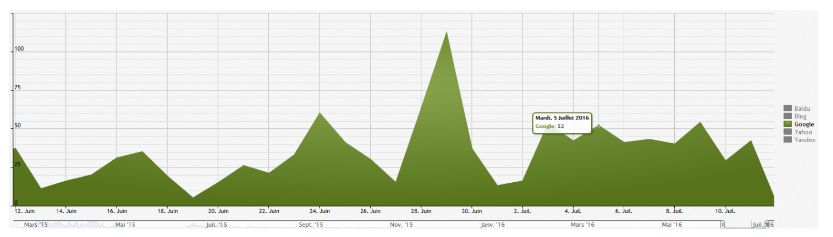
Пример: Вот это проект крупного сайта по недвижимости. Все, что обозначено красным на графике — это бесполезный краулинг (то есть краулинг, который не приносит ни одного визита нашему сайту). Синяя полоска — краулинг полезный.
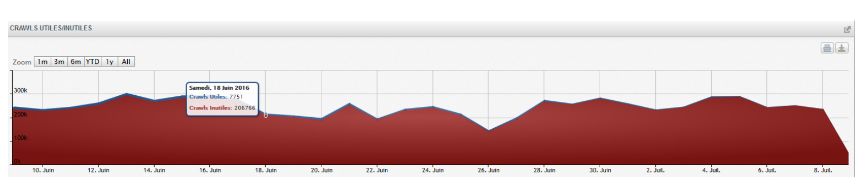
Все, что входит в бесполезный краулинг — это ошибки сайта: 404 ошибки, редиректы. Так как наш бюджет расходуется на страницы, которые не приносят реальных визитов, "хорошие" страницы этот бюджет недополучают.
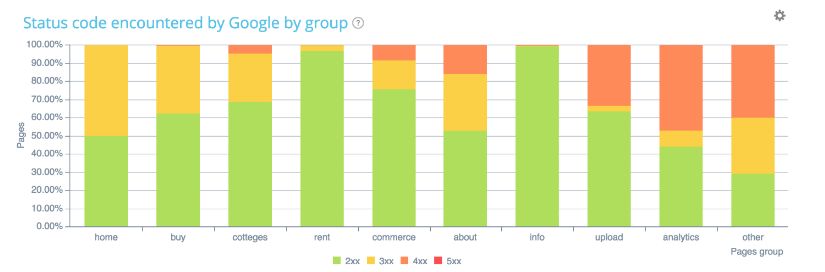
Еще один пример: Это снова сайт по продаже недвижимости. Допустим, на данном этапе продвижения для нас очень приоритетным является раздел "Аналитика". Однако из всего числа страниц, который содержит этот раздел, робот краулит только 41%.
Есть и разделы, которые получают его незаслуженно много. Например, этот раздел сайта продажи автомобилей "Шины и колеса" (коричневый цвет на графике):
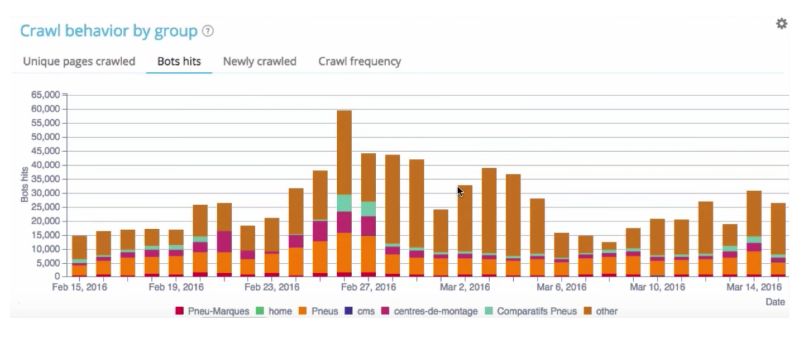
1.Совпадают ли ваши приоритетные зоны сайта с предпочтениями робота Google?
Чтобы узнать сколько страниц у вас на сайте, нужно просканировать сайт специальной программой-краулером. Но будет ли она отражать ту информацию, которую знает пользователь? Ответ — нет. Здесь важно сопоставить: что знает о вашем сайте поиск, а что знает программа.
На примере крупный онлайн-ритейлер (~10 млн переходов из поиска в месяц). У сайта есть пять миллионов страниц, которые были найдены в результате сканирования сайта самостоятельно. Но есть еще 12 миллионов страниц, о которых почему-то знает робот. Такие страницы-называются страницами-сиротами. И их нужно анализировать.

2. Страницы-сироты
Откуда они берутся?
- Страницы, на которые ведут внешние ссылки, но нет внутренних.
- Страницы с исправленными ошибками, но в базе Googlebot.
- Более неактуальные страницы с кодом 200OK.
- Оставшиеся после переезда страницы.
- Ошибки в rel=«canonical» и sitemap.xml.
3. Активные страницы
Кроме того, нужно анализировать и активные страницы. Активные страницы — это страницы, которые принесли хотя бы 1 визит из органического поиска за заданный период (30-60 дней). Как их анализировать?
На примере интернет-магазин по продаже игр (1 млн переходов из органического поиска). Разложим визиты Гуглбота по категориям слева, а справа все посещения, которая дала категория.
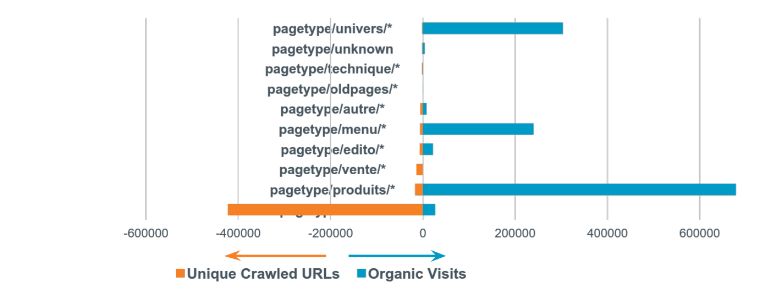
Страницы результатов внутреннего поиска были просканированы роботом Google 423 000 раз, принеся только 26 000 SEO-визитов. Получили результаты поиска по сайту, который расходует весь краулинговый бюджет и все ресурсы робота. Многие страницы дают нам очень мало. И это большая проблема.
Как оценить эффективность разделов сайта и над чем работать в первую очередь?
Можно отслеживать эффективность сайта и расставлять приоритеты по его страницам. Например, на этом графике видно, что у раздела "Аренда" (rent) есть 289 активных страниц (отмечено красным) и 2 678 неактивных страниц (отмечено коричневым).
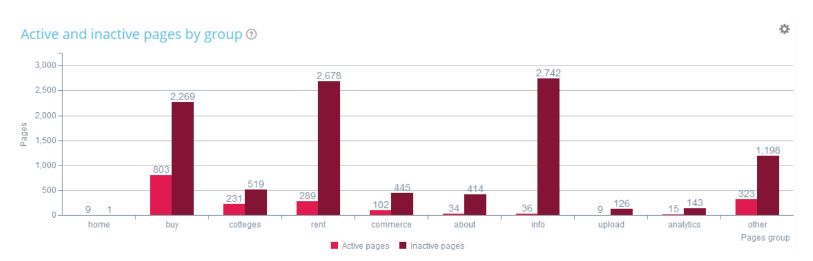
Что с ними делать? Можно дополнительно оптимизировать или вообще закрыть от идексации полностью. Главное — расставить приоритеты.
Какого объема контент нам нужен на странице?
Чтобы ответить на этот вопрос можно изучить топ по конкретному запросу и вывести среднее количество символов среди лидеров тематики. А можно узнать это у логов серверов. Например, это проект по продаже автомобилей.
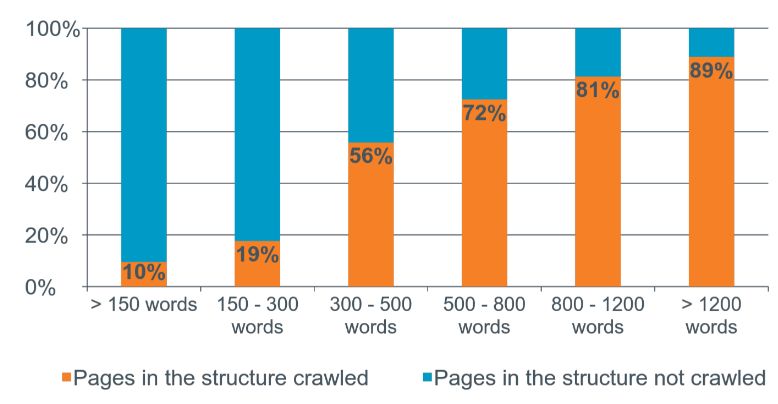
Здесь мы видим, что страницы, которые имеет меньше 150 слов на странице краулится роботом реже всего. А страницы с текстам свыше 1200 слов крауляется в 89% случаев.
Краулинг и скорость загрузки
Скорость загрузки — это очень важно для сайта. Она напрямую зависит от того, как робот посещает и сканирует наши страницы. Масштаб этого улучшения будет более глобальный, чем любые другие изменения, которые вы проведете на сайте. Эксперимент:
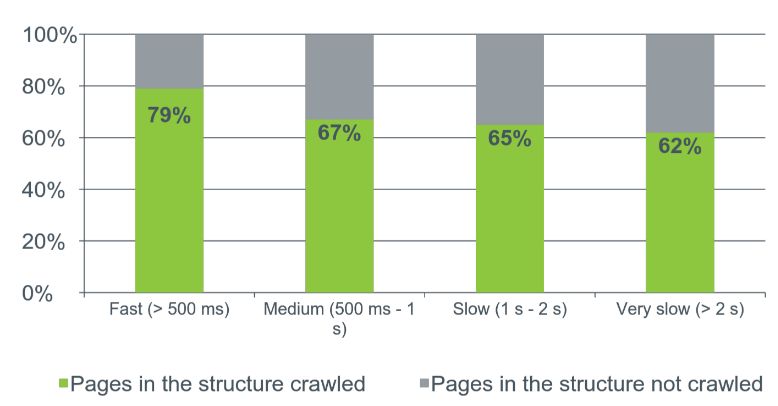
Страницы, которые загружаются быстро — быстрее чем 500 мс имеют процент краулинга 79%. А страницы, которые загружаются медленно — больше 2 с процент краулинга снижается до 52%
Глобальные тренды в поведении Googlebot'а
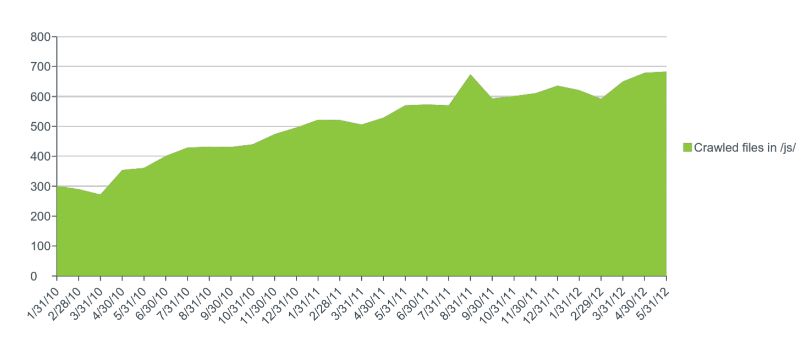
Логи также помогают выявить глобальные тренды в поведении поискового робота. Например, можно проследить тенденции поведения гуглбота. На слайде видно, что Гуглбот чаще начал обращаться к файлам javascript. Это связано с важностью анализа ботом удобства версий для мобильных устройств.
Отслеживаем эффект от своих действий
Если мы возьмем активные страницы как за KPI —основной показатель эффективности, то сможем понимать эффективность всех изменений, которые мы делаем на сайте. Влияют они как-то на улучшение показателей страниц или нет. Можно с легкостью фиксировать:
- рост и падения;
- сработали ли изменения;
- успешно ли прошел переезд;
- повлияла ли перелинковка и т.д.
И напоследок:два подхода в работе с логами серверов
Существует два основных подхода в работе с логами серверов:
Аудит
- Логи за 30-60 дней (размер и тематика). Берутся логи за месяц или за два и делается срез — смотрится, какие проблемы выявлены за этот период.
- Кросс-аналитика: Краулинг + Логи + Google Analytics. К логам всегда подключаются данные краулинга — сканирования сайта, и GA.
- Диагностика полезных и бесполезных страниц, зон сайта, о которых Google знает и нет.
Мониторинг
При мониторинге нужно загрузить в разные системы обработки данных ваши логи за каждый день и настроить оповещения об ошибках, росте и уменьшении объемов краулинга, атаках, а также сканировании новых страниц. Мониторинг обязателен при редизайне / переезде сайта — сразу можно увидеть как изменения повлияли на сайт. Существует следующие инструменты для работы с логами, некоторые из них платные, а некоторые бесплатные:
Подведем итог
1. Логи сервера — самый надежный и точный источник информации о поведении поисковых роботов.
2. Изучение логов позволяет проверить многие гипотезы, мифы, особенности работы поиска.
3. Полезный источник информации для поиска точек роста, применения усилий, проверки своей работы.
4. Неограниченные возможности по внутрисайтовой кросс-аналитике. Например, можно сопоставить страницы, посещаемые роботом Google со страницами, приносящими доход.
5. Для тех, кто хочет идти дальше:
- Оценка ссылочных кампаний на основе роста краулингового бюджета и частоты краулинга.
- Определение наложения антиспам фильтров типа «Google Panda».
6. Появилось много инструментов для удобной работы с ними. Можно легко подобрать под свои задачи и бюджет.
Источник: https://serpstat.com/ru/blog/seo-insajdi-kotorie-m...