
редакции

ТОП 8 источников ключевых фраз для контекстной рекламы
Какой подход и источник для сбора ключевых фраз выбрать
Всё зависит от проекта, от ниши, от задачи и ваших предпочтений. Можно парсить, можно не парсить, можно вообще не собирать семантику. В первую очередь смотрите на уровень проекта. Если это небольшой проект в узкой нише — вполне достаточно ручного сбора основных ключей через Wordstat. Если это какой-то жёсткий b2b с 50 направлением услуг — то нужно вытаскивать максимум из возможного.
Также подход зависит от бюджета проекта. Ведь будет глупо брать за проект 15 тыс. рублей и потратить две недели только на парсинг и чистку семантики.

Мой посыл такой — каждый подход подходит под свой проект и под свою задачу. Также не забывайте упрощать себе жизнь, делая скоринг получившейся семантики.
Маски ключевых слов
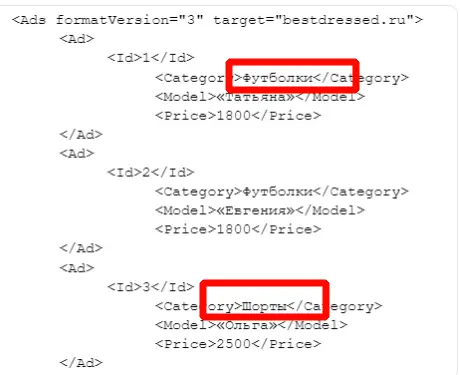
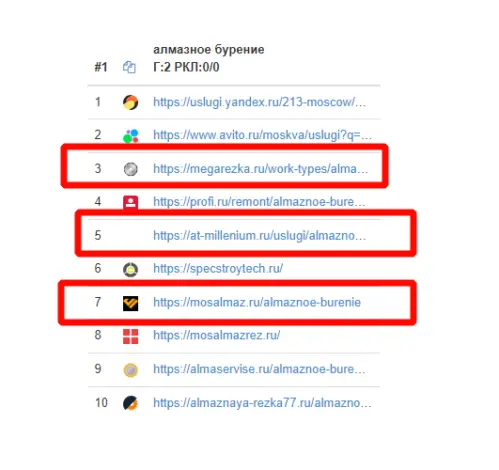
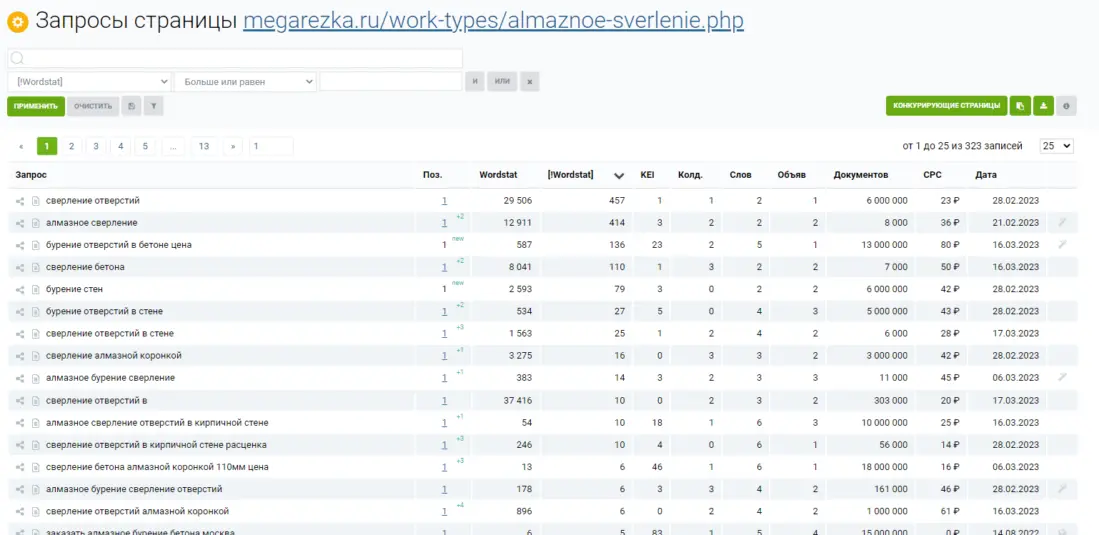
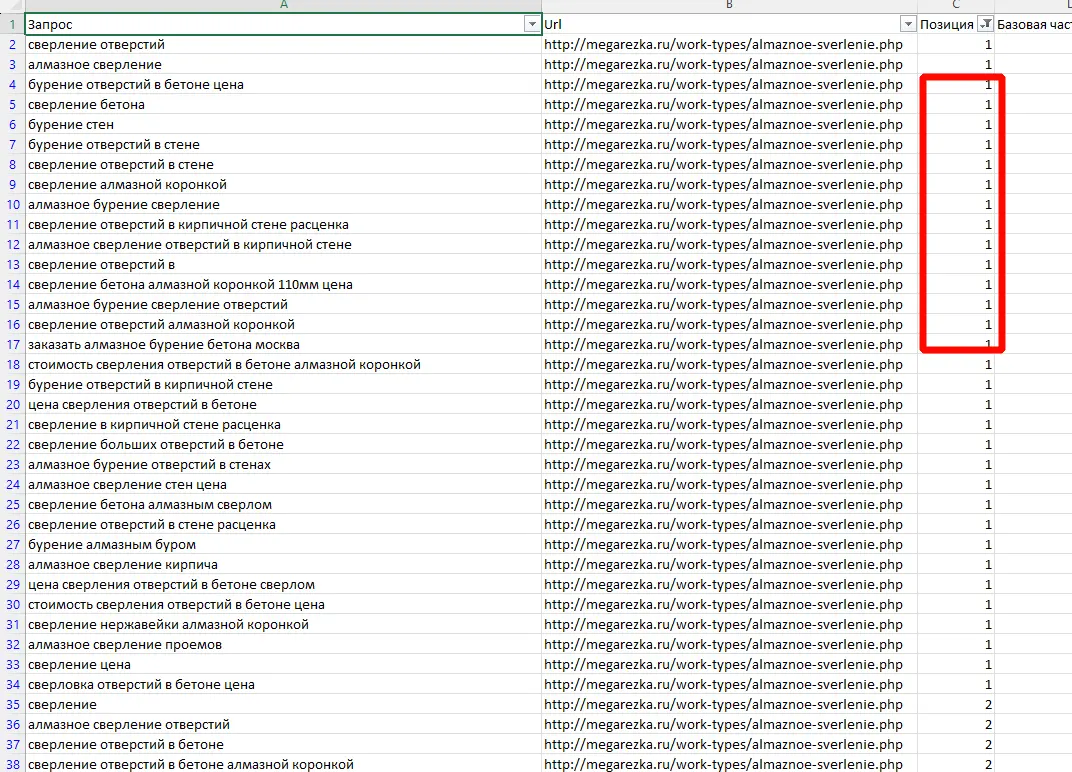
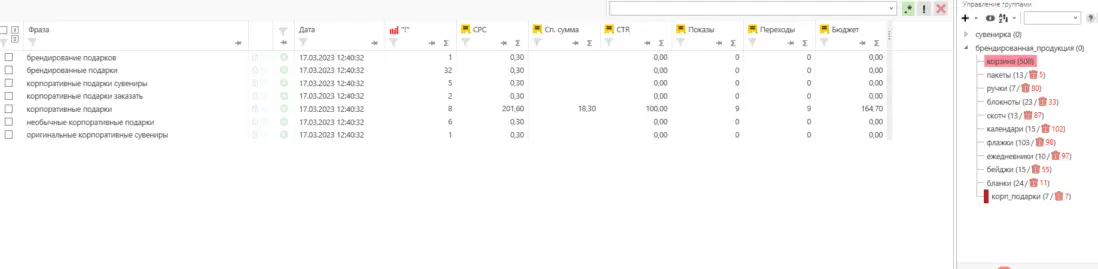
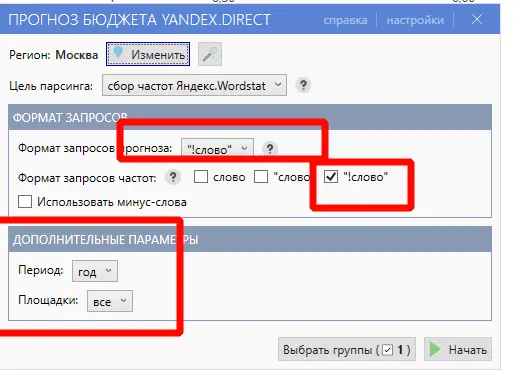
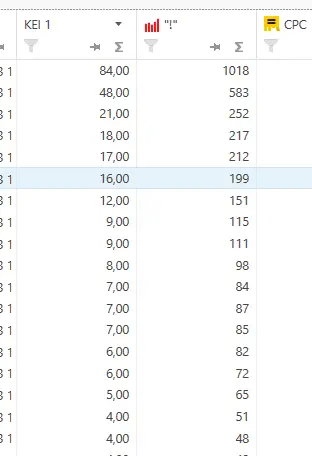
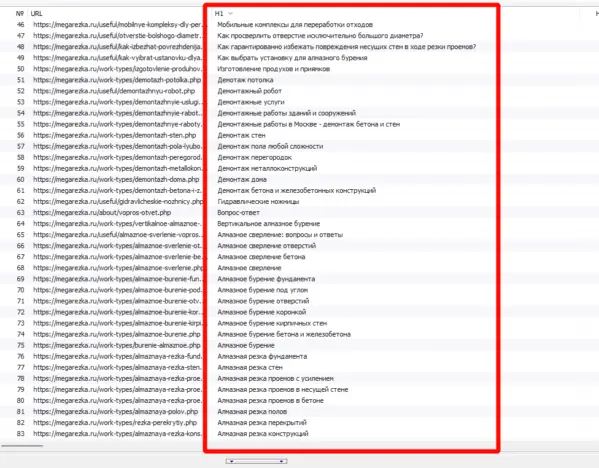
Для работы с проектом вам нужно в любом случае собрать какие-то маски ключевых слов. Маски — это слова или фразы обобщённо характеризующие вашу нишу/продукт. По этим маскам в дальнейшем можно парсить или генерировать семантику. Нужны они, чтобы в целом понимать, в какую сторону копать. Далее расскажу о самых ТОПовых источниках и способов сбора ключевых фраз. Начнём с самого простого и будем двигаться к более сложному. Бонусом я покажу неочевидные варианты, которые используют SEO-специалисты. Запускаем поисковую кампанию/мастер кампаний на небольшом бюджете на 1-2 недели. Копим статистику. Выгружаем ключевые фразы из статистики кампании и работаем с ними. Это самый простой вариант. Можно быстро и с минимум трудозатрат получить реально работающую семантику, по которой уже были показы, переходы и конверсии. Способ подходит для любых проектов любого уровня. Плюсы: не тратите время на парсинг, получаете актуальную семантику с конверсиями. Минусы: в любом случае придётся разгребать тонны мусора, а потом чистить и группировать; можно что-то упустить; можно открутить бюджет и получить мусорные фразы без конверсий. Искусственная семантика делается с помощью генерации пересечений по маскам и различным добавочным словам характеризующим ваш продукт. Нужно взять маски, добавить тематичных вашей нише/продукту слов и сгенерить фразы с помощью специальных сервисов. В качестве добавок могут быть коммерческие приставки, название моделей авто/техники, топонимы, станции метро и пр. подходящие слова. Далее эту искусственную семантику желательно прогнать через Key Collector и снять частотность, чтобы убрать фразы, которые никто не ищет. Подписывайтесь на мой канал в телеге про контекстную рекламу, чтобы не пропустить интересные посты и всякие полезные материалы (или не очень интересные и не очень полезные). Примеры сервисов для генерации пересечений: Способ подходит для еком проектов. Всё то же самое, что с генерацией пересечений, только вместо масок можно использовать информацию из фида интернет-магазина. Берём названия, артикулы, модели, что угодно из вашего фида, добавляем коммерческие приставки и получаем ключевые фразы. Собираем ключевые фразы через Wordstat с помощью различных плагинов в ручном режиме. Я использую плагин Wordstater. Тут всё просто — берёте подготовленные маски, ищите по ним ключи. Что подходит — добавляем, что не подходит — в минус-слова. Отличный вариант для мелких ниш и для небольших сайтов в сфере услуг. Плюсы: сразу собираете только релевантные ключи, сразу собираете минус-слова, тратится минимум времени. Минусы: не подходит для больших проектов с десятками направлений/продуктов, не подходит для екома. Также в Wordstat’e сломался выбор региона, хоть это, и решаемо — но для регионов создаёт дополнительный геморрой в работе. Лайфхак для ручного сбора в Wordstat: можно сделать шаблон в Google Docs, который будет автоматически сцеплять маски для поиска ключей. Мой любимый источник — ключи конкурентов из SEO-выдачи. Берём уже готовое у конкурентов, которые плотно сидят в топах выдачи с помощью специальных сервисов. Сервисы для анализа конкурентов: Приведу пример, как получить за 10 минут проработанную семантику под одно направление услуг. Возьмём услугу по алмазному бурению. Заходим в сервис Arsenkin Tools и выгружаем топ10 по Москве по ключу «алмазное бурение». Собираем похожих на нас конкурентов. Берём только внутренние страницы, а главные страницы и агрегаторы, типа Авито, Яндекс Услуг и пр. игнорируем. Идём в Keys.so, выгружаем ключи по URL. Берем ключи по которым страница ранжировалась в топ 5, собираем их в кучу. Осталось почистить семантику от мусора и снять частотность, чтобы убрать нулевки. Способ хорош тем, что мы охватываем всю семантику, которая релевантна нашему продукту. Плюсы: за минимум времени получаем проработанную семантику. Минусы: много ручных действий; сервисы имеют не совсем актуальные данные по ключам. Лайфхак: с помощью выгрузок легко и быстро делать предпродажные медиапланы. Подписывайтесь на мой канал в телеге про контекстную рекламу, чтобы не пропустить интересные посты и всякие полезные материалы (или не очень интересные и не очень полезные). Классический парсинг семантики через специальный софт: Key Collector, Словоёб, A-parser, etc. Что можно парсить: Тут всё просто. Берём маски, загружаем в софт, парсим, чистим, группируем, делаем скоринг ключей. Пару советов от меня: Есть лайфхак по сбору частотности в Key Collector. Парсим частотку в точном соответствии. Период сбора — год. Почему год? Если парсить за год, то мы избежим проблем с сезонностью и проблем с колебаниями спроса из-за различных событий в стране. Далее делим годовую частотку на 12 с помощью KEI-формул и получаем «среднюю температуру» по спросу. Плюсы: автоматизировано; получаем актуальные и полные данные по ключам; можно работать с большими и сложными проектами; можно работать с большим количеством ключей; можно подготовить хороший список минус-слов. Минусы: трудозатратно, нужен софт и навыки работы с этим софтом; для софта нужна антикапча, прокси. Расскажу ещё о парочке не очевидных способов для тех, кому нужна максимально полная семантика. Первый способ: находим конкурента в SEO-выдаче, загоняем его сайт в специальный софт, парсим с сайта title, h1, description, keywords. Далее смотрим, где можно вытащить ключи. Ключи загоняем в key collector, снимаем частотность, чистим, группируем. Сайты для парсинга должны сидеть плотно в топ3 и должны быть отлично проработаны по SEO. Способ актуален для больших ниш, для екома, для каких-то каталогов/агрегаторов, т.е для сайтов, у которых много страниц. Парсить сайты можно софтом: Второй способ: выгребаем всю семантику из кабинета вебмастера Яндекса, Search Console Гугла и Яндекс Метрики. Способ подходит для проектов, которые плотно сидят в SEO-выдаче и получают поисковый трафик. Тут всё просто — выгружаем ключи по которым были переходы из поиска, выгружаем все ключи по которым есть видимость в Вебмастере и Search Console. Далее чистим, группируем, делаем скоринг. Под каждую задачу выбирайте свой источник и способ сбора ключевых фраз. Для медиаплана можно использовать выгрузки ключей конкурентов. Для быстрого запуска в узкой нише можно руками собрать в Wordstat. Для больших проектов с большим бюджетом и серьёзным вовлечением можно использовать все источники в связке между собой. Для екома можно вообще ничего не собирать, а работать чисто с автоматикой и фидами. В зависимости от задачи для себя использую такие источники: Если вам нужно запустить рекламу в Яндекс Директ/Google Ads или сделать аудит — жду вас в своём TG. Также не забывайте подписываться на мой канал в телеге про контекстную рекламу, чтобы не пропустить интересные посты и всякие полезные материалы (или не очень интересные и не очень полезные).
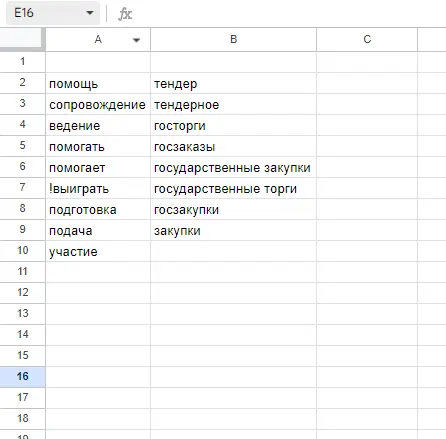
ТОП источников ключевых фраз для контекстной рекламы
Автотаргет
Искусственная семантика
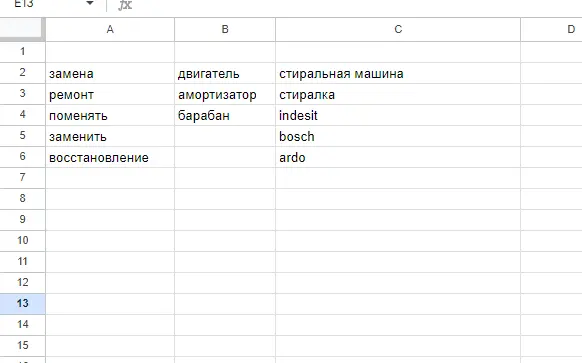
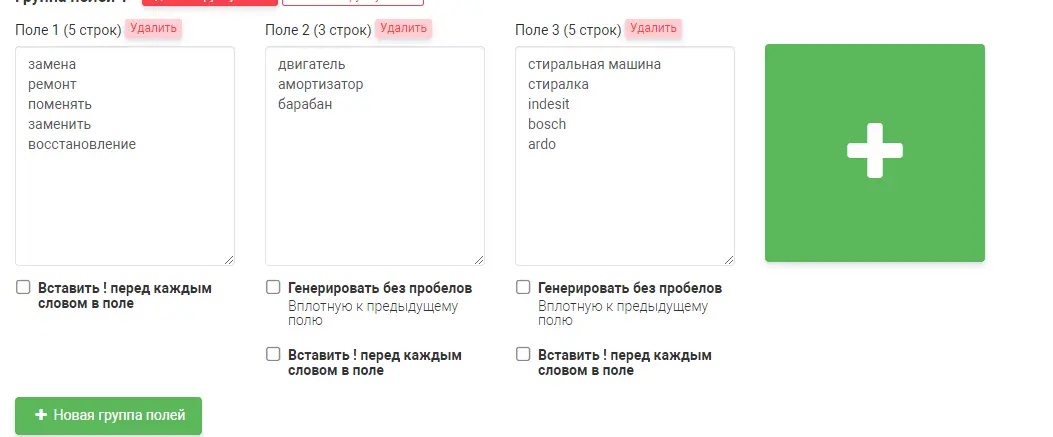
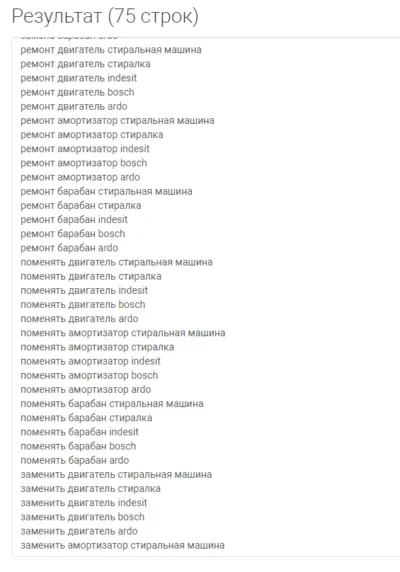
Искусственная семантика из фида
Ручной сбор в Wordstat
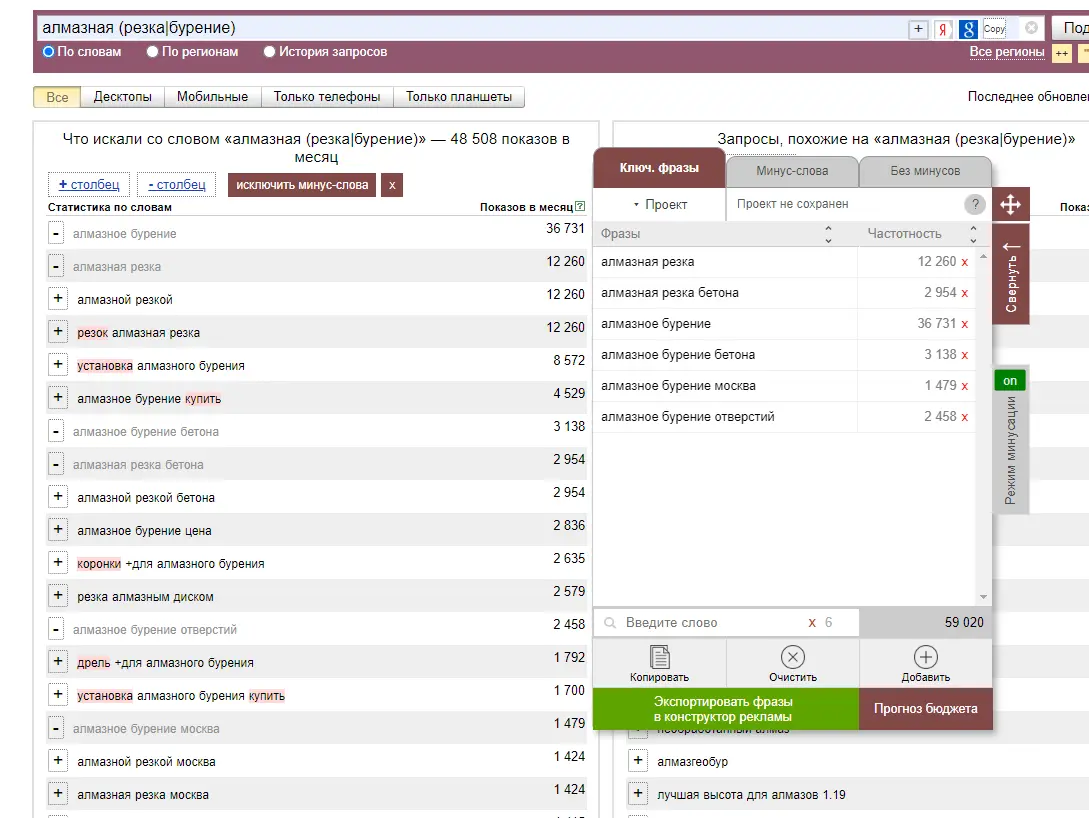
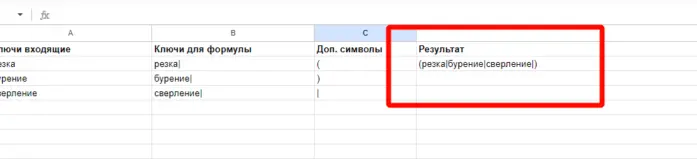
Берём готовое у конкурентов
Парсинг
Бонусные источники
Подведём итоги