
редакции

Как я автоматизировал подбор товаров для тендеров: ИИ вместо рутины и Ctrl+F
Любой специалист по закупкам или тендерам знает эту боль: открываешь техническое задание (ТЗ) заказчика, а там спецификация на 100 позиций. Причем каждая позиция описана не четким артикулом, а целым абзацем сплошного текста: смесь габаритов, материалов, ссылок на ГОСТы и допусков.
Задача специалиста — найти под эти пространные требования подходящие товары в своей базе или в прайс-листах дистрибьюторов (где могут быть десятки тысяч строк), сопоставить их и просчитать экономику. А если человек новый в нише? А если специфика сложная? Обычно это решается вычленением ключевых слов и бесконечным нажатием Ctrl+F по вкладкам Excel. Это долго, дорого и ведет к ошибкам из-за банальной усталости.
Я решил автоматизировать этот процесс и собрал B2B-инструмент на стыке локальных баз данных, алгоритмов обработки естественного языка (NLP) и больших языковых моделей (LLM).
В этой статье я расскажу, как устроен продукт «под капотом», с какими проблемами я столкнулся при сопоставлении неструктурированных данных и как выстроил архитектуру, которая заменяет рутину машинным интеллектом.
Откуда брать и как структурировать данные?
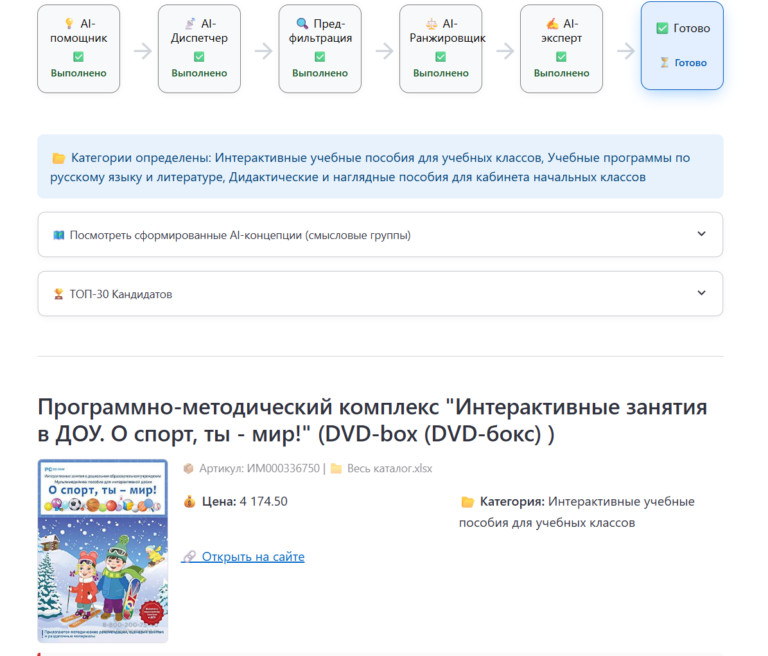
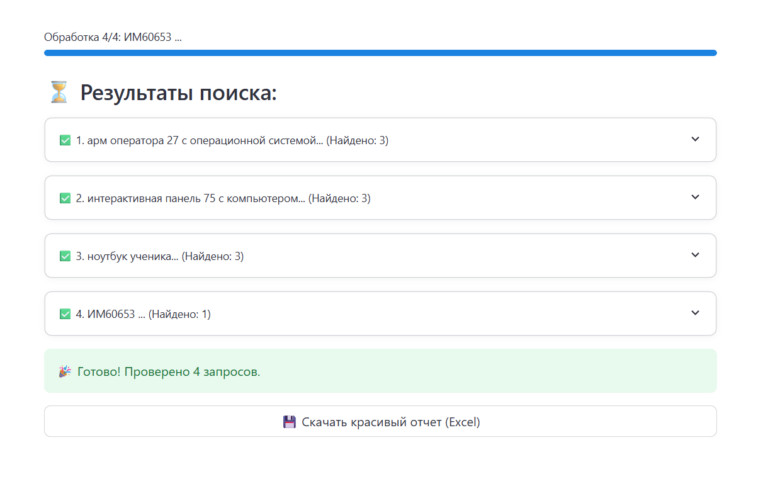
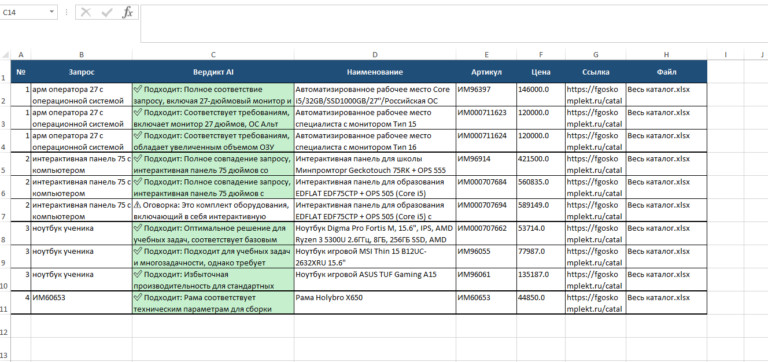
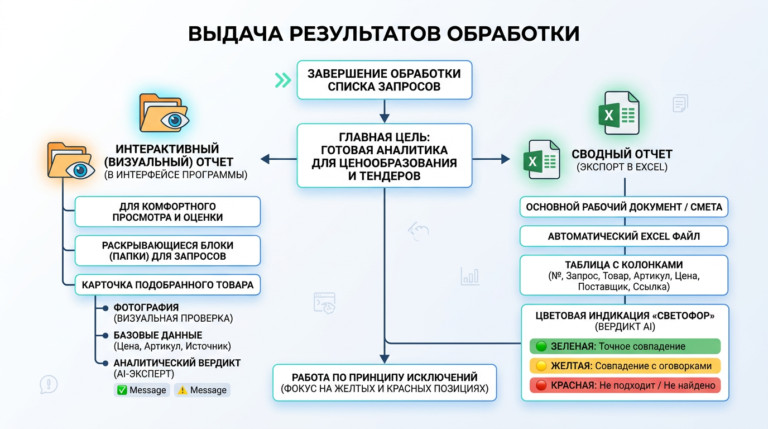
Чтобы ИИ искал точно, ему нужна структурированная база. Если у компании есть выгрузки из 1С, CSV или готовые прайсы в Excel — проблема решается простой загрузкой в нужную директорию. Но на практике прайс-листы есть не всегда. Часто товары представлены только в веб-каталоге производителя. Писать кастомный парсер под каждый сайт — утопия. Поэтому в систему пришлось интегрировать модуль автоматического сбора данных. Как это работает сейчас: Обычный полнотекстовый или даже векторный поиск здесь пасует. В тендерном ТЗ слишком много «мусорных» слов, которые сбивают алгоритм. Поэтому сопоставление требований заказчика с доступным ассортиментом я реализовал через многоступенчатый конвейер. Вот как выглядит флоу обработки одной позиции: Чтобы инструмент был применим в реальном бизнесе, я разделил логику интерфейса на два сценария. Режим 1: Точечный подбор (Одиночный поиск)Идеально для сложных, единичных запросов. Пользователь не вычленяет слова, он просто копирует весь огромный абзац из документации и вставляет в поиск. Можно задать фильтр источников (например, искать совпадения только в каталоге конкретного завода). Система выдает карточку лучшего кандидата. Режим 2: Пакетная обработка (Batch-режим)Основная «киллер-фича» для снабженцев. Специалист загружает в систему файл со сметой (десятки или сотни строк). Программа считывает колонку с требованиями и выстраивает очередь. Дальше процесс идет полностью в фоне. На глубокий машинный анализ одной сложной позиции уходит около минуты. Пока программа автономно перебирает базы и сопоставляет характеристики, человек может вести переговоры или заниматься другими задачами. Я понимал, что выдавать просто «сырые» ссылки на совпадения — бессмысленно. Цель B2B-продукта — дать готовую аналитику для принятия решений. В интерфейсе результаты группируются по папкам: исходная строка ТЗ → раскрывающийся блок с товарами-кандидатами. Подтягиваются фотографии с сайтов доноров, цены и артикулы. Но главное происходит при экспорте. Итоговым продуктом работы программы является сводная таблица Excel. И здесь я внедрил цветовую индикацию (систему «Светофор»), основанную на выводах AI-Эксперта: Такой подход меняет парадигму работы: человек больше не ищет товары, он работает по принципу исключений, проверяя только «желтые» спорные позиции. Помимо первичного просчета тендеров (когда нужно за час понять маржинальность спецификации на 70 пунктов), архитектура отлично решает еще две задачи: Внедрение AI-пайплайна превращает задачу, на которую раньше уходили дни механической работы, в фоновый процесс на пару часов. Человеческий фактор (усталость, потеря концентрации) сводится к минимуму. Сейчас проект активно развивается. Если вы работаете в закупках, тендерах, оптовых продажах, или вам просто интересно обсудить архитектуру LLM-решений для B2B и протестировать инструмент на своих базах данных — буду рад пообщаться.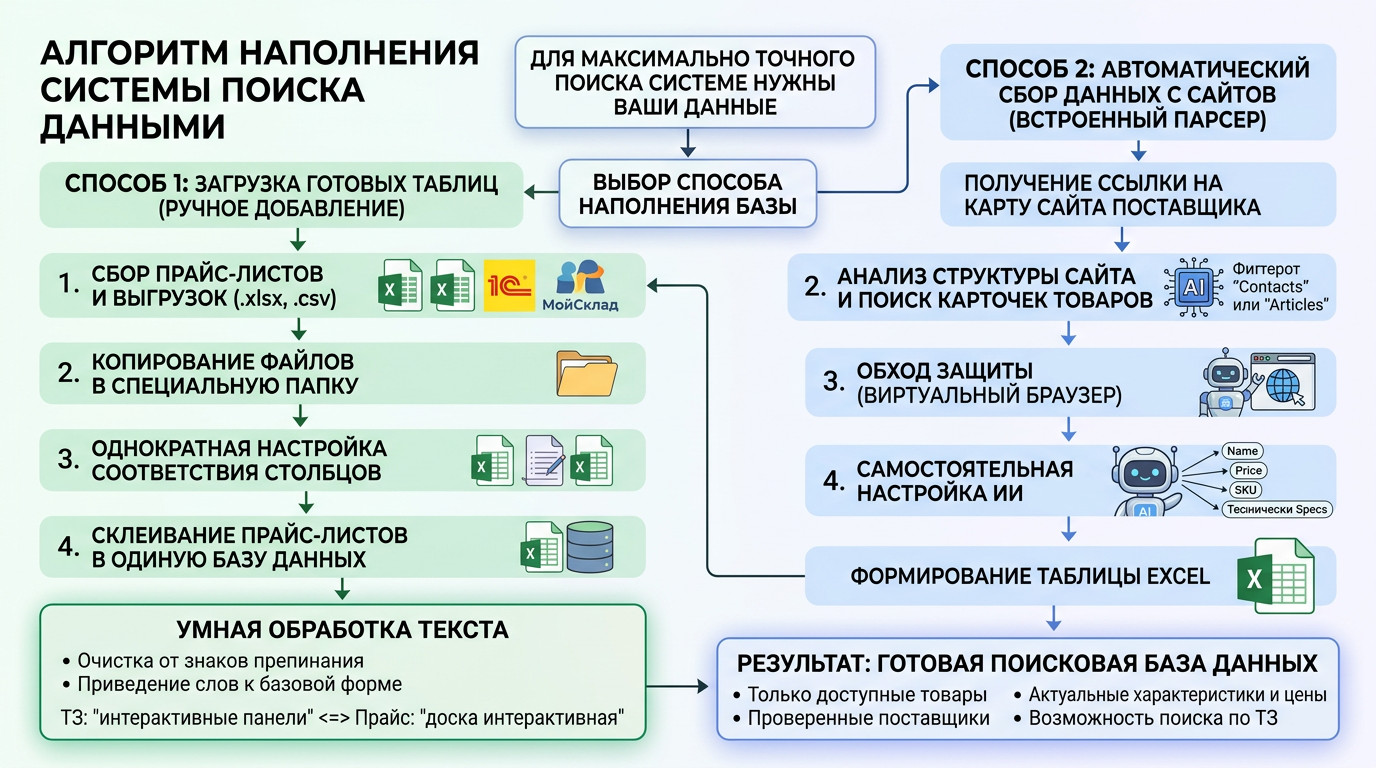
Как работает поиск (Pipeline обработки запроса)
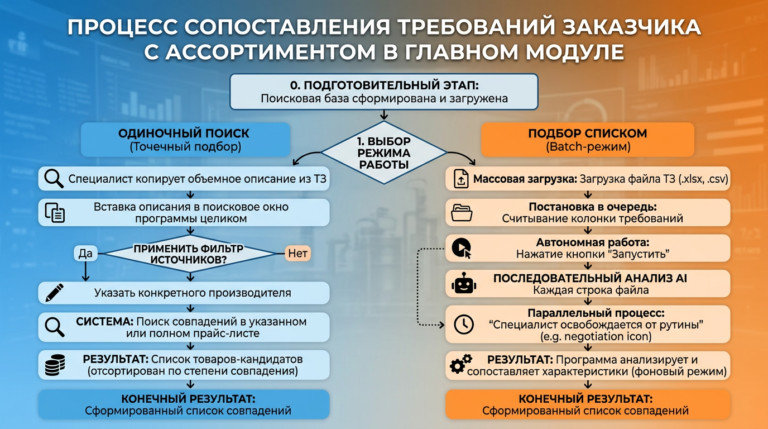
Пользовательский опыт: 2 режима работы
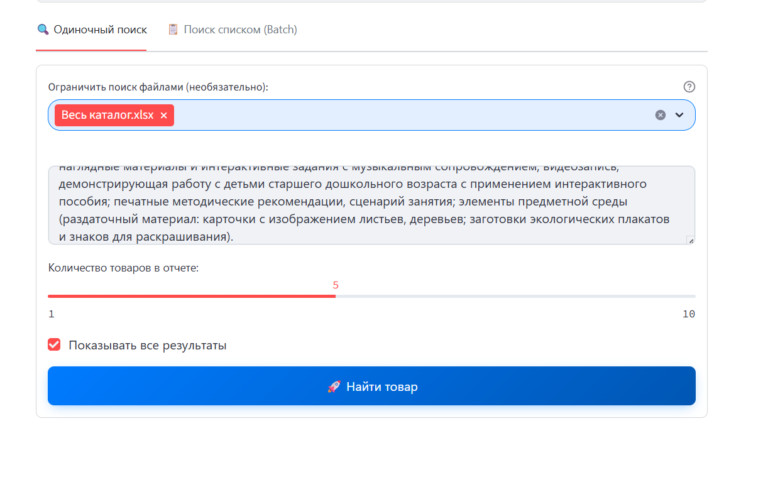
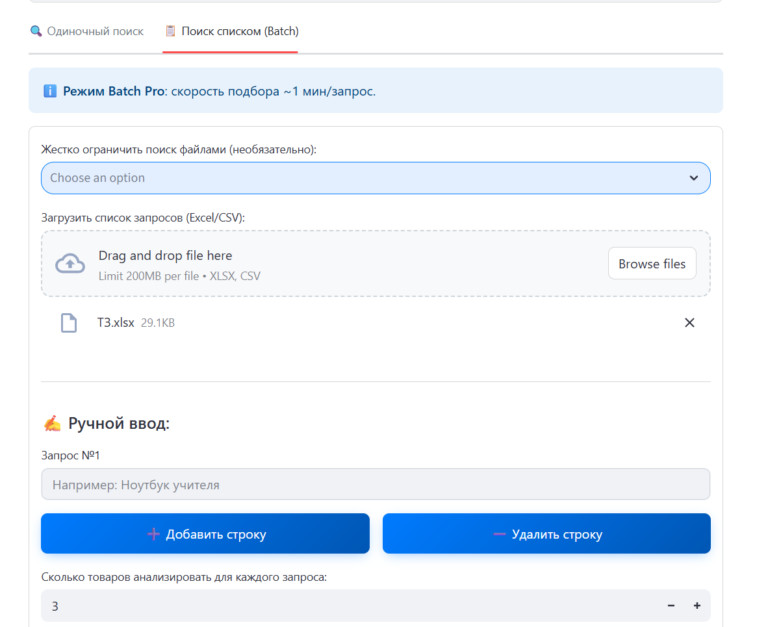
Что на выходе? Интерфейс vs. Excel
Бизнес-кейсы: где это применяется?
Итоги
Более подробно я написал алгоритм здесь