

Свой парсер или парсинг под ключ: что выбрать бизнесу
Компании, которые впервые сталкиваются с задачей сбора данных, часто думают, что проще поставить парсер на ноутбук и запустить. Формально можно. Но важно понимать, что сбор данных — это постоянная работа с меняющимися источниками.
Если владелец сайта поменяет вёрстку, перенесёт нужный блок или включит капчу, парсер перестанет корректно собирать информацию. При этом внешне всё будет выглядеть нормально, просто в выгрузке появятся пустые поля, пропуски и дубли.
Почему свой парсер нестабилен
Собственный парсер кажется удобным ровно до момента, когда источник данных начинает меняться. А это происходит постоянно.
Сайты перестраивают каталог, обновляют интерфейс, добавляют антиботы. Одно изменение, и весь алгоритм перестаёт понимать структуру страницы. Ошибка не бросается в глаза, но часть карточек теряется, номера телефонов перестают подтягиваться, таблицы расползаются.
Второй фактор — нагрузка. Не каждый ноутбук выдержит потоковые запросы, обработку миллионов строк и обход защит. То, что сервер обрабатывает за минуты, на обычном ПК может зависнуть.
Если у вас есть техническая команда, готовая обслуживать код, обновлять алгоритмы, разбираться с блокировками, можно запустить собственный парсер. В остальных случаях это рискованно.
Когда парсинг под ключ решает больше задач
Под ключ работают иначе: компания берёт на себя разработку алгоритма, техническую поддержку, контроль качества данных и весь процесс обновлений.
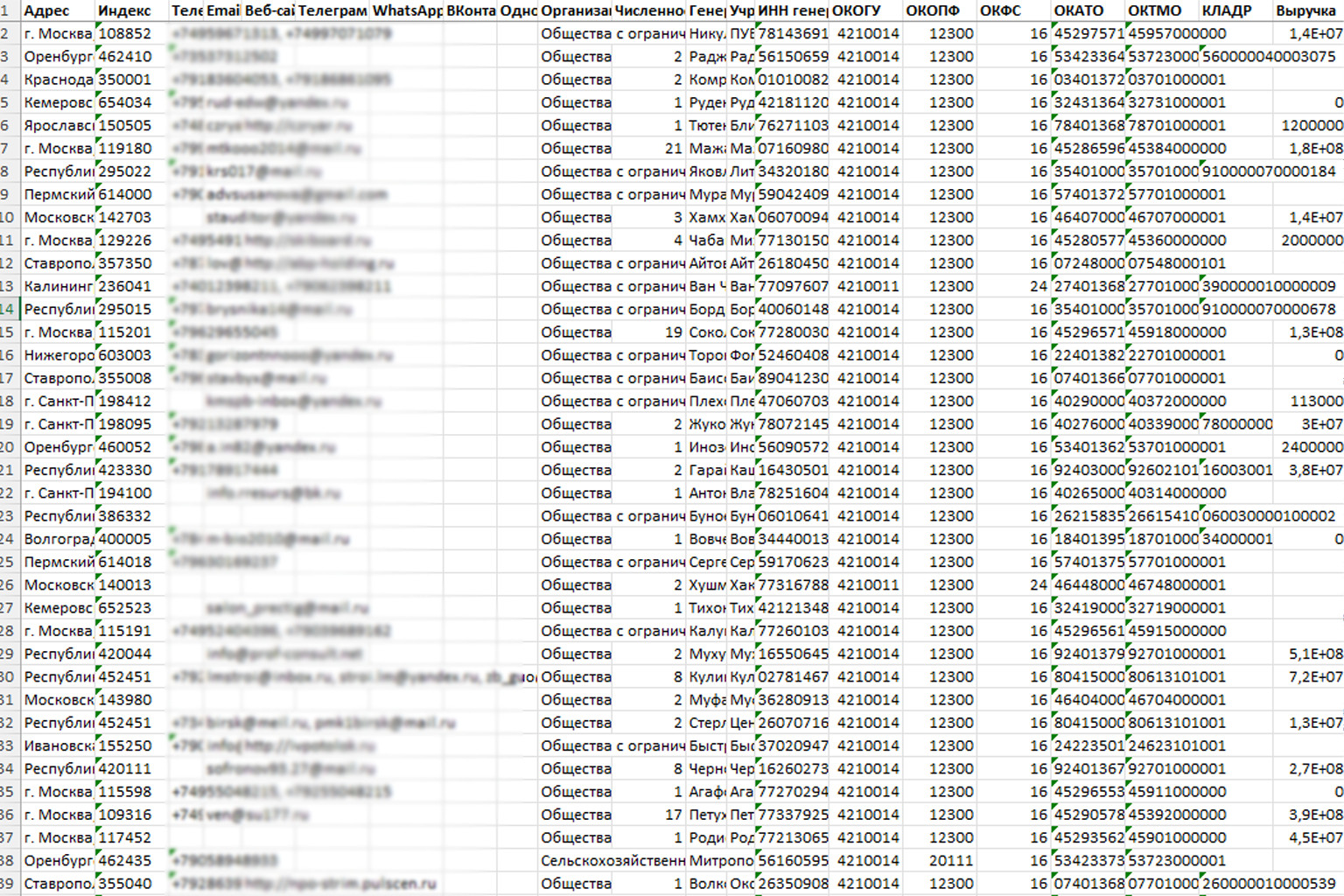
Например, мы Parsing Master парсим на серверных мощностях, проверяем поля, которые критичны для заказчика. Сбор ведётся по чётким параметрам: отрасль, ОКВЭД, регион, выручка, численность, контакты, наличие сайта. Причём параметры можно подобрать свои.
Это важно, потому что готовые универсальные парсеры работают только в рамках своих шаблонов. Они созданы под одну-две стандартные задачи: собрать аудиторию для рекламы, выгрузить SEO-данные, снять карточки товаров. Но как только запрос становится нестандартным, шаблон ломается.
Почему готовые парсеры сливаются на реальных бизнес-задачах
Большинство готовых решений не рассчитаны на глубокий и нетиповой сбор данных. Они работают строго по алгоритмам и не понимают задачи, которые требуют гибкости, логики и постобработки.
Например, к нам приходили с такими запросами:
«Определите, какие товары сейчас наиболее популярны у производителя по косвенным признакам».
«Соберите выписки ЕГРН и ЕГРИП из PDF, извлеките ключевые параметры и сведите всё в одну таблицу».
«Выгрузите миллион строк из каталога, но только те позиции, у которых определённая характеристика встречается в карточке».
Здесь нужно найти источник, понять логику данных, написать алгоритм и привести всё в удобный вид. Готовый парсер на такое не способен.
Именно такую кастомную разработку мы делаем: под каждый
источник, структуру и цель клиента. Качество данных всегда начинается с точного ТЗ. Чем
корректнее описана задача, тем быстрее и точнее мы соберём данные. Ниже структура, по которой мы составляем ТЗ с клиентами. 1. Источники данных
Сайты, каталоги, разделы, ссылки. Если формируем базу контактов, нужна отрасль,
регион, тип компаний. 2. Нужные поля
Какие данные собираем: товары, цены, контакты, отзывы, характеристики,
документы. Чем точнее, тем лучше. 3. Периодичность
Разовый сбор или регулярный мониторинг. От этого зависит архитектура и
нагрузка. 4. Цель задачи
Зачем вам эти данные: исследование, аналитика, лидогенерация, контроль дилеров,
мониторинг конкурентов. Формат выгрузки подстраивается под цель. 5. Формат результата
Excel, CSV, JSON, XML, выгрузка фото, структурированные файлы, API. Свой парсер подходит только тогда, когда у компании есть
ресурсы поддерживать его, отслеживать изменения и обновлять алгоритмы. Во всех
остальных случаях безопаснее и эффективнее передать задачу под ключ с
технической поддержкой, серверами, проверкой данных и гарантией стабильного
результата. Решить вашу задачу может Parsing Master. Рассчитайте стоимость и получите скидку 20% на первый заказ.
Структура технического задания на парсинг: что
обязательно указать