
Modeling and development of tools and technology for searching for documentary information
In the tasks of information retrieval, two components are qualitatively distinguished: conceptual and technological.
The conceptual components include, first of all, systems for representing the actual information (knowledge), as well as means for presenting information about the information being processed, which are used as the basis of both the information retrieval mechanism and the organization of user interaction processes with AIPS. . Technological components include user interface tools, information processing, indexing and search algorithms, integration of information from various sources, query languages, etc.
From the point of view of the «intelligence» of search tools and depending on the nature of the information (and the developer’s capabilities), one of the following search technologies can be used as the basis for a specific, respectively, more or less complex AIPS: literal search — substring search that occurs without involving knowledge about the lexical, grammatical and semantic structure of the processed material; search, during which lexical and grammatical information is used, that is, linguistic dictionaries, programs for morphological text analysis are involved; semantic search, carried out on the basis of knowledge about the relationship between the concepts of the subject area (SbA), expressed by means of natural language words.
In the latter case, the carriers of this kind of information, in particular, are thesauri, which have been used for information retrieval for more than three decades. In addition, a huge role in organizing the dialogue between the user and the information retrieval system is played, although less complex, but diverse vocabulary structures. Using them, the user can develop the search by modifying the request (the expression of his information needs) according to the features of the representation of the search object by means of a particular IS and database.
1.1. Information in the systems of the main and information activities
User interaction with a complex of heterogeneous information resources should be considered as a process that depends on two groups of main factors. On the one hand, these are the properties of information and the patterns of information transformations in the field of core activity (OD), taking into account the specifics
perception and processing by a person of both basic (target) information and technological information, which provides the conditions for its interaction with the information environment. On the other hand, the organization of the information space should be considered as a task of such IR management, in which the user’s personal LIS would allow working with them as a single resource, which is necessary based on resolving the issue of identifying resources, and at the level of information consumer — associated with the problems of developing interfaces and access tools that provide personification of the presentation of information objects.
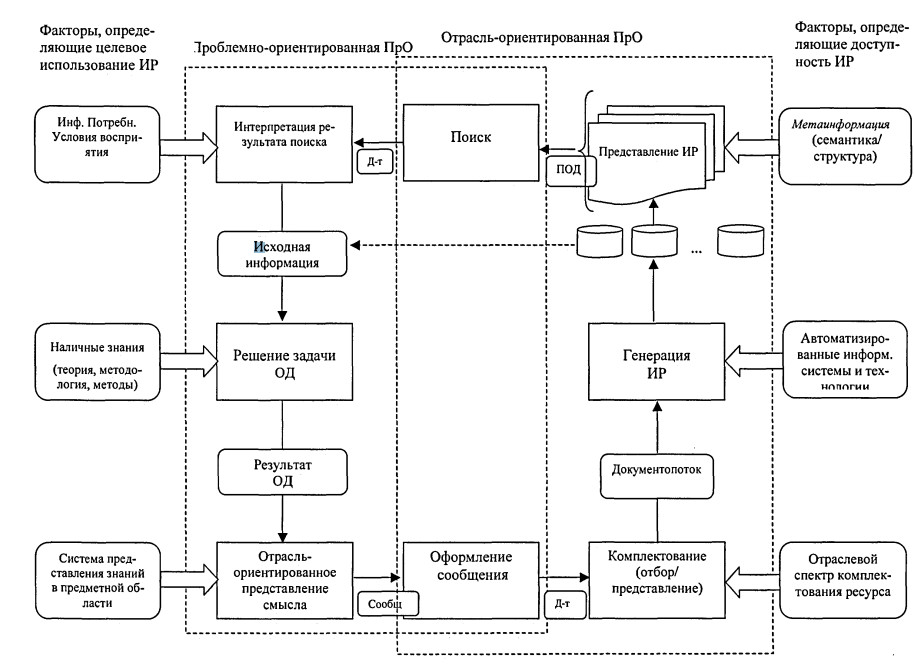
Let us consider the proposed generalized information reproduction scheme, which is based on the representation of an aggregate information system (generator — consumer of information), which determines, in the context of the interdependence of the main and proper information activities, the studied objects and automation processes
From the point of view of flow management tasks, two sets of processes can be distinguished here: the formation of a flow of information (documents) in accordance with the given characteristics (topics, completeness of coverage, etc.) and the distribution of input and output flows and their components in accordance with with information needs. And, if the main activity deals with the receipt and meaningful processing of scientific information (i.e., messages describing some properties of the object under study), then the scientific information activity is, if possible, invariant with respect to the meaning of transforming the text into a form acceptable for : automated identification, storage and retrieval.
The result of the main activity is usually embodied in the form of a message — a document that implements the transformation of meaning into text. Such «materialization» of «ideal» knowledge provides a unified form of alienation, and due to the relatively low cost of replication, it significantly expands the scope of potential consumers. On the other hand, as an inevitable contradiction, the low cost of publication (compared to the cost of obtaining the result itself) leads to a colossal and ever-increasing volume of publications, and the unification of the presentation method causes the external impersonality of messages. In addition, in order for the published message to become a stimulus in the main activity, the subject that perceives the message must also perform semantic transformations: i.e., the message must be perceived (highlighted
among others), understood (the meaning is highlighted) and actually or potentially applied (that is, at least inscribed in the system of available knowledge).
Accordingly, to ensure the effectiveness of «recognition» — the first phase of use, messages must have «signal» features. Such features can be formed, for example, according to the «genus-species difference» scheme, i.e. by introducing an explicit systematization, which is quite natural — scientific knowledge is always systemic, because are created within the framework of some system of concepts of the corresponding branch of knowledge.
A characteristic feature of the circuit shown in is the cycle-personality of reproduction: the objects that form it are the results of purposeful activity, and the purpose of their creation is to use them themselves to obtain new results. This predetermines the «naturalness» of the existence of information activity, which aims at such a transformation of the information environment that would ensure its full and effective use in the process of knowledge reproduction. Moreover, it should be noted that such transformations can be either direct ordering of messages, or their «virtual» ordering — the creation of additional (reference) information messages (for example, thematic rubricators, classifiers, thesauri, etc.) that provide al- alternative «direct» entries into the set of messages related to the problem being solved.
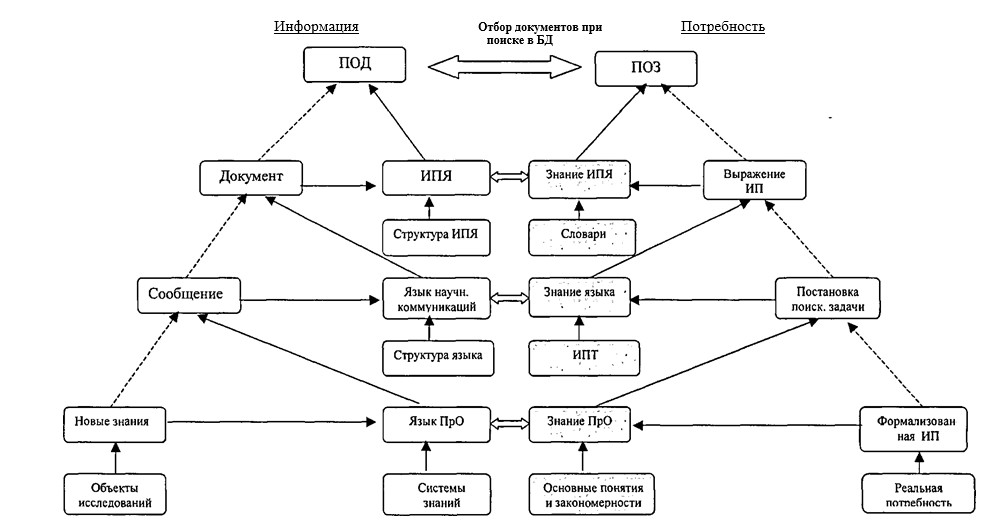
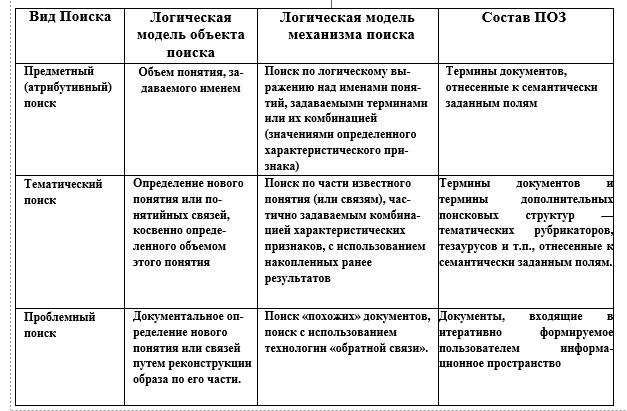
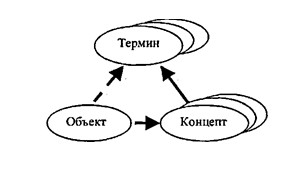
To determine the requirements for LO — the main means of both identifying semantic objects and supporting user interaction with AIS, we will consider it as a set of systems that allow us to represent (identify) both flows and arrays of information, as well as individual documents and queries ad -quate to the nature of the need and the cognitive state of the user. By the nature of the presentation of information in the aggregate system for the main objects presented in fig. 1.1, three levels can be distinguished. The first level is the main activity, where the objects are objects of the real world, and the results are new knowledge. The information carrier of this level is the human consciousness, which is characterized by a systematic organization and associativity of the sample, and the communication object is a message — knowledge, addressed to the system of concepts of the intended receiver — the consumer of information. The second level — the creation of socially useful information — is one of the forms of materialization of knowledge through the socialization of results in documentary form. The means of representing knowledge (communications) here is language, and the carrier is a document as a functionally oriented message that structures information and identifies it, for example, by highlighting logical or physical parts — semantically homogeneous fields. The third level — the actual information activity — management of information flows to ensure the main activity. Work with compact secondary documents that allow you to improve the process of finding the right messages. Here, the information (search image of the document) is a well-structured material that compactly and substantively reflects the content of the document, and also ensures the identifiability of the document as a whole and at the level of individual data elements. To determine the relationship of information objects, we use the concept of «information», which is represented as a reflection, the result of ordering and limiting the diversity of descriptions of OD objects and their relationships (in the real world) in accordance with the requirements determined by the capabilities of the representation means (description language). It follows from this that the use of abstractions of various orders ultimately makes it possible to represent objects (simplifying the description of an object of one semantic level by introducing objects of another level) using a finite number of terms. The ratio and nature of the relationship of information objects, forms and means of their representation, considered in the context of the tasks of information support for the main activity, are shown in fig. 1.2. Information Selection of documents in case of need searching in the database Rice. 1.2. Level model of the relationship of information objects Here, the transformation of the forms of information presentation is a consistent reflection of the content, and in essence — the filtering of information by reducing the variety of forms and aspects of the presentation of semantic content through fixing the nature of the expression, i.e., making part of the meaning into a meta-information component or simply discarding it. For example, the message assumes fixation (limitation) of the subject area; document — fixing options for the presentation method through the selection of semantically homogeneous fields and, accordingly, determining the nature and method of their filling; the search image fixes the ways of specifying the value of an individual element (data type). Accordingly, the adequacy of the means of reflecting information (and in the case of information retrieval systems, this is linguistic support) should be considered both from the point of view of the possibility of a non-distorting transformation of the information itself in the chain of generation-consumption of an information resource, and from the point of view the adequacy of the user’s perception of the capabilities of these tools. For the documentary systems considered in the work (documents as a reflection of the results of intellectual activity), the objects being processed are predominantly of an abstract nature. From the point of view of the previously mentioned definition of the system, the following types of information components can be distinguished: — situational information that fixes the result of OD in the form of a specific description of the problem situation (factography); — systematic, defining the pragmatic conditions (principles, laws, criteria) used in OA. It is the introduction of such a systematic component that makes it possible to reduce the dimension of the task of identifying objects and isolating the transformed part of the environment by abstracting from the specifics of the situational component, presenting it as a separate structural information component. Thus, the information model of any interaction-oriented system necessarily includes two types of components — a set of messages reflecting the current state of the environment, and a set of messages about the system-forming foundation chosen to build this model. Since an automated system is just a tool used by a person when searching, and not an intelligent machine for searching for information (ready-made solutions to core business problems), the effectiveness of its use depends on how well a person knows the nature of objects and the properties of the tool through which he works with these objects. A feature of the search process, considered as the interaction of two knowledge representation systems, is the multi-level and, often, heterogeneity of objects in the chain of information transformations. Operational objects directly involved in the interaction (comparison of needs and documents in the database), presented in fig. 1.2 are the search image of the document and the search image of the request, the correspondence of which is established by the AIPS search engine at the formal level. Establishing a true correspondence, however, involves correlating the content at the semantic level: the user practically reconstructs the possible content by listing the basic concepts and then correlates the resulting image with a real need. At the same time, the adequacy of the image to the actual content of the document is determined not only by the quality of the information convolution process; but also the level of knowledge by the subject of the means of reflection ^ - the conceptual scheme of the subject area and the capabilities of the information retrieval language. Note that in the context of the last factor, the assessment of the real effectiveness of the means of supporting the «human-computer» dialogue is associated with the need to take into account the subjective factor of the «vision» by the user of the features of his work at the computer, since in order to confirm that a state has been reached in which further work by the system does not bring new information, the user must be able to assess his condition, or at least understand the need for such an assessment. In the process of interacting with the search engine, the user removes various types of uncertainties: creating; a model of reality that forms (consciously or not) a lot of assumptions about how the system works. Typically, such a model is both incomplete and inadequate (unless the system developer acts as a user). In the process of solving a problematic (creative) situation, a contradiction between the accumulated experience and the novelty of the conditions available for solving the problem of the main activity is revealed and, possibly, removed. Thus, we can say that for the user only the information that corresponds to his understanding (reflection) of the missing knowledge matters. That is, the received information can be assessed as relevant only when the user already has sufficient knowledge in the subject area. At the same time, as noted earlier, a feature of working with information resources is that the user’s activity consists of two components — the fulfillment of the main task (search for documents containing information that contributes to the solution of a pragmatic problem in the field of his main activity), and the explicitly or implicitly realized mastering the means of interaction with the system. In addition, considering the process of communication as the interaction of two media of information presentation, one should take into account the fact that in each environment the presentation has its own specifics, and the variety of situations that arise during the interaction «man — LIPS» is quite large. In accordance with the nature of the tasks of the user’s main activity, according to the degree of correlation between the known / unknown in the search subject, three types of search tasks are distinguished. The tasks of the first type include searching for an object when it is known that this object exists, for example, searching for facts or works of a particular author. The user’s knowledge about the essence of the object being sought is complete, the purpose of the search is to find its documentary representation. The second type of tasks is the selection of information on a certain topic, for example, to review a scientific problem or to substantiate or search for a method for solving a practical problem. The user, already possessing knowledge, determines the place of the task (as a newly introduced concept in the system of already known concepts). This is a search for documents that together contain material that reveals a new concept introduced with the necessary completeness or makes it possible to construct a method for solving a problem. The third type of tasks is a problematic search, which, in fact, is the main component of the creative process of determining ways to solve the user’s professional task. Here, initially, there is no clarity of the structure of knowledge; the user may have separate facts that do not have proven connections with each other. The nature of information needs, considered as an addition, possibly hypothetical, of known knowledge, is largely determined by the form of its presentation, which in turn depends on the environment — the carrier of information. Initially, a user in a problem situation has some need for information, which is not yet fully realized, but reflects the problem situation — the so-called real information need. In the process of understanding it, the IP is transformed into a conscious IP, presented in the form of a question or a task, which the user then expresses in his usual language, forming a request in a natural language and, further, translating it into a search query, presented in terms of IIP. The query is characterized by the fact that questions like «how» and «why» should be transformed into a question like «whether», since it is this form of representing the need — hypothetical, that is the most adequate set-theoretic model of search. Note that the transformation of a question into a request is essentially qualitative. The transition from real to conscious IP is the more difficult, the less defined is the user’s task. For search tasks of a problematic type, this transition is the most difficult, since the user has no idea what kind of information is needed to solve his problem. Features of information representation at different levels of the human-machine environment cause different types of uncertainty, since each of the states of information need is the result of reflecting the issue, characterized by its degree of formalization and introducing its component of uncertainty — semantic, linguistic, meta-informational (the latter refers to semantics and syntax — the form of information representation). In this sense, the search process can be defined as a sequence of steps, the tasks of which are the removal of ambiguities: semantic, linguistic (and for the descriptor-type IPL, this is largely lexical ambiguity) and meta-informational. Semantic uncertainty is related to the formalization of the query. When forming a request, the user explicitly or implicitly synthesizes the information that may be in the searched text. First, the concepts are defined, then the connections between them, i.e. there is a reconstruction by the user of a hypothetical text, presumably coinciding in a known part of the problem with a possibly already existing text, and a designation of the connection between known knowledge and the identified unknown. Lexical ambiguity is associated with the wording of Pose. When formulating a query, the user must take into account that his idea of the informativeness of the term does not necessarily coincide with the views of the indexer. Meta-information uncertainty is related to the fact that the user must have an adequate understanding of the system itself and the method of presentation: the information in it. For example, how and on what fields to search. Let us consider human-machine search for information as a process of finding unknown (at least for the subject of the search) information (facts, ideas, etc.) necessary to obtain knowledge that is new for a given subject area. Such a process is characterized by the duality of human goals. On the one hand, this is the creation of new knowledge, including the stages of structuring and formalizing the problem, finding or developing methods for solving. On the other hand, it is a search for messages related to each of the stages, and an assessment of the usefulness of the found. An equally significant feature of the search situation is the mediation of the selection of information materially presented in the form of documents, and potentially useful documents (presumably containing the necessary information) are distinguished from the entire available set through the correlation of search images (information need and the content of the document, expressed means of information-search language). A similar mediation is observed at the level of information presentation environments: semantic processing — correlating the content of messages with real, i.e. conscious need — occurs in the human mind, and the selection of documents that formally correspond to the need — in a machine environment with rigid binary logic. Moreover, as noted earlier, such a scheme for establishing correspondence is built on the reduction of information need (as uncertainty and uncertainty) to the enumerative form of hypothetically known and, in essence, representing the need for hypothetical documents [I]. This technique ensures the homogeneity of the compared search images and is applicable, among other things, to the most common types of information retrieval, for example, bibliographic or search for publications about objects that already exist, one way or another already known to the subject. In addition, this approach allows us to consider the process of interaction as a sequential change in the states (stages) of interacting subsystems — a person and an automated information retrieval system, aimed at sequential localization of uncertainties of various types: 1) the uncertainty of the ratio of «known / unknown» in the subject of the search; 2) the uncertainty of the system of characteristic features for the structuring of the subject of the search; 3) semantic uncertainty in the definition of the subject of the search; 4) lexical uncertainty as a factor in the degree of correspondence; information retrieval language to the natural science language of the subject area; 5) uncertainty of criteria for comparison of search images (adequacy of formal proximity measures implemented in specific AIPS); 6) uncertainties in the interpretation of POZs (subjectivity and incompleteness of the reconstruction by the user of the meaning of the documents found). Not being practically measurable values, these parameters, nevertheless, allow us to designate the nature of the change in the state of the parties and structure the process, highlighting the components not so much according to the functional, but according to the structural principle. Moreover, the first four types of uncertainty are of an informational nature (transformation of information presentation forms), the fifth characterizes the AIPS search engine, and the sixth reflects the cognitive characteristics of a person — a receiver and generator of information. In the question-answer logic of discovering new knowledge, a question is a list of answer alternatives and rules (algorithms) for constructing a direct answer based on this list. In this context, information retrieval by means of non-intelligent AIPS is only the first component: finding messages that presumably contain a direct answer (or its components, which can later be be united by the subject of the search), and not necessarily alternative ones, and not necessarily satisfying the requirements of completeness and distinction. Summarizing the above and taking into account that a feature (and in the limit — a paradox) of the search situation is that the user, for new knowledge, turns to an array of already known knowledge (although, possibly, contradictory), we will represent the search query as a hypothetical document (describes a real or perceived or created object). That is, in this context, the search task can be formulated as follows: to find already existing documents that are a meaningful analogue of the requested hypothetical’ . For the case of an attributive model for representing meaning (including a question), which is characteristic of information retrieval systems, an object is specified by a set of characteristic features and relationships. Internal links define the structure of the object itself, while external links determine the structure of relationships with other objects. Then the request, considered at the conceptual level, is a structural-logical definition of the unknown (real information need) through known characteristic features and connections, if the alleged analogue exists, or, otherwise, through the addition: characteristic features and connections of objects, of which the object is a part or is associated with. Thus, from the point of view of the structural completeness of the representation of the search object, we can introduce the following typology of search types, presented in Table. 1.1. Table 1.1 Search Type Logical model of the search object Logical model of the search mechanism subject (attributive) search The scope of the concept specified by the name Search by logical expression over the names of concepts specified by terms or their combination (values of a certain characteristic feature) Terms of documents related to semantically defined fields Thematic search Definition of a new concept or conceptual relationships indirectly determined by the scope of this concept terms of additional search structures — subject headings, thesauri, etc., referred to semantically defined fields. Problem search A documentary definition of a new concept or connections by reconstructing the image in its part. Search for «similar» documents, search using «feedback» technology. Documents included in an iteratively generated information space by the user From the point of view of semiotics as a sign system, which is characterized by the non-isomorphism of the display of the system of signifiers (signs) to the system of signifieds (objects — denotations), the typology under consideration is associated with the following semiotic situations. Subject search corresponds to the situation of formation (selection) of a sign (sign construction) that eliminates the uncertainty of the sign system in the context of the completeness and accuracy of the representation of the object, i.e. such a sign that will effectively select (distinguish) an object from many others with a fixed (single) concept, which is illustrated in Figure 1.3 a). For the case of a thematic search, the situation differs in that we have an ordered limited set of concepts that allow us to represent an object in various aspects, which is shown in Fig. 1.3). For the case of problematic search, we already have an unordered and not rigidly defined set of concepts. Using , we introduce the following definitions, which are important from the point of view of modeling and operation of information retrieval systems. Search methods are a set of models and algorithms for the implementation of individual technological stages, such as building a search image of a query, selecting documents (comparing search images of queries and documents), expanding and reformulating a query, localizing and evaluating issuance. We will call search mechanisms a set of models and algorithms implemented in the system for the process of generating documents issuing in response to a search query. Search tools are, on the one hand, an interdependent complex of IEL and data definition/management languages that provide structural and semantic transformations of processing objects (documents, dictionaries, sets of search results), and on the other hand, these are user interface objects as techno ¬logical solutions that provide control over the sequence of selection of operational objects of a particular AIPS. From the point of view of user interaction with the system, search tools are embodied in search technologies — unified (optimized within the framework of a specific AIPS) sequences of using individual system tools to obtain the final and, possibly, intermediate results. Search strategy — a general plan (concept, preference, predisposition, attitude) of the user’s behavior to express and satisfy the information need, due both to the nature of the goal and the type of search, and system «strategic» decisions — the database architecture, as well as methods and means of searching for a specific AIPS. The choice of strategy in the general case is an optimization task, however, in practice it is largely determined by the art of achieving a compromise between practical needs and the possibilities of available funds. From the point of view of the method of specifying the conditions for the correspondence of information needs to information resources, we can talk about two «pure» strategies — «verbal», which is an analogue of the functional tasks of «cluster» — reflecting the features of the enumerative method. Navigation as an implementation of the on-demand search process in the selected database is a purposeful, strategy-defined sequence of using the methods, tools and technologies of a particular AIPS to obtain and evaluate the result. Navigation tools allow the user to control the search process. Such tools are provided to the user in the form of an interface that allows organizing a more or less efficient process of interacting with the database. At the same time, the «friendliness» of the interface is characterized not only by ergonomics and clarity, but also by the variability in the choice of operational objects. Namely, the interface means should «explain» the essence of the system, i.e. provide a basis and support for defining a behavior strategy, as well as correlating each action with a generalized process model, explicitly specify the content of each object and justify the transition from assumptions to actions to implement the search process. The information retrieval process is a sequence of steps leading through the system to a certain result and allowing to evaluate its completeness, i.e. evaluate the new state of the aggregate system, both his new knowledge and the system (can the user be sure that the result obtained is exhaustive and contains nothing more on the problem being sought). Since the user usually does not have exhaustive knowledge about the information content of the resource in which he conducts a search, he can evaluate the adequacy of the query expression, as well as the completeness of the result obtained, based only on external estimates or on intermediate results and generalizations, comparing them, for example , with the previous ones. On the other hand, since the request (its search image) is a formally described model of the user’s information need, then, according to the meaning of the expression, the POZ and the OD should be brought into line. Those. either the user must accept the conceptual platform (and sign system) of the indexer, or, if the IS is intelligent, the system, based on the query expression (sometimes presented in the form of a natural question), must reconstruct the problem being solved by the user and build a logical search model. In the context of Fig. 1.2 the task of the search process is to build a consistent set of models of the search object (i.e., a conscious information need fixed in the mind of a person). For the information chain (Fig. 1.2), the formation of POS are two models that have a linguistic nature and belong to the two upper levels: already published documents; 2) search model, attributively representing IP, and focused on point (set-theoretic) correlation with similarly presented search images of documents. Consistency here has a double meaning: the obvious (vertical) correspondence of the expression and the search image (software is an expression represented by means of ISL), and «horizontal» consistency — the degree of correspondence of the representation: the user with the real possibilities of the language for expressing the IP. In order for the user to be able to actually control the search process (based on objective data that allows evaluating the effectiveness of the actions performed), it is necessary to decompose, in general, an extremely simple, request-response scheme of the search process. Such a functional decomposition should ultimately provide opportunities for the consistent removal of uncertainties of all types, which in the organizational plan is expressed in the allocation of sub-processes-procedures and the corresponding operational objects. From the point of view of the intended purpose of IS, that is, for the search process as a whole, we have only two types of main operational objects — a query and a document, which represent some semantically integral fragment of the subject area using the language. Other operational objects — technological within the framework of the decomposed process — are independent semantically significant objects of meta-information purpose, or objects derived from the main ones. The purpose and nature of technological objects is to provide an opportunity to localize and remove or fix the uncertainty of this type. Both the query and the document are models representing, by means of the language, separate parts and aspects of some integral fragment of the subject area. The document is a specific (although not the only) form of expression of a specific problem situation (the resolution of which was the subject of OD, which led to the appearance of this document). POD represents this specificity by a composition of characteristic features, in the general case, not unique, selected from a set of features that are also characteristic of other objects, information about which is stored in the database. The purpose of creating a POD is to present the initially unique meaning of the document with a compact composition of features (keywords), without increasing the combinativity of the possible meanings generated by them. The purpose of constructing a POS is, while maintaining the uniqueness of the problem situation, to increase the combinativity of meanings generated by the composition of search query features in order to cover the aspects of the representation of the search object as much as possible. For a person, the ideal communicative form of presenting a real IP is a verbal one, where the characteristic properties of the unknown (sought) will be associated with the specific context of the problem situation, that is, the request will actually be presented as a document containing statements that hypothetically describe supposedly existing objects. To ensure an effective search process as a directed localization of the information space, it is necessary to have interface objects; and tools that support personalized subject identification (including hierarchical type) of individual information objects and collections. Each of the ones shown in Fig. 1.4 function-oriented blocks, in turn, is a "process that provides, through the use of technological information objects and procedural means, obtaining. Consider, in accordance with the scheme of search stages, the main means of preparing and developing a query. Traditional search interfaces for the initial entry into the information space of the base — interfaces for generating a request, are divided into «verbal» and «cluster». The former are procedurally oriented tools that ensure the formation of a holistic logical expression of one or another complexity on the ILP, which involves preliminary structuring at the semantic level and lexical adaptation of the query. The procedural interfaces presented in the system — query constructors «by pattern», «by steps» and «query editor», are typical solutions for the verbal form of query presentation with different levels of friendliness. This group is almost complete in terms of the degrees of freedom of choice of operational objects for the case of request specification in the form of a generalized logical expression. Interfaces for generating a «cluster» type query use operational objects with different levels of information content reflection: bases: at the «atomic» level, these are mainly inverted forms (dictionaries, indexes) or database documents selected in an arbitrary order; at the thematic level, these are structuring with hierarchical or linear ordering through subject headings or thesauri; at the level of private queries, these are, for example, typical ones: queries (and, accordingly, search results) or collections of query expressions. The degree of completeness of the result is determined by the level of semantic identity.one features of the generated search image of the user’s information needs. As a result of the considered factors of information uncertainty, it is not possible to immediately form an expression of POS that has the proper level of adequacy. As shown earlier, information retrieval is an iterative process based on the technology of sequential expansion/restriction of the subject area, which is objectively represented both at the level of queries («entry points» in SbA — individual terms and expressions of the ISL) and at the level of semantically completed documents — search results for a particular POS. The extension in this sense aims to cover possible variants of the lexical representation of the search object and thereby compensate for the variance (ambiguity) of the meaning expression. However, the mere inclusion of expanding terms (usually without an explicit indication of their semantic relationships and role) leads to a sharp increase in noise. It is in consequence of the requirement that a real possibility for the user to process the issuance should be provided, the system should have means to limit and / or order objects representing the subject area of the request — the search image of the request and the set of documents — search results for it. For example, technologies for expanding/restricting the search image of a query, presented in Table. 1.2 are such that for each next type of search there are possibilities that are additional in relation to the previous ones. Considering that the ideal search result must satisfy the requirements of uniqueness, completeness and consistency, we find that different types of search determine different requirements for the functionality of the system in terms of evaluating the result. However, only for the case of a subject search, the proof of completeness is trivial: a non-empty search result confirms the existence (or absence) of an object with the desired properties. The result of a thematic search in this sense is multiple and, accordingly, requires subsequent systematization — one more procedural step for ordering the resulting set of objects according to the values of an undefined base. In turn, the problematic search already involves a two-level systematization. Accordingly, such additional, and separate in time, processing requires the presence in the system of means for identifying the objects obtained (both individual elements and their compositions, possibly associated with methods for their production), as well as means for their selective use. Interface tools for processing the result and developing the search use two types of operational objects — individual documents or collections of documents. A feature of the proposed scheme is the functional similarity of the interface blocks and the fact that, in addition to the functions of processing the material of documents, the system provides means for developing the search process either by modifying the expression or by reformulating the request for relevance feedback. 1. Based on the analysis of the state and development trends, the creation of personal information systems that provide information support for the user’s OD in the «self-service» mode has been identified as a promising direction. Functionally, such systems include, in addition to search capabilities, tools for the formation and systematization of information arrays, evaluation and analysis of search results, as well as the formation and development of linguistic support tools. 2. On the basis of the information model of knowledge reproduction, the correlation scheme of the main objects and means involved in the chains of transformation and information retrieval is determined. It is shown that the technological scheme that ensures the fulfillment of the requirement of adequate information includes two types of feedback: external, reflecting the user’s assessment, and internal, taking into account the statistical features of the use of terms in specific databases. 3. For various types of search, characterized by various types of information uncertainties, logical models and linguistic search tools are determined. The search process is presented as a sequence of steps leading through the system to the removal of information uncertainties and obtaining a result that is meaningful to the user. 4.A generalized scheme of information retrieval has been developed, in which technological objects provide localization and removal of uncertainties of the corresponding type. 5. Considered and systematized technological objects that implement at the user interface level the means of entering the information space of the database, including the means of preparing and modifying the query expression; means of evaluating and processing issuance both at the level of a single document and at the level of problem-oriented collections. The means of request development are determined, including the feedback technology.
1.2. Human-machine information retrieval in documentary databases
1.3. Typology of information uncertainty and types of information retrieval
1.4. Generalized schema and information retrieval tools
1.4.1. Generalized Information Retrieval Scheme
1.4.2. Tools and interface objects in search technologies
1.4.3. Evaluation and processing of search results
Conclusion