

Как построить оптимальную архитектуру управления данными в компании? Что такое модель a16z? Типы DWH-архитектур
Умение извлекать пользу из данных становится критическим для роста компании. Продуктовые гипотезы, персонализация, прогнозирование спроса, контроль финансов, автоматизация маркетинга — все это невозможно без доступа к актуальной, качественной и структурированной информации.
Меняется и подход бизнеса к работе с данными: аналитику автоматизируют с помощью ИИ и ML, грамотность в области данных становится ключевой компетенцией, появляются новые функциональные роли — Chief Data Officer, Data Scientist, Machine Learning Engineer, специалист по этике ИИ и другие.
Для анализа и управления данными компании внедряют не просто ПО, а масштабные инфраструктуры данных, которые в первую очередь ориентированы на стоящие бизнес-задачи и перспективы масштабирования, а не технологии.
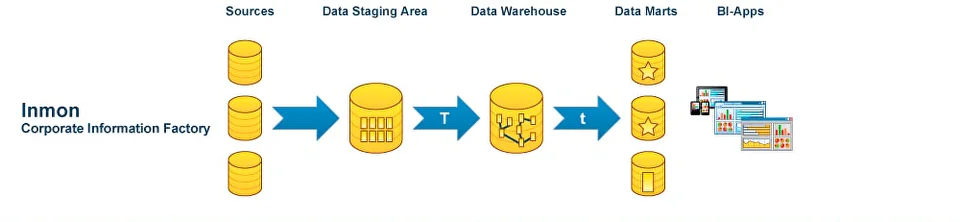
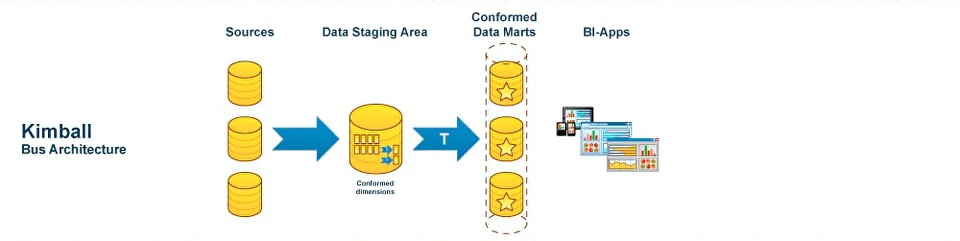
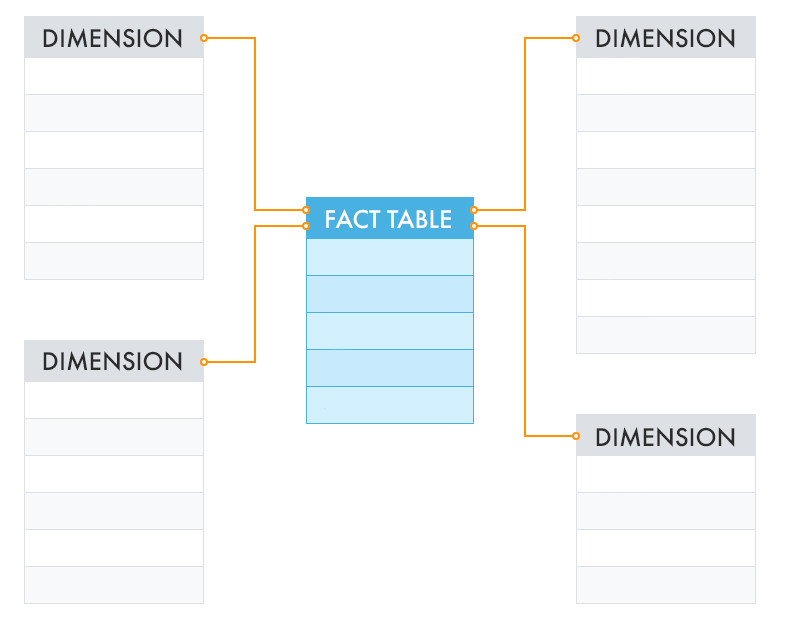
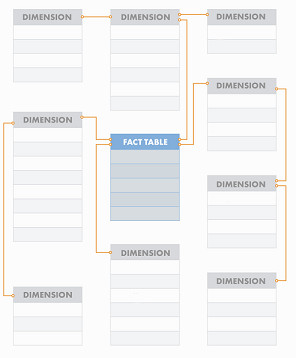
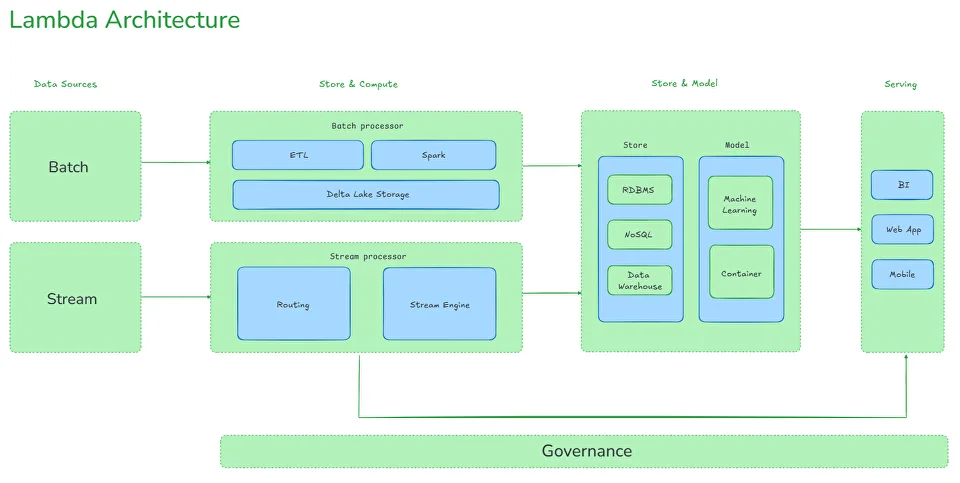
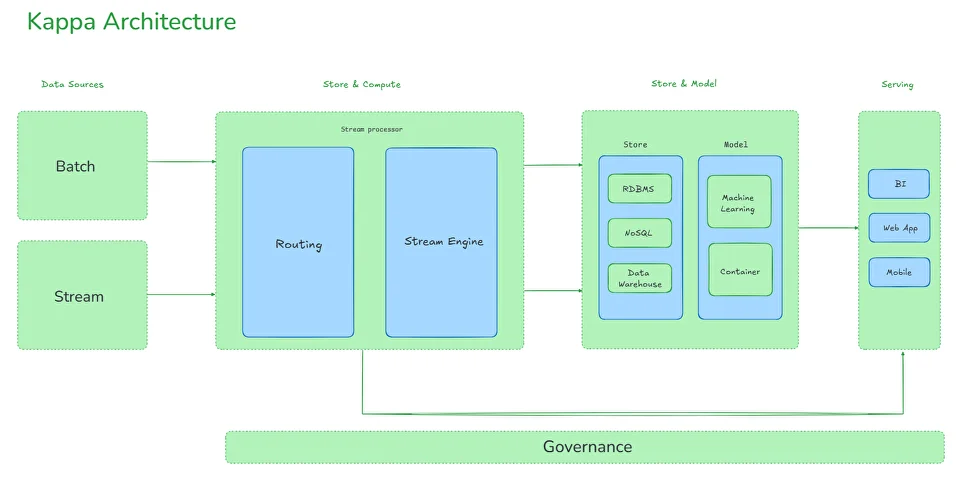
Корпоративное хранилище DWH становится основой этой инфраструктуры. Оно представляет собой сложную систему, обеспечивающую процессы извлечения, обработки, структурирования данных. На протяжении десятилетий в индустрии сформировались разные подходы к построению DWH — от классических моделей Инмона и Кимбалла до более современных архитектур Лямбда и Каппа, появившихся в эру Big Data и real-time аналитики. Выбор подхода к проектированию зависит от задач компании. Команда Qlever зарекомендовала себя на рынке как эксперт в области внедрения корпоративных хранилищ данных. При проектировании хранилищ мы выбираем системный подход — так называемую модель a16z (Unified Data Infrastructure 2.0), которая стремится объединить все компоненты управления данными в единую платформу. В этой статье мы расскажем, как эволюционировали подходы к архитектуре хранилищ данных, и какая из них может стать единой опорой для аналитики, BI, ML и бизнес-решений. Уильям Инмон, отец концепции корпоративных хранилищ данных, заложил основы архитектуры DWH еще в 1980-х. Он предложил классический подход к построению DWH «сверху вниз», который предполагает создание централизованного, нормализованного хранилища данных на уровне предприятия (Enterprise Data Warehouse), из которого уже формируются витрины данных для бизнес-пользователей. Основной акцент в подходе Инмона делается на целостности и качестве данных. Для интеграции данных из различных источников, их преобразования и загрузки в хранилище активно применяются процессы извлечения, трансформации и загрузки — ETL. Все данные сначала проходят очистку и нормализацию, после чего попадают в хранилище в форме 3NF (третьей нормальной форме), которая позволяет избежать аномалий при добавлении, удалении и обновлении данных, уменьшает дублирование и упрощает управление базой данных. На основе очищенных данных строятся Data Marts (витрины данных) — тематические подмножества, ориентированные на нужды конкретных подразделений. Подход позволяет адаптировать данные для различных бизнес-задач, обеспечивает масштабируемость и доступ к подготовленной, согласованной информации для аналитики. Такая модель особенно ценна для компаний с высокой регуляторной нагрузкой, сложной структурой и необходимостью строгого контроля качества данных. Несмотря на высокую стоимость проектирования и продолжительный период внедрения, эта архитектура обеспечивает долгосрочную устойчивость и согласованность аналитики во всей компании. Ральф Кимбалл, американский эксперт по аналитике данных, предложил подход, противоположный методу Инмона, который направлен на практическую ценность для бизнеса. Архитектура DWH строится «снизу вверх»: сначала создаются доменно-ориентированные — структурированные по областям знаний или ответственности — витрины данных для отдельных бизнес-направлений, которые затем могут быть объединены в хранилище. Кимбалл предложил использовать денормализованные модели данных: Подход Кимбалла делает данные более доступными для аналитиков и BI-инструментов, а проект — более гибким и адаптивным к изменениям требований. Архитектура позволяет начать использовать аналитику гораздо раньше, не дожидаясь построения централизованного хранилища, оперативно внося изменения. Проект внедрения дробится на этапы, становится более предсказуемым и управляемым. Такой подход часто выбирают компании, которым важна быстрая окупаемость аналитических инвестиций и высокая вовлеченность бизнес-пользователей. При масштабировании и усложнении структуры возрастает риск дублирования и несогласованности данных между витринами. С развитием технологий Big Data и ростом потребности в точной обработке данных в реальном времени, встал вопрос о совмещении быстрой потоковой (стриминговой) обработки с пакетным режимом. Ответом стала Лямбда (Lambda) архитектура, предложенная Натаном Марцом. Архитектура включает три уровня: Ключевое преимущество Лямбда-архитектуры — точность и полнота анализа при одновременной возможности получать данные здесь и сейчас. Благодаря параллельной обработке данных в пакетном и потоковом режимах компания может и ежедневно пересчитывать стратегические метрики, и получать данные в режиме, близком к реальному времени: например, по текущим продажам, поведению клиентов или системным инцидентам. Такая архитектура особенно актуальна в сферах, где важно принимать решения быстро, но при этом нельзя жертвовать полнотой данных — например, в eCommerce, финтехе или логистике. При этом архитектура довольно сложна в реализации и сопровождении: приходится поддерживать два параллельных конвейера обработки, что увеличивает стоимость владения и риск рассинхронизации между слоями. В качестве альтернативы Лямбда-архитектуре для устранения дублирования логики между batch- и speed-слоями была-предложена Каппа (Kappa) архитектура. В Kappa-архитектуре используется единый стриминг-конвейер: все события последовательно сохраняются в брокере сообщений (например, Apache Kafka или Apache Pulsar). Это позволяет при изменении логики обработки переигрывать весь поток заново, без необходимости поддерживать отдельный batch-слой. Подход устраняет избыточность данных и обеспечивает быстрое масштабирование. Он особенно подходит для проектов, в которых важна минимальная задержка между поступлением и обработкой данных. Переход к Kappa-архитектуре означает для бизнеса снижение затрат на поддержку и развитие аналитических систем. Поскольку здесь используется единый поток обработки данных, упрощается логика пайплайнов, снижается дублирование кода и точек отказа. Реализация Kappa-архитектуры требует зрелой инфраструктуры, но позволяет бизнесу быстрее реагировать на происходящее и легче масштабировать решения. В 2020 году эксперты легендарной венчурной компании Andreessen Horowitz (a16z) провели исследования среди передовых data-driven компаний и выделили ключевые тренды в инфраструктуре данных: Кроме того, активно растет число разнообразных источников данных (SaaS, API, внешние источники), сливаются в единую data-платформу аналитическая и ML-инфраструктура, растет популярность dbt и принципов DataOps — версионирование, CI/CD, тестирование данных и т.д. Все эти наблюдения приводят к выводу: классическая архитектура хранилища данных больше не отражает действительность. На смену ей Andreessen Horowitz предложили единую инфраструктуру данных Unified Data Infrastructure, в которой все ключевые процессы работы с данными (сбор, хранение, трансформация, анализ, ML) строятся на единой платформе, а отдельные технологии подбираются в зависимости от уникальных задач. Инфраструктура данных постоянно совершенствуется. На текущий момент актуальна версияUnified Data Infrastructure 2.0, цель которой — устранить разрозненность в ИТ-инфраструктуре и повысить управляемость данных на всех этапах жизненного цикла. Данные поступают в хранилище из разных источников — CRM, ERP, веб-сервисов, сенсоров, Excel-файлов, БД и других. Слой обеспечивает доставку данных из источников в хранилище данных. На нем осуществляется репликация данных, real-time сценарии загрузки, оркестрация дата-пайплайнов и Reverse ETL — процесс обратного перемещения преобразованных данных в операционные инструменты и бизнес-приложения. Непосредственно Data Warehouse (DWH) и (или) Data Lake, Data Lakehouse хранилища данных. Storage oбъединяет структурированные данные в единую версию правды для последующей аналитики, Data Science или ML. Слой, в котором осуществляются аналитические запросы, ad-hoc обработка, выполнение SQL/ML-запросов в моменте Слои, в которых осуществляются операции изменения структуры и содержания данных: очистка, нормализация, агрегация, объединение Инструменты для предоставления данных в удобной, понятной для пользователя форме BI-дашбордов, отчетов, визуализаций. Доставка ML-инсайтов в продуктовые или операционные системы. Интегрируется со всеми уровнями архитектуры — от хранения до аналитики, и обеспечивает: *** Unified Data Infrastructure (2.0) — это устойчивая, гибкая и масштабируемая инфраструктура, охватывающая все аспекты работы с данными — от BI до ML. Такой подход позволяет эффективно обрабатывать большие объемы данных, использовать современные инструменты аналитики, а также обеспечивает: Выбор архитектуры на основе модели a16z (Unified Data Infrastructure 2.0) позволяет бизнесу отказаться от сложносоставных, изолированных решений в пользу единой, сквозной платформы данных. Такой подход особенно полезен в быстрорастущих компаниях или тех, кто переходит к data-driven управлению: сокращается путь от сбора данных до действия, появляются реальные сценарии автоматизации и предиктивной аналитики, а инфраструктура остается устойчивой и масштабируемой. Именно поэтому компания Qlever Solutions использует архитектурный подход к построению DWH, ориентированный на модель a16z, который сохраняет согласованность, управляемость и возможность изменения каждого компонента хранилища.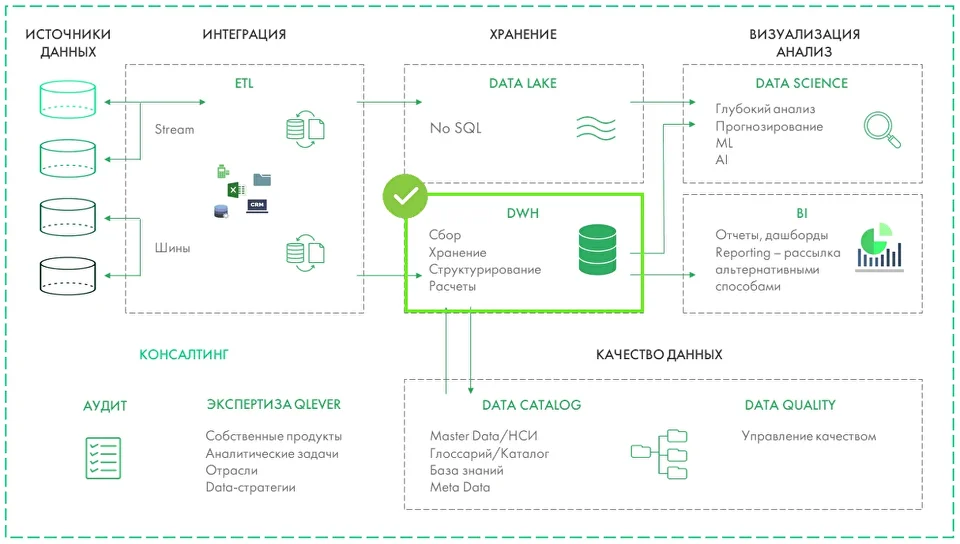
Подход Инмона: корпоративное хранилище данных «сверху вниз»
Подход Кимбалла: звезды и снежинки
Лямбда-архитектура: объединение потоковой и пакетной обработки
Kappa-архитектура: все — поток
Что такое модель a16z или Unified Data Infrastructure 2.0
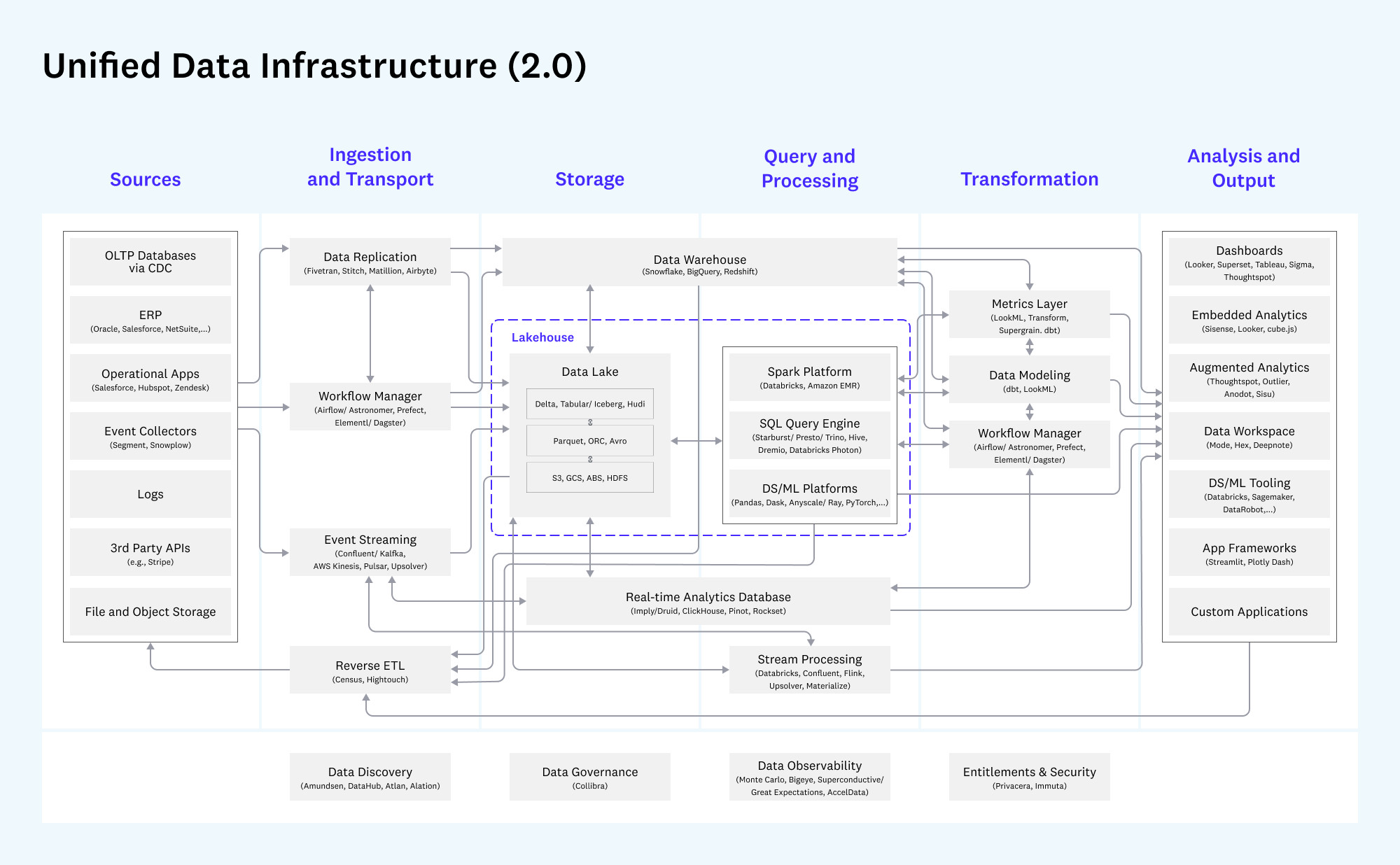
Как устроена архитектура Unified Data Infrastructure 2.0
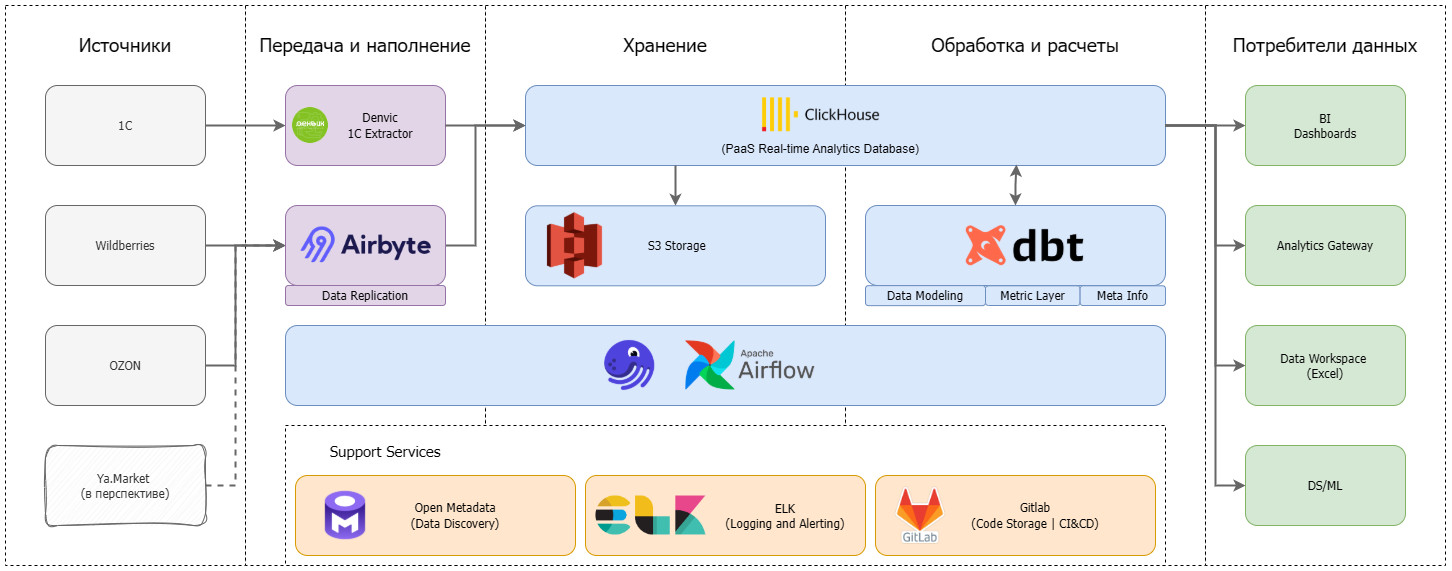
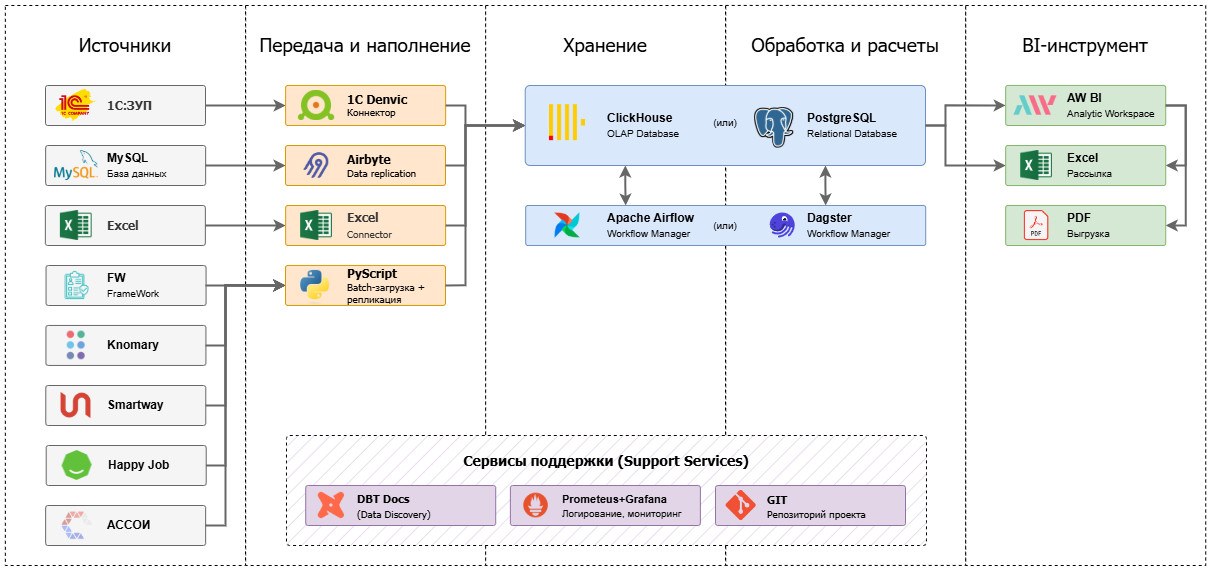
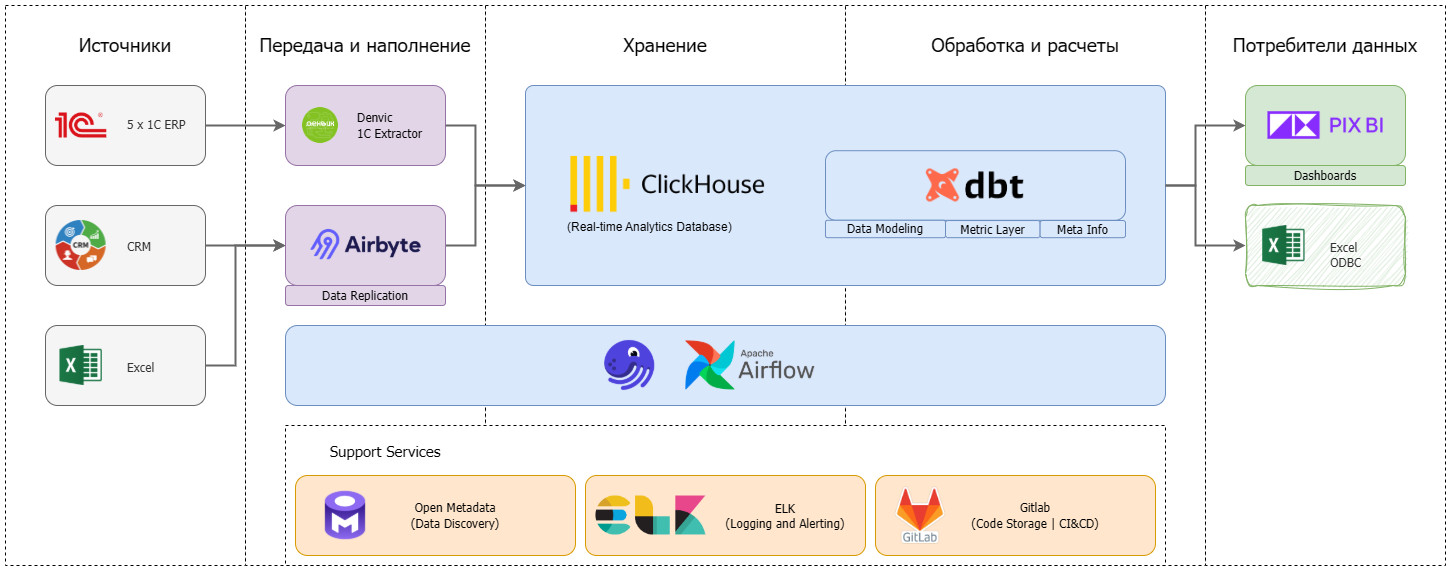
DWH, которое работает на ваш бизнес