
редакции
 Алексей Лигер
Алексей Лигер
Проектирование архитектуры системы для совместного редактирования системы

Проблемы, возникающие при отсутствии службы совместного редактирования документов.
Приведенный выше сценарий — один из примеров, который приводит к потере времени и разочарованию, когда пользователи работают над документом, обмениваясь файлами друг с другом. Некоторые преимущества использования онлайн-сервиса редактирования документов вместо настольного приложения заключаются в следующем:
Проблемы, возникающие при отсутствии службы совместного редактирования документов.
Приведенный выше сценарий — один из примеров, который приводит к потере времени и разочарованию, когда пользователи работают над документом, обмениваясь файлами друг с другом.
Для решения вышеописанной проблемы мы можем использовать онлайн-сервис совместного редактирования документов. Некоторые преимущества использования онлайн-сервиса редактирования документов вместо настольного приложения заключаются в следующем:
- Пользователи могут просматривать и комментировать документ во время его редактирования.
- Для получения новейших функций не требуется специальных аппаратных характеристик. Достаточно машины, на которой можно запустить браузер.
- Можно работать из любого места.
- В отличие от локальных настольных редакторов, пользователи могут просматривать долгосрочную историю документа и при необходимости восстановить старую версию.
Помимо ЦУБ Калуд, популярными сервисами онлайн-редактирования являются Google Docs, Etherpad, Microsoft Office 365, Slite и многие другие.
Проектирование
Служба совместного редактирования документов может быть разработана двумя способами:
- Он может быть разработан как централизованный объект, использующий архитектуру клиент-сервер для предоставления услуги редактирования документов всем пользователям.
- Он может быть разработан с использованием технологии peer-to-peer для совместной работы над одним документом.
Большинство коммерческих решений ориентированы на архитектуру клиент-сервер, чтобы иметь более тонкий контроль. Поэтому мы сосредоточимся на проектировании сервиса с использованием архитектуры клиент-сервис. Давайте посмотрим, как мы будем продвигаться в этой главе.
ребования к дизайну B6 Cloud
Давайте рассмотрим функциональные и нефункциональные требования к проектированию службы совместного редактирования.
Функциональные требования
Ниже перечислены действия, которые пользователь сможет выполнять с помощью нашего сервиса совместного редактирования документов:
- Совместная работа над документом: Несколько пользователей должны иметь возможность редактировать документ одновременно. Кроме того, большое количество пользователей должно иметь возможность просматривать документ.
- Разрешение конфликтов: Система должна передавать правки, сделанные одним пользователем, всем остальным участникам совместной работы. Система также должна разрешать конфликты между пользователями, если они редактируют одну и ту же часть документа.
- Предложения: Пользователь должен получать предложения по заполнению часто используемых слов, фраз и ключевых слов в документе, а также предложения по исправлению грамматических ошибок.
- Количество просмотров: Редакторы документа должны иметь возможность видеть количество просмотров документа.
- История: Пользователь должен иметь возможность видеть историю совместной работы над документом.
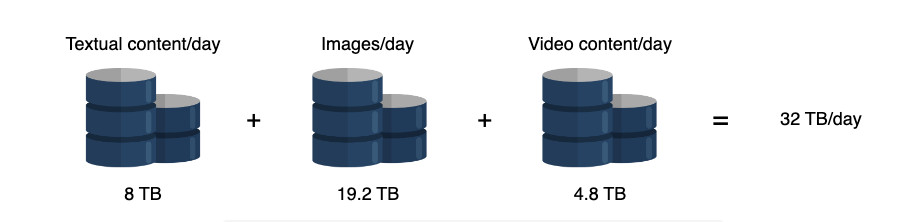
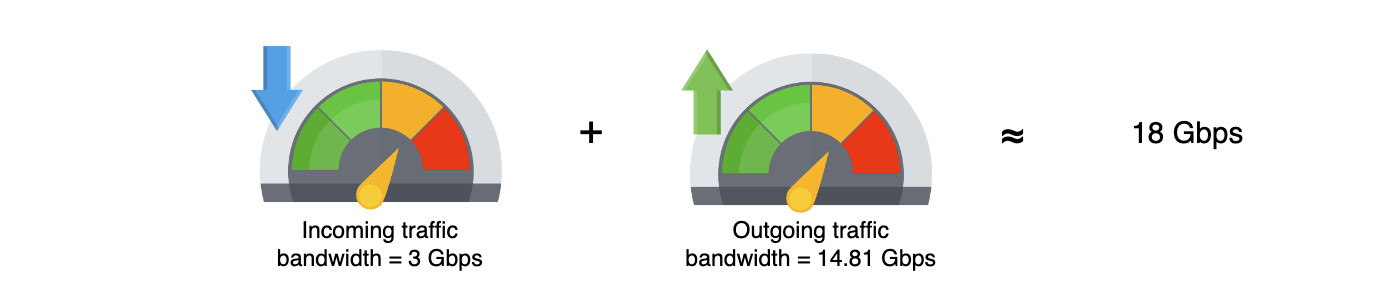
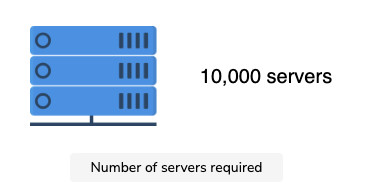
Редактор реальных документов также должен обладать такими функциями, как создание, удаление документов и управление доступом пользователей. Мы сосредоточились на основных функциях, перечисленных выше, но в последующих уроках мы также обсудим возможность использования других функций. Давайте сделаем некоторые оценки ресурсов, основываясь на следующих предположениях: Основываясь на этих предположениях, мы сделаем следующие оценки. Учитывая, что каждый пользователь может создать один документ в день, в общей сложности каждый день создается 80 миллионов документов. Ниже мы оцениваем объем хранилища, необходимого для одного дня: Примечание: Мы можем корректировать значения в таблице ниже, чтобы увидеть, как изменится оценка потребности в хранении. Объем памяти, необходимый для совместного редактирования документов в режиме онлайн, в день Общее хранилище, необходимое для одного дня, выглядит следующим образом: 8+19,2+4,8=32 ТБ в день Примечание: Хотя в наших функциональных требованиях указано, что мы должны вести историю документов, мы не включили требования к хранению исторических данных для краткости. Входящий трафик: Если предположить, что в сеть службы совместного редактирования загружается 32 ТБ данных в день, то потребность сети во входящем трафике будет следующей: Исходящий трафик: Чтобы оценить пропускную способность исходящего трафика, мы предположим количество документов, просматриваемых пользователем каждый день. Будем считать, что типичный пользователь просматривает пять документов в день. Тогда применим следующие расчеты: Примечание: Мы можем изменять значения в таблице ниже, чтобы увидеть, как меняются расчеты. Смотрите подробные расчеты Суммирование требований к пропускной способности Примечание: Общая требуемая пропускная способность равна сумме входящего и исходящего трафика. =3+14.7≈18 Гбит/с приблизительно. Суммирование требований к пропускной способности Примечание: Общая требуемая пропускная способность равна сумме входящего и исходящего трафика. =3+14.7≈18 Гбит/с приблизительно. Предположим, что один пользователь способен генерировать 100 запросов в день. Учитывая количество ежедневных активных пользователей, количество запросов в секунду (RPS) будет следующим: 100×80M = 8000M / 86400 = 92,6 тыс/сек. RPS не является достаточной информацией для подсчета количества серверов. Мы будем использовать следующее приближение для подсчета количества серверов. Чтобы оценить количество серверов, необходимых для выполнения запросов 80 миллионов пользователей, мы просто делим количество пользователей на количество запросов, которые может обработать сервер. Мы предполагаем, что наш эталонный сервер может обрабатывать 8 000 запросов в секунду. Таким образом, мы видим следующее: Неформально, уравнение выше предполагает, что один сервер может обслуживать 8 000 пользователей. При проектировании службы совместного редактирования документов мы будем использовать следующие компоненты. Мы выполним нашу разработку в два этапа. На первом этапе мы объясним различные компоненты и строительные блоки, а также причину их выбора в нашем проекте. На втором этапе мы опишем, как мы выполняем различные функциональные требования, изобразив рабочий процесс. Мы использовали следующий набор компонентов для завершения нашего проекта: На рисунке ниже показано, как различные компоненты координируются В следующих шагах мы объясним, как будут обрабатываться различные запросы после того, как они достигнут шлюза API: Примечание: Использование WebSockets ускоряет общую производительность и позволяет нам облегчить общение между пользователями, работающими над одним и тем же документом. Если объединить WebSockets с Redis-подобным кэшем, можно разработать эффективную функцию чата. Мы обсудили дизайн службы совместного редактирования документов, но не рассмотрели, как мы будем работать с одновременным внесением изменений в документ разными пользователями. Однако прежде чем обсуждать вопросы параллелизма, нам необходимо понять, что такое совместное редактирование текста. Документ — это композиция символов, расположенных в определенном порядке. Каждый символ имеет значение и позиционный индекс. Символ может быть буквой, цифрой, символом ввода (↵) или пробелом. Индекс представляет собой позицию символа в упорядоченном списке символов. Работа редактора текста или документа заключается в выполнении таких операций, как вставка(), удаление(), редактирование() и т.д. над символами в документе. Ниже показано изображение документа и то, как редактор будет выполнять эти операции. Совместная работа разных пользователей над одним и тем же документом может привести к проблемам параллелизма. Конфликты могут возникнуть, когда несколько пользователей редактируют одну и ту же часть документа. Поскольку у пользователей есть локальная копия документа, окончательное состояние документа на сервере может отличаться от того, что пользователи видят на своем компьютере. После того как сервер выложит обновленную версию, пользователи обнаружат неожиданный результат. Рассмотрим сценарий, в котором два пользователя хотят добавить несколько символов в один и тот же позиционный индекс. Ниже мы показали, как два пользователя, изменяющие одно и то же предложение, могут привести к противоречивым результатам: Как показано выше, два пользователя пытаются изменить одно и то же предложение «Образовательный от разработчиков». Оба пользователя выполняют insert() по индексу 10. Возможны следующие два варианта: Этот пример показывает, что операции, применяемые в другом порядке, не обладают свойством коммутативности. Рассмотрим еще один простой пример, в котором два пользователя пытаются удалить один и тот же символ из слова. Возьмем слово «EEDUCATIVE». Поскольку в этом слове есть лишняя буква «Е», оба пользователя захотят удалить лишний символ. Ниже мы видим, как может возникнуть неожиданный результат: Этот второй пример показывает, что разные пользователи, применяющие одну и ту же операцию, не будут идемпотентными. Таким образом, разрешение конфликтов необходимо там, где несколько участников редактируют одну и ту же часть документа одновременно. Из приведенных выше примеров мы поняли, что решение проблем параллелизма при совместном редактировании должно соответствовать двум правилам: Ниже мы приведем две известные техники разрешения конфликтов. Давайте обсудим две ведущие технологии, которые используются для разрешения конфликтов в совместном редактировании. Оперативная трансформация (ОТ) — это техника, которая широко используется для разрешения конфликтов в совместном редактировании. ОТ появилась в 1989 году и совершенствовалась на протяжении многих лет. Это безблокировочный и неблокирующий подход к разрешению конфликтов. Если операции между участниками совместной работы противоречат друг другу, OT разрешает конфликты и передает конечным пользователям правильное состояние конвергенции. В результате OT обеспечивает согласованность для пользователей. OT выполняет операции с использованием метода позиционного индекса для разрешения конфликтов, таких как те, о которых мы говорили выше. OT решает вышеуказанные проблемы, соблюдая коммутативность и идемпотентность. Совместные редакторы, основанные на OT, являются согласованными, если они обладают следующими двумя свойствами: Приведенные выше свойства являются частью модели согласованности CC, которая представляет собой модель для поддержания согласованности в совместном редактировании. OT имеет два недостатка: Оперативное преобразование представляет собой набор сложных алгоритмов, и его правильная реализация оказалась сложной для реальных приложений. Например, команде Google Wave потребовалось два года, чтобы реализовать алгоритм ОТ. За прошедшие годы исследовательское сообщество предложило различные модели согласованности. Некоторые из них специфичны для совместного редактирования, другие — для алгоритмов ОТ. Основные модели согласованности следующие: Другие модели включают модель CSM (причинность, однооперационные эффекты и многооперационные эффекты) и модель CA (причинность и допустимость). Предлагаются различные модели согласованности, и обычно новые модели являются надстройками более ранних. Бесконфликтный реплицированный тип данных (CRDT) был разработан в попытке улучшить ОТ. CRDT имеет сложную структуру данных, но упрощенный алгоритм. CRDT удовлетворяет требованиям коммутативности и идемпотентности, присваивая каждому символу два ключевых свойства: Каждому символу присваивается глобально уникальный идентификатор. Он глобально упорядочивает каждый символ. Каждая операция теперь имеет обновленную структуру данных: SiteID уникально идентифицирует сайт пользователя, запрашивающего операцию с помощью Value и PositionalIndex. Значение PositionalIndex может быть дробным по двум основным причинам. В приведенном ниже примере показано, что пользователь с ID сайта 123e4567-e89b-12d3 вставляет символ со значением A в PositionalIndex, равный 1,5. Хотя добавляется новый символ, позиционные индексы существующих символов сохраняются с использованием дробных индексов. Поэтому зависимость порядка между операциями исключается. Как показано ниже, вставка() между O и T не повлияла на позицию T. Предотвращение зависимости порядка между операциями CRDT обеспечивают надежную согласованность между пользователями. Даже если некоторые пользователи находятся в автономном режиме, локальные копии конечных пользователей сходятся, когда они возвращаются в сеть. Хотя такие известные платформы для редактирования документов в Интернете, как Google Docs, Etherpad и Firepad, используют OT, CRDT сделали параллельность и согласованность в совместном редактировании документов легкой задачей. Фактически, с помощью CRDT можно реализовать бессерверную одноранговую службу совместного редактирования документов. Примечание: OT и CRDTs — хорошие решения для разрешения конфликтов при совместном редактировании, но использование WebSockets позволяет выделить курсор участника совместной работы. Другие пользователи будут предвидеть положение следующей операции участника и, естественно, избегать конфликтов. Мы рассмотрели, как добиться сильной согласованности для разрешения конфликтов в документе с помощью двух технологий: оперативного преобразования (OT) и типов данных бесконфликтного разрешения (CRDT). Кроме того, база данных временных рядов позволяет нам сохранять порядок событий. После того как ОТ или CRDT разрешили все конфликты, конечный результат сохраняется в базе данных. Это помогает нам достичь согласованности в отношении отдельных операций. Мы также заинтересованы в том, чтобы состояние документа оставалось неизменным на разных серверах в центре обработки данных. Для одновременной репликации обновленного состояния документа в пределах одного центра обработки данных мы можем использовать одноранговые протоколы, такие как протокол Gossip. Эта стратегия не только улучшит согласованность, но и повысит доступность. Задержка может показаться проблемой, особенно когда два пользователя удалены друг от друга или от сервера. Однако пользователи поддерживают копии документов на своей стороне, в то время как данные передаются через WebSockets на конечные серверы. Поэтому воспринимаемая пользователем задержка будет низкой. Кроме того, пользователи чаще всего пишут текстовые данные в документах небольшого размера. Поэтому распространение данных между различными серверами в пределах одного объекта и между различными центрами обработки данных или зонами будет осуществляться с низкой задержкой. Кроме того, такие файлы, как видео и изображения, могут храниться в CDN для быстрого обслуживания, поскольку этот контент меняется нечасто. С практической точки зрения, число читателей и писателей онлайн-документа ограничено. Для читателей задержка не является проблемой, поскольку документ загружается только один раз. Таким образом, большинство читателей можно обслуживать из одного центра обработки данных. Для писателей следует выбрать оптимальную зону в качестве централизованного местоположения между участниками совместной работы над одним и тем же документом. Однако для популярных документов асинхронная репликация будет эффективным методом для достижения хорошей производительности и низкой задержки для большого числа пользователей. В целом, достижение высокой согласованности становится сложной задачей при асинхронной репликации. Наш проект обеспечивает доступность за счет использования реплик и мониторинга основного сервера и серверов-реплик с помощью служб мониторинга. Ключевые компоненты, такие как очередь операций и хранилища данных, управляют своей репликацией внутренне. Поскольку мы используем WebSockets, наши WebSocket-серверы могут соединять пользователей с серверами поддержки сессий, которые определяют, активно ли пользователь просматривает документ или работает над ним. Поэтому наличие нескольких WebSocket-серверов повысит доступность проекта. Наконец, мы используем кэширующие сервисы и CDN для повышения доступности в случае сбоев. Однако на данный момент мы не разработали схему управления аварийным восстановлением. Поскольку мы использовали микросервисную архитектуру, мы можем легко масштабировать каждый компонент по отдельности в случае, если количество запросов в очереди операций превысит ее емкость. Мы можем использовать несколько очередей операций. В этом случае каждая очередь операций будет отвечать за один документ. Мы можем направлять операции, запрашиваемые разными пользователями и связанные с одним документом, в определенную очередь. Количество порожденных очередей будет равно количеству активных документов. В результате мы сможем добиться горизонтальной масштабируемости.
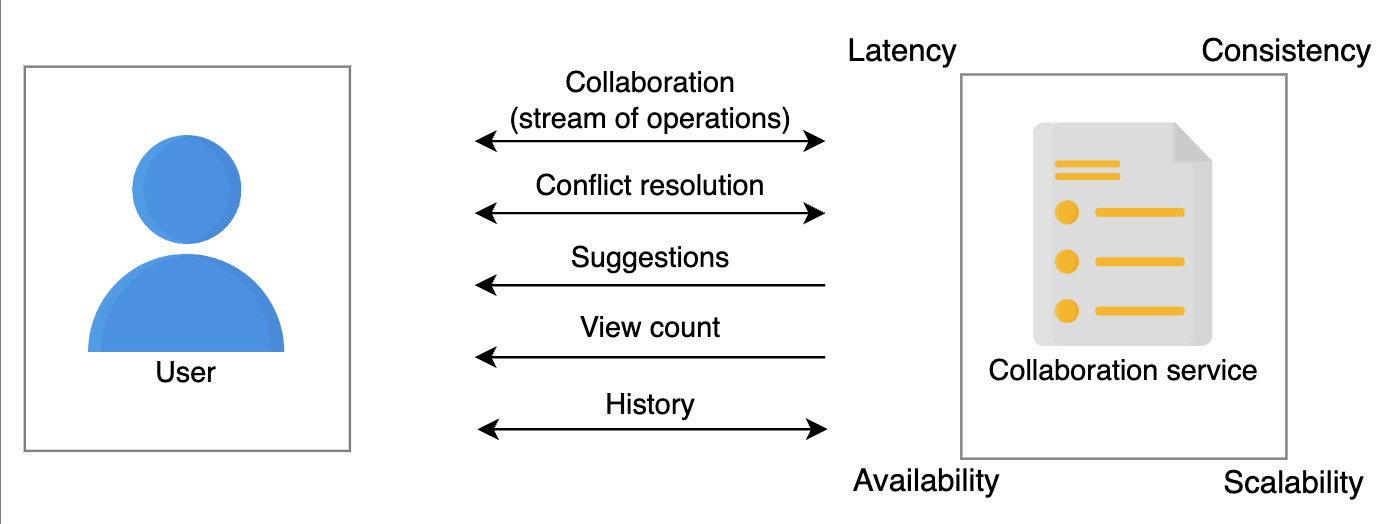
Функциональные и нефункциональные требования к сервису совместного редактирования
Нефункциональные требования
Оценка ресурсов
Оценка объема хранилища
Estimation for Storage Requirements

Оценка пропускной способности

Оценка количества серверов


Компоненты, которые мы будем использовать
Дизайн
Компоненты
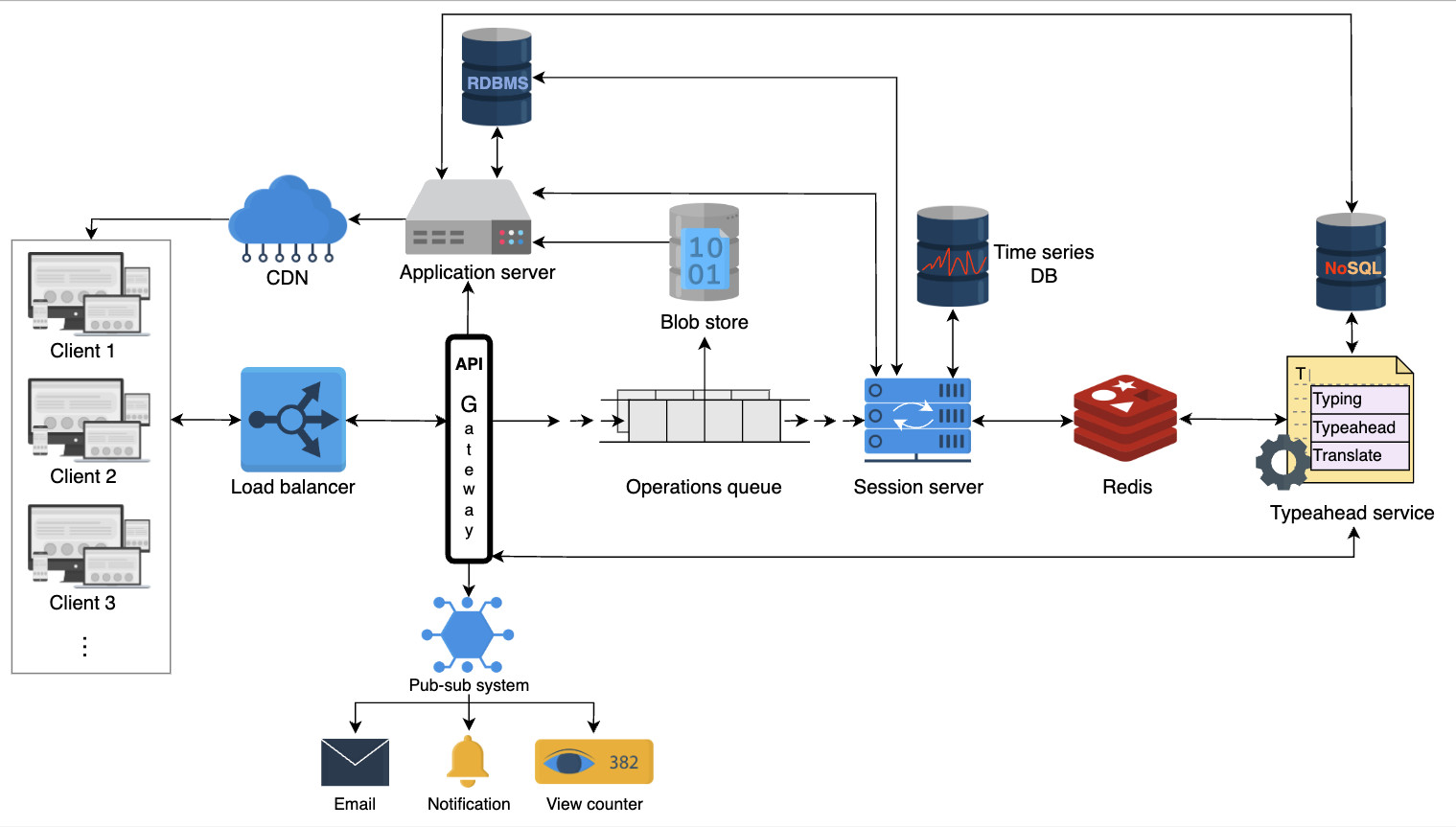
Рабочий процесс
Параллельность при совместном редактировании
Что такое редактор документов?
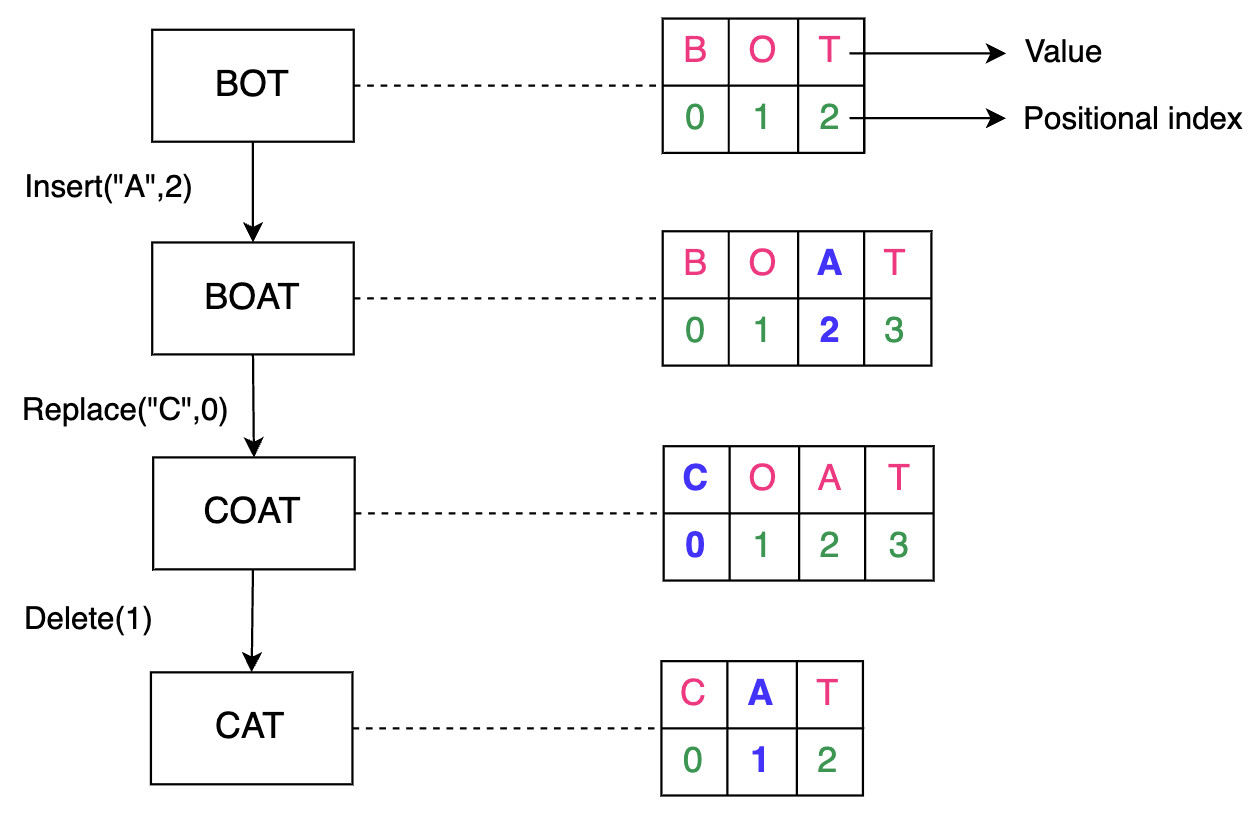
Проблемы параллелизма
Пример 1
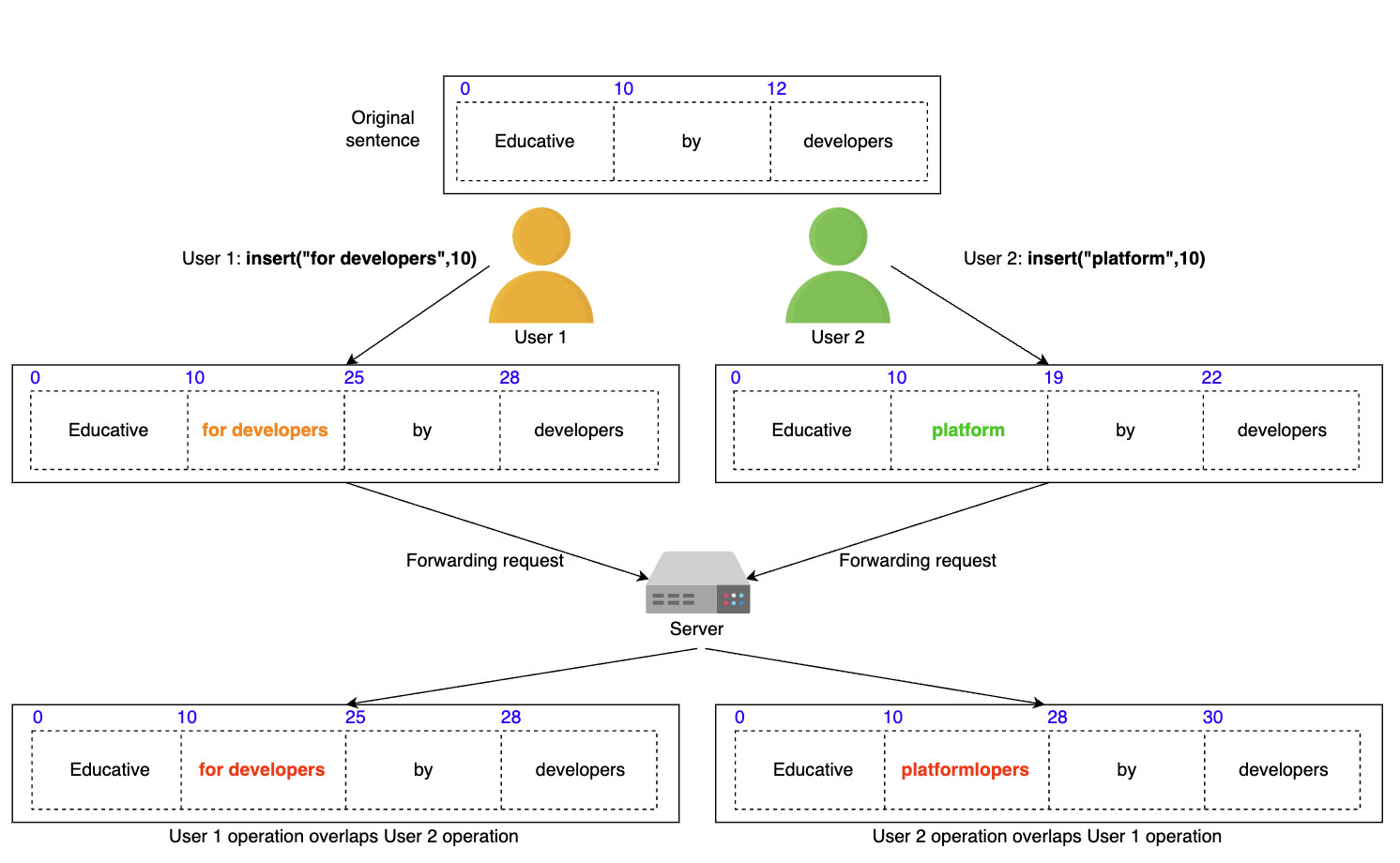
Пример 2

Техники для разрешения конфликтов
Оперативная трансформация
Модели согласованности в ОТ
Бесконфликтный реплицированный тип данных (CRDT)

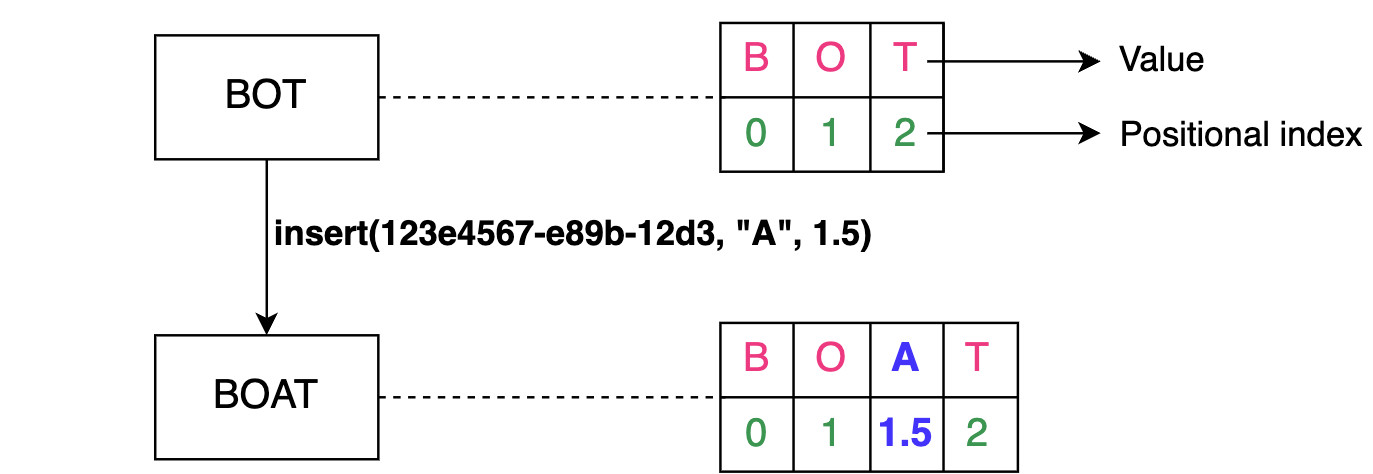
Согласованность
Задержка
Доступность
Выполнение нефункциональных требований
Согласованность
Задержка
Доступность
Масштабируемость
Масштабируемость