
редакции

Robots.txt для сайтов на Битрикс - 2022
Правильный robots.txt учитывает особенности Битрикс последних версий, а также robots.txt для популярных решений Aspro Next, Сотбит, Deluxe, Nextype Magnit и решений корпоративных сайтов Aspro.
При подготовке помимо рекомендаций поисковых сиcтем и анализа демо сайтов на решениях мы изучили индексацию реальных сайтов и попадание страниц в исключенные. Также в файле учтены get-параметры, которые чаще всего вызывают дублирование страниц, на которые «ругается» Яндекс Вебмастер, параметр ysclid от новой механики Яндекса для более точного распознавания поисковых фраз в браузерах с ограничением межсайтовых cookies и другие особенности.
Особенности предлагаемого robots для сайтов Битрикс
- Учет сортировки
- Фильтрация
- Учет пагинации
- Очистка от get параметров
- Закрытие служебных страниц
- Закрытие личного кабинета
- Работа с папкой local
- Открытие для индексации необходимых поисковикам файлов стилей
- Закрытие доступа наиболее активным и бесполезным ботам и ограничение скорости обхода всем кроме Яндекс и Google для снижения нагрузки
Robots.txt — это текстовый файл, который содержит указания — параметры индексирования сайта для роботов поисковых систем. Поисковики поддерживают стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
Назначение файла robots.txt
Как подсказывает Яндекс файл robots.txt необходим для того, чтобы запретить индексирование разделов сайта или отдельных страниц. Например, закрыть от индексации:
- страницы с конфиденциальными данными;
- страницы с результатами поиска по сайту;
- статистика посещаемости сайта;
- дубликаты страниц;
- разнообразные логи;
- сервисные служебные страницы.
Но. Не стоит забывать, что Google указывает на несколько иное назначение файла robots.txt, указывая основное назначение не запрет индексации, а снижение нагрузки на переобход сайта.
«Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска Google. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Чтобы исключить страницу из результатов поиска, следует использовать другой метод, например защиту паролем или директиву noindex. Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может показываться в Google. Чтобы полностью исключить страницу из Google Поиска, следует использовать другие методы.»
Настройка robots.txt
Начиная с версии 14 модуля Поисковая оптимизация больше не требуется создавать вручную файл robots.txt для сайта. Теперь его создание можно выполнять с помощью специального генератора, который доступен на странице Управление robots.txt (Маркетинг > Поисковая оптимизация > Настройка robots.txt). Форма, представленная на данной странице, позволяет создать, управлять и следить за файлом robots.txt вашего сайта. В админпанели Битрикс robots.txt можно сформировать в автоматическом режиме или исправить вручную. Настройки в админпанели Битрикса доступны по адресу /bitrix/admin/seo_robots.php?lang=ru Если в системе несколько сайтов, то с помощью кнопки контекстной панели не забывайте переключаться к нужному сайту, для которого необходимо просмотреть/создать файл robots.txt. На закладке «Общие правила» создаются инструкции, которые действуют для всех поисковых систем (ботов). Генерация необходимых правил осуществляется с помощью кнопок: На закладках «Яндекс и Google» настраиваются правила для ботов Яндекса и Google соответственно. Специальные правила для конкретных ботов настраиваются аналогично общим правилам, для них не задается только базовый набор правил и путь к файлу карты сайта. Кроме того, с помощью ссылок, доступных внизу формы, вы можете ознакомиться с документацией Яндекса и Google по использованию файла robots.txt. В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например: User-agent: Yandex — для обращения к поисковому роботу Яндекса; User-agent: Googlebot — в случае с краулером Google; User-agent: YandexImages — при работе с ботом Яндекс.Картинок. Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, дублирующиеся или временные страницы. Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела. Как правило, используется, чтобы дать доступ к определенной странице в закрытом разделе. Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь. Clean-param используется, когда нужно указать Яндексу (в Google не работает), что страница с GET-параметрами в адресе страницы (например, site.ru?type=no&sort=desk) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована, а указанные параметры должны быть удалены для индексации. Многие боты создают дополнительную нагрузку на сайт, не принося никакой пользы, а также помогая получать информацию с вашего сайта для анализа конкурентами. Чтобы этого не случалось, следует уделить время закрытию сайта от таких ботов. В файле robots.txt мы также добавили закрытие сайта от таких «вредных» нежелательных ботов". Robots c полным списком ботов см. на сайте https://bit.ly/37jn88T. Закрытие страниц пагинации. Леонтьева Ольга, специалист по маркетингу APRIORUM GROUP: Страницы пагинации стоит оставлять открытыми для индексирования, но закрывать их дубли. Дубли части создаются при использовании на сайте выбора «Показывать по» или сортировок. Также необходимо правильно организовать закрытие дублей при наличии выборки постранично и «показать все» одновременно. Дополнительно желательно убрать дублирование описания категории на страницах пагинации кроме первой, а также добавить уникализирующее дополнение с номером страниц в мета-теги (это может быть например «Стр. 2 из 100» или «25 запчастей из 1000» или «Страница 2 каталога»). Пропуски строк Неправильный регистр имени файла Неправильный регистр путей в файле Закрытие от индексации самого файла robots Использование кириллицы Для указания имен доменов используйте Punycode. Неверный протокол Crawl-Delay Директивы для Google с 2019 года Динамический роботс для мультирегиональности или мультисайтовости Проверка robots.txt Часто задают вопрос равнозначны ли директивы: Disallow: /auth/ Disallow: */auth/ Disallow: /auth Disallow: /auth/* Директивы не совсем равнозначны. Например, Disallow: /auth/ запрещает именно раздел http://site.ru/auth/ (начиная от первого уровня чпу), при этом страницы вида https://site.ru/info/auth/help/page останутся доступны при использовании такой директивы. Disallow: /auth/* — альтернативная запись директивы. Директива Disallow: /auth запретит все ссылки, которые начинаются с адреса http://site.ru/auth, например, страница http://site.ru/authentication тоже попадет под запрет. Директива Disallow: */auth/ корректно запретит страницу к индексированию на любом уровне.
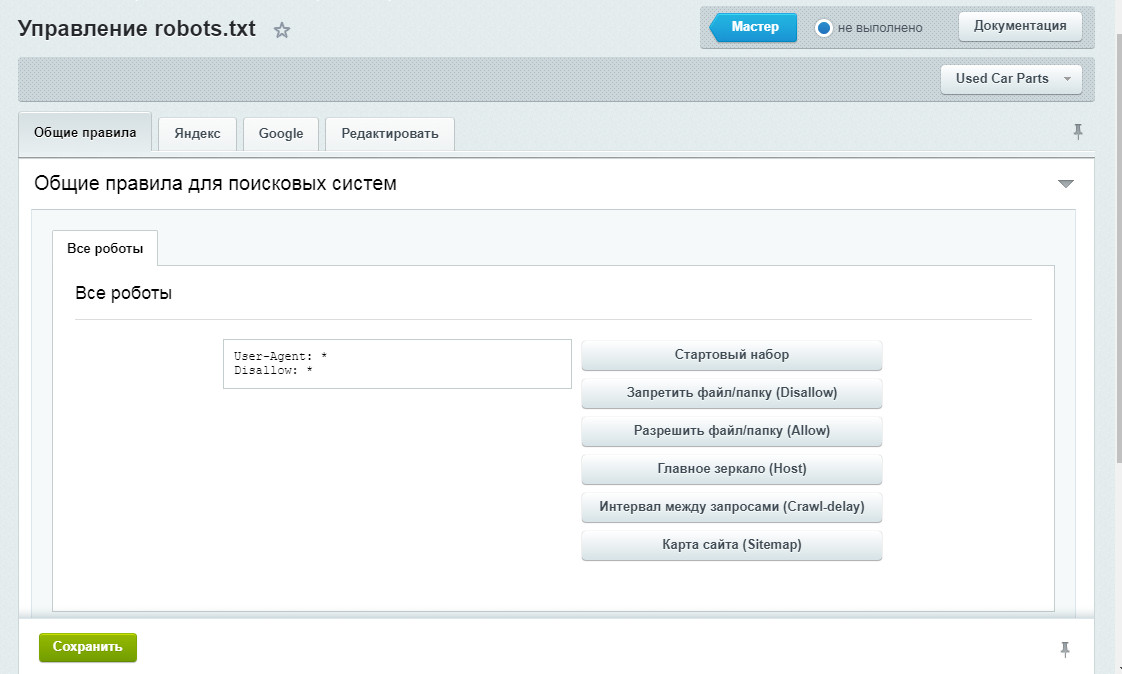
Директивы robots.txt
Блокировка ботов и снижение нагрузки на сервер
Частые ошибки в robots.txt
Дополнительные особенности
Частый вопрос про директиву Disallow