
редакции

Стартовал FractalGPT - самообучающийся ИИ на базе больших языковых моделей (LLM) и логического вывода
FractalGPT призван решить проблему «галлюцинаций» нейросети. Также он будет обладать мотивацией
Наша цель
1. Создать ИИ модель лучше, чем ChatGPT. FractalGPT сможет кардинально лучше решать задачи математики, физики, понимания логики суждений и будет делать это надежнее, с прогнозируемой точностью.
2. А для ИИ сообщества создать открытую и прозрачную экосистему скиллов и ИИ моделей для настоящего дисрапшена в применении и внедрении ИИ решений для бизнеса и государства.
Вот краткий перечень принципов и компонентов, на которых FractalGPT будет построен:
1. Целеполагание (строит модель целей свою и собеседника)
2. Умение логически «мыслить»
3. Мотивация (имеет внутреннюю потребность к саморазвитию)
4. Планирование своего поведения
5. Умение выражать и испытывать эмоции
(список не полный, некоторые принципы не раскрываем)
Статус
В составе небольшой команды ML разработчиков мы уже собрали микро-MVP. Разработана принципиальная архитектура системы, построена модель функционирования. Составлен план разработки, 19го марта выпущено первое демо.
Демо
Уже опубликована первая демонстрация возможностей FractalGPT.
В работе показаны модули Fractal и GPT, немного фактологии и решение простой математической задачи.
Все, что вы увидите ниже в демо — первая версия, и это даже менее 10% MVP.
FractalGPT состоит из двух основных модулей:
это модуль Fractal и модуль GPT (Когнитрон Кибертроныч Ai)
Fractal — это движок логического вывода, вычисления и прогнозирования «эмоций», планирования действий, он также используется для дообучения GPT. Данный модуль основан на принципах самоподобия, т.е. любой вычислитель может быть частью большего вычислителя и такое масштабирование практически ничем не ограничено.
GPT — это LLM, предназначенная для генерации текста, ведения диалога. Мы используем ряд ноу-хау, чтобы повысить точность ее ответов и увеличить число «понимаемых» ею тем.
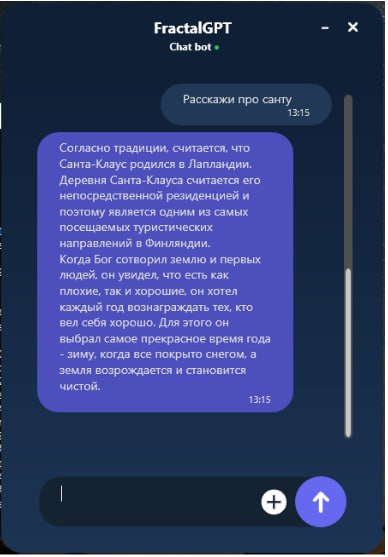
1. На первом скрине показано свойство Фактологии.
Что сделали: мы задали вопрос на знания, на который хотим получить фактологический ответ. Система приняла вопрос, обработала модулем GPT (LLM Когнитрон Кибертроныч) и выдала ответ. Система «понимает», что нужно ответить кратко и с фактом, а не длинно, не объясняя, не фантазируя, не рассуждая — и это сработало.
Текущие ограничения: в демо показаны 3 поддерживаемые домена (темы) — сказочность, машинное обучение, электродвигатели.
Предусмотрена легкая и автоматическая Расширяемость на новые домены знаний. ChatGPT в этих кейсах тоже показывает себя хорошо.
У FractalGPT соотношение качество на параметр лучше, чем у ChatGPT, тк мы используем GPT-like модель с менее чем 10 млрд. параметров.
В наших экспериментах уже достигается получение ответов сравнимых по качеству и они фактологические на некоторой общности задаваемых вопросов.
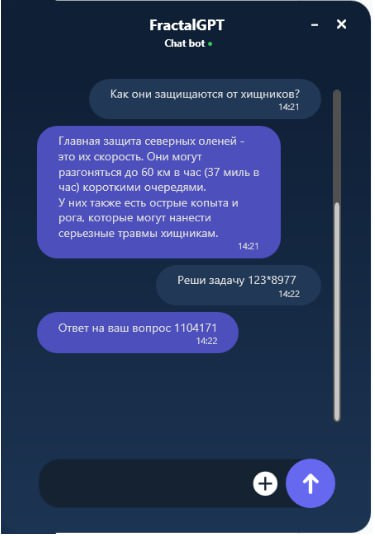
2. На 2-4 скрине показано, что свойство Учета контекста уже работает. Распознается анафора и неявная референция на объект.
3. На пятом скрине показана работа модуля Calc и способность решать математические задачи (Свойство маршрутизации тасков).
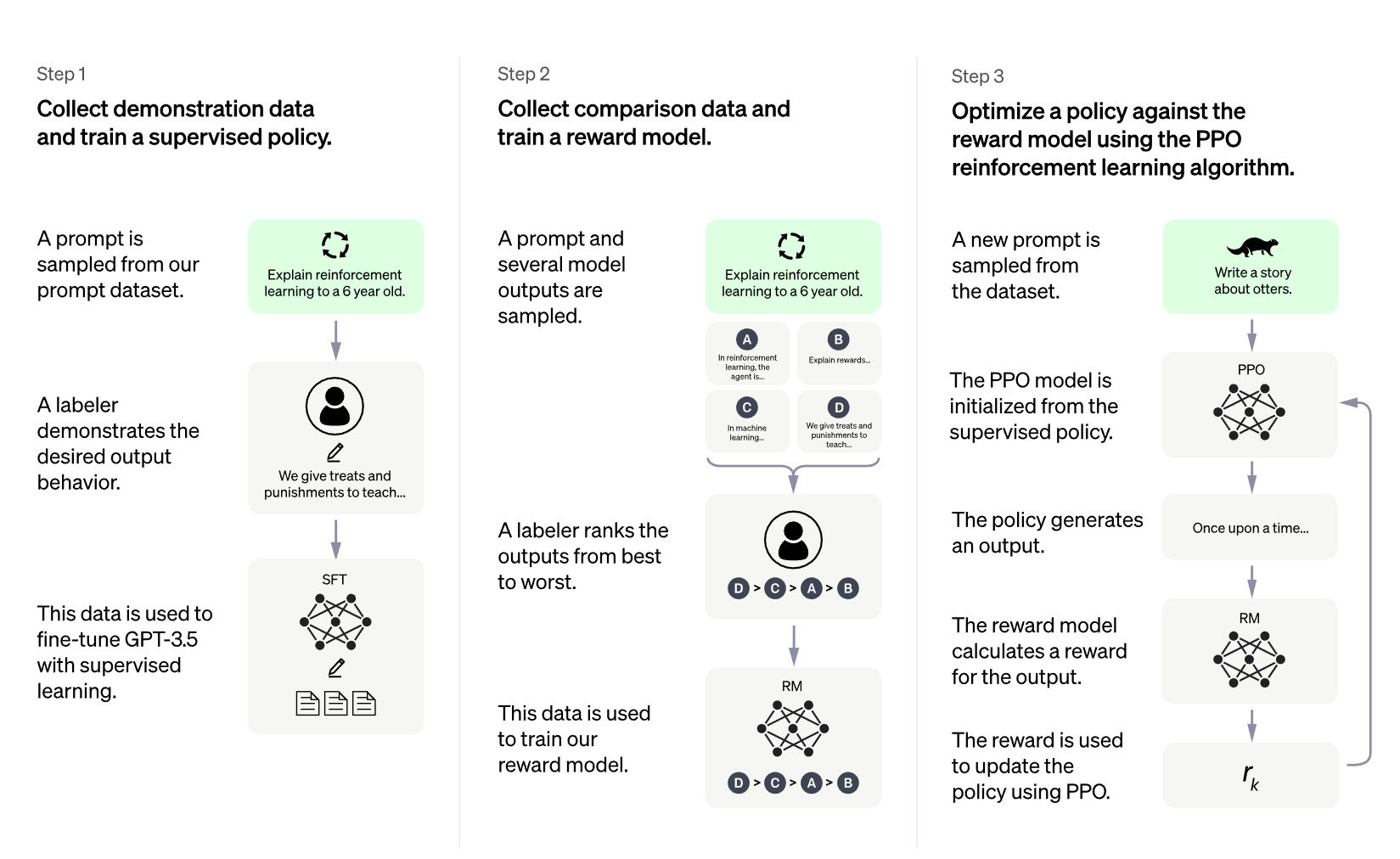
Что сделали: сформулировали задачу и написали численный пример. Система смогла решить задачу по правилам математики: посчитать правильно арифметический пример. Система «поняла», что данный запрос нужно направить в систему символьных вычислений. Важно: LLM не генерировала ответа на арифметический пример, перенаправив его в компетентный модуль. Для тех, кому интересна техническая сторона проекта — мы описали ее ниже, в разделах Архитектура, Проблема, Решение, Научная новизна, Области применения, Часто задаваемые вопросы, Авторы проекта FractalGPT это достаточно большой проект распределенного искусственного интеллекта, в нем мы предполагаем наличие множества модулей. На модуле логического вывода можно остановиться подробнее, именно этот модуль позволяет более обосновано принимать решения, с прогнозируемой достоверностью, в отличии от больших языковых моделей. Примером некорректной генерации языковой моделью, может служить то, что Bing при общении с пользователем угрожает и хамит ему. (https://vc.ru/s/sokr/612368-microsoft-urezal-funkcii-novogo-bing-on-lgal-sledil-za-sotrudnikami-i-ugrozhal-ubiystvom) Модуль Когнитрон Кибертроныч Ai — это модуль логического вывода, он представляет собой экосистему создания, обучения и хостинга языковых моделей и самообучающихся моделей(скиллов) со способностями логического вывода (logic inference, reasoning) для сборки конечных ИИ продуктов на базе нейро-символьного подхода, в том числе мультимодальных. ChatGPT (https://openai.com/blog/chatgpt/) порвал рынок и стал самым быстрорастущим приложением в истории, набрав 100 млн активных ежемесячных пользователей всего за 2 месяца, став самым быстрорастущим приложением в истории (https://rb.ru/news/chatgpt-record-users/ ). Однако даже огромная трансформенная модель на базе InstructGPT, обученная с помощью подхода RLHF по прежнему страдает от фундаментальной, неустранимой проблемы неконтролируемой бредогенерации: она придумывает и искажает факты, даты, события, обманывает при ответах, приукрашивает(bias, https://en.wikipedia.org/wiki/Algorithmic_bias ). Особенно ярко проблема контроля генерации трансформеров видна при решении символьных задач в математике, физике, биологии и других точных науках, поиске фактов, ответах на вопросы — и поэтому в этих отраслях использовать даже большие языковые модели(LLM) опасно. Даже те кейсы, в которых ChatGPT показывает себя хорошо, такие как генерация сниппетов кода и исправление ошибок по описанию — все равно не расширяются на структурное написание нового кода, собственно потому, что архитектура GPT принципиально не подходит для решения такого рода задач. Мы предлагаем принципиально новый подход и архитектуру к обучению гибридных нейросимвольных трансформерных моделей, способных инкорпорировать знания в виде графов знаний, а также обновлять их в процессе не только обучения на данных, но и в процессе взаимодействия с другими моделями, которые в данном контексте выполняют роль подключаемых модулей (скиллов). Такие модели станут способными к моделированию рассуждений, так, как об этом мечтали еще 30 лет назад — описано в книге Поспелов Д. А. П 62 Моделирование рассуждений. Опыт анализа мыслительных актов.— М.: Радио и связь, 1989.—184 с.:. Аналогичные идеи построения семантического дерева предложения, а затем анализа силлогизмов, предикатов и пр. рассматриваются и в книге Е. В. Золотов, И. П. Кузнецов. Расширяющиеся системы активного диалога. 1982 г. Когда я читал эти книги, мне было искренне жаль их авторов — ведь идеи они высказывали совершенно правильные. На тот момент создавать системы, которые могли бы рассуждать, строить цепочки фактов и событий, делать выводы (reasoning), обладать логикой — было невозможно из-за фундаментальных проблем: отсутствия языковых моделей которые могли бы адекватно выполнять трансляцию данных между нейросетевым и символьным слоем. Требовалось написать тысячи и даже сотни тысяч правил, чтобы победить неоднозначность языка и обеспечить надежность и проверяемость выводов модели, а это было невозможно. В предлагаемом нами решении проблема поиска, конструирования фактов, событий, рассуждений решается с помощью синергии в применении 3х подходов к обучению моделей использовать внешние базы знаний, обновлять веса модели и видоизменять граф логического вывода и постоянно обучаться учиться лучше (learn-to-learn): 1. Toolformer + MRKL — подход, позволяющий модели обучаться правильно использовать запросы во внешние базы знаний (API calls), в том числе запросы в другие ранее обученные модели и таким образом строить логические цепочки, аналогичные chain-of-thought (https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html) но более длинные, сложные, с ветвлениями, циклами, логикой предикатов и квантификаторов, оперирующие неполными и неточными данными(аналогично NARS https://www.applied-nars.com/ ). Подход показал свою полезность в задачах вызова нужных данных при поиске, подсчетах, анализе дат, вопросно-ответной системе в статьях: Toolformer: Language Models Can Teach Themselves to Use Tools (https://arxiv.org/abs/2302.04761 ) и MRKL Systems A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning (https://arxiv.org/pdf/2205.00445.pdf ) 2. reStructured Pre-training (https://arxiv.org/pdf/2206.11147.pdf ) — подход, при котором трансформер учится не на self-supervised датасете, а на более структурированном. Подход показал свою эффективность: модель трансформера GPT3, обученная с помощью датасетов с дополнительными данными (NER, факты, заголовки, суммаризация и т.п.) превзошла оригинальную GPT3 при этом имея в 16 раз меньше параметров. 3. Reinforcement learning from human feedback (RLHF) — подход, позволивший добиться генерализации промтов (prompt — «затравка») и описанный в оригинальной статье от OpenAi и их блоге: (https://openai.com/blog/chatgpt/ ), Aligning Language Models to Follow Instructions (https://arxiv.org/abs/2203.02155 ). Именно использование дополнительной политики модели (Proximal Policy Optimization) дало возможность пользователям по сути «обучать» модель без фактического файн-тюнинга, то есть понимать огромный спектр задач просто по описанию естественным языком, даже тех, на которые модель не учили. Предлагается для обучения моделей применять новый гибридный подход RLHF-MRKL-RST c обновлением весов Toolformer. Принципиальная новизна проекта в применяемом подходе к пред. обучению гибридных моделей: используя RLHF можно обучать модель понимать новые задачи практически неограниченной вложенной сложности благодаря моделям, способным добывать новые знания с помощью Toolformer + MRKL, инкорпорировать их в языковые модели, а затем переобучаться снова с помощью RST (reStructured Pre-training). Разрабатываемый в настоящее время проект Интерпретируемого ИИ с библиотекой ExplainitAll позволит обеспечить внедрение метрик надежности работы моделей в реальное применение. Модели и экосистема будет полезна бизнесу и госструктурам из любой сферы и позволит уменьшить затраты на составление наборов данных и внедрении ИИ.Конкуренты: OpenAi ChatGPT (и GPT-4), Anthropic Ai(Claude) (https://scale.com/blog/chatgpt-vs-claude ), HuggingFace, Google Bard. Рыночная оценка самого простого — HuggingFace — $2 млрд. долл.( https://techcrunch.com/2022/05/09/hugging-face-reaches-2-billion-valuation-to-build-the-github-of-machine-learning ) На платформе FractalGPT можно будет разработать, запустить и использовать нейросетевые модели и навыки для задач: 1. Системы синтеза новых идей из научных статей 2. Рассуждающие системы: намного более надежные чем текущие LLM с chain-of-thoughts 3. Системы конструирования описаний задач для решения прикладных задач (например: прочитай статьи про устойчивость зданий и создай проект небоскреба высотой Х для местности А с почвами С, опиши риски и ограничения К) 4. Вопросно-ответные системы для бизнеса в реальном времени обновляющие информацию 5. Системы автоматического доказательства теорем или проверки непротиворечивости доказательств. 6. Системы поиска недостоверной в новостных публикациях 7. Системы контролируемого диалога 8. Образовательные системы с контролем траектории обучения на базе мировых трендов 9. Системы описания умных городов на базе научных исследований, с поиском и объяснением узких мест в планировании инженерных коммуникаций и генерацией верифицируемых, надежных сценариев исправления ошибок и построения сценариев оптимизации застройки. По сути, языковые модели смогут генерировать новое знание проверяемым способом из множества документов и статей, регламентов, на вход принимая лишь структурное описание проблемы, ограничения. 10. Сервисы автоматизации судебной системы, юриспруденции и пр. — Что уже сделано? Проект на стадии идеи или уже есть код? — Идея уже проработана, создан небольшой прототип, proof-of-concept, он работает и это очень зажигает. — Когда что-то покажете? — Мы думаем, что потребуется от 4-7 мес. до момента, когда FractalGPT можно будет сравнить с ChatGPT и победить его в этом сравнении по качеству, спектру решаемых задач и стоимости внедрения(inference). Мы будем публиковать демо и новости о ходе разработки в Телеграм чате https://t.me/fractal_gpt Демо в виде кейсов того, как работает система ожидается через неделю.Чуть позже будут уже демо, в которых можно будет задавать свои вводные. Мы будем выпускать демо концептуально разных уровней: 1. сначала некий пруф-оф-концепт того, что фактологию вообще можно решить более эффективно, чем обучая LLM 2. затем пруф-оф-концепт того, что наше решение скейлится на множество доменов 3. затем пруф-оф-концепт того, что когда оно скейлится, не происходит падения качества — то есть, что существует некий закон скейлинга и это важно для коммерческой применимости, что-то вроде способности к генерализации, и так далее. — Где узнать больше информации?- Заходите в наш Телеграм чат: https://t.me/fractal_gpt Понимаш Захар Руководитель проекта «FractalGPT». Специалист в области машинного обучения и глубоких нейронных сетей. Разработчик собственного ИИ фреймворка AIFramework, а также системы логического вывода с мотивацией. Один из разработчиков: первого в РФ ИИ психолога Сабина и библиотеки для интерпретации генеративных нейросетей Transformer. Носко Виктор Продвижение и развитие проекта «FractalGPT». Генеральный директор, ООО «Аватар Машина». Специалист в области генеративных нейросетей трансформер, интерпретируемого ИИ. Визионер открытого и этичного ИИ. Докладчик конференций по искусственному интеллекту: Conversations.ai, OpenTalks.ai, AGIconf, DataStart, AiMen. Активный участник сообщества AGIRussia. Один из разработчиков: первого в РФ ИИ психолога Сабина, библиотеки для интерпретации генеративных нейросетей transformer.


Архитектура
Проблема
Решение



Научная новизна
Ожидаемые результаты
Области применения
Часто задаваемые вопросы (FAQ)
Авторы