

Восстановление ИТ-инфраструктуры: как защитить бизнес от сбоев
Сбой ИТ-инфраструктуры способен парализовать любую компанию и привести к финансовым и имиджевым потерям. Настоящая защита — не экстренные меры после катастрофы, а заранее продуманная стратегия восстановления (Disaster Recovery Plan, DRP), гарантирующая непрерывность бизнес-процессов. Рассмотрим, как компании строят эффективные планы аварийного восстановления и какие технологии помогают минимизировать риски.
Привет, Spark! С вами Дмитрий Бессольцев, руководитель компании ALP ITSM. С 1996 года мы занимаемся ИТ-аутсорсингом и не раз были свидетелями того, как крупный сбой парализовал, казалось бы, успешный бизнес. Наш опыт показывает: надеяться на то, что пожар, потоп или атака шифровальщика обойдут вас стороной — значит подвергать компанию неоправданному риску. Гораздо эффективнее иметь четкий план действий. В этой статье мы разберем, как создать такой план (Disaster Recovery Plan) и превратить его в надежную страховку для вашего бизнеса.
Прочитав статью, вы узнаете:
- Почему Disaster Recovery Plan (DRP) — это не то же самое, что и резервное копирование. Мы объясним, в чем разница и почему одних только бэкапов недостаточно для защиты бизнеса.
- Как оценить риски с помощью двух ключевых метрик — RPO и RTO. Вы поймете, как определить, какой объем данных вы готовы потерять и как быстро нужно восстановить системы после сбоя.
- Какие технологии лежат в основе DRP. Разберем основные методы защиты: от простого резервного копирования до облачного восстановления (DRaaS) и «горячего» резервирования.
- Из каких шагов состоит разработка плана аварийного восстановления. Мы дадим пошаговый алгоритм, который поможет создать работающий и эффективный DRP для вашей компании.
- Как выбрать надежного партнера для защиты IT-инфраструктуры. Вы узнаете, какие вопросы нужно задать потенциальному подрядчику, чтобы не ошибиться в выборе.
Основные причины сбоев
Неожиданные катастрофы и сбои возникают по множеству причин:
- Техногенные аварии (пожар, проникновение влаги, отключение питания).
- Кибератаки и вирусы-шифровальщики.
- Аппаратные и программные сбои.
- Ошибки сотрудников: случайное удаление данных, некорректные настройки.
Примером может служить случай, когда неправильная организация инфраструктуры привела к потере данных и остановке бизнеса после аварии в серверной.
Что такое Disaster Recovery Plan
Disaster Recovery Plan — это совокупность мер и технологий для быстрого восстановления критически важных ИТ-систем после сбоя. Цель — сохранить работоспособность компании, минимизировав потери данных и простои. DRP — не просто резервное копирование, а элемент корпоративной стратегии управления рисками и информационной безопасностью.
Ключевые параметры: RPO и RTO
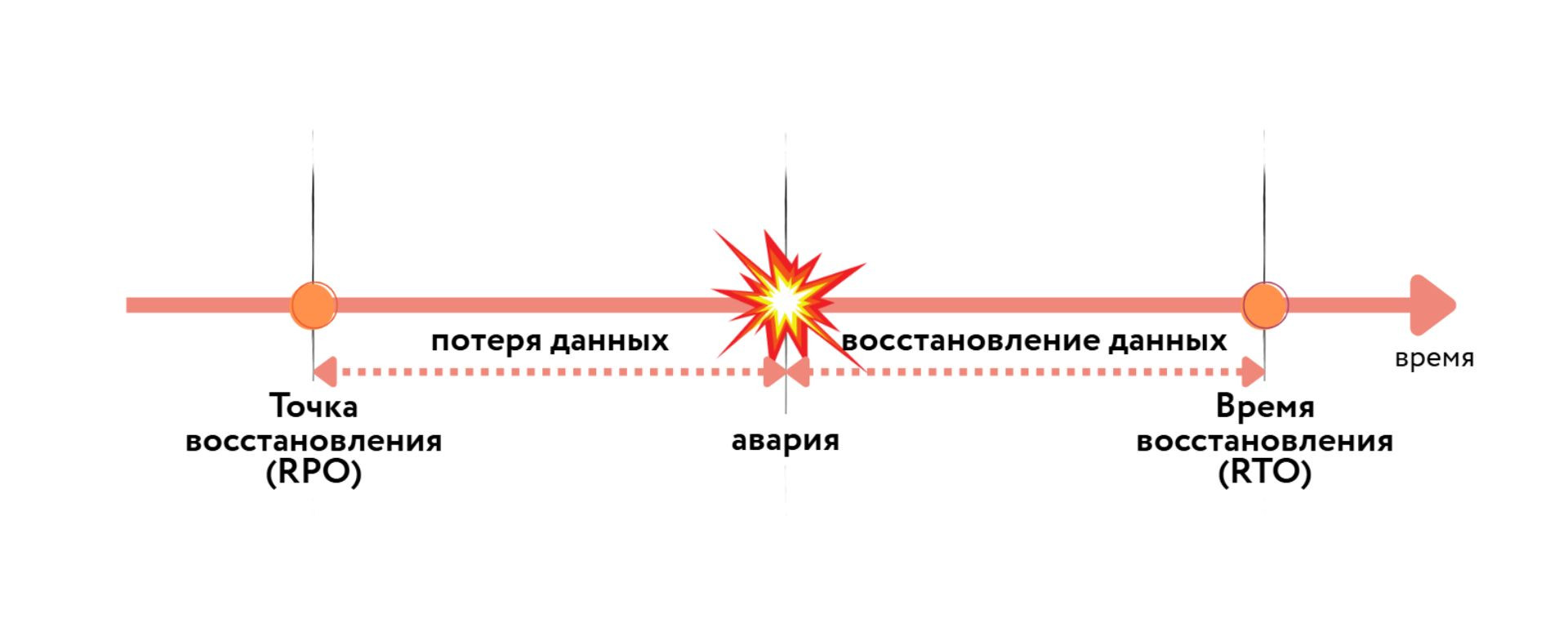
RPO (Recovery Point Objective) показывает, какой объем данных бизнес готов потерять. Например, интернет-магазин с RPO в 15 минут рискует утратить только последние транзакции, а при RPO в 24 часа потеряет целый день продаж.
RTO (Recovery Time Objective) отражает срок восстановления систем после сбоя. Для онлайн-банкинга критичны даже 5–10 минут, а для внутреннего портала, который не влияет на процессы компании, возможен простой до нескольких дней. Чем меньше показатели RTO и RPO, тем выше затраты и технологическая сложность решения.
Оптимальные значения RTO и RPO вырабатываются совместно ИТ и бизнес-командами. Сначала руководство формулирует требования, затем специалисты оценивают их стоимость и риски, после чего утверждается баланс между затратами и уровнем защиты.
Технологии восстановления
Подбор инструментов зависит от бюджета, уровня допустимых потерь и требований к скорости восстановления. Ниже — основные методы, которые составляют основу DRP.
Резервное копирование (Backup)
Регулярные резервные копии — отправная точка любой системы защиты. Важно использовать удалённое копирование: хранение бэкапов только в локальном серверном помещении не поможет при физическом повреждении дата-центра.
Облачное восстановление (DRaaS)
Disaster Recovery as a Service — услуга, при которой инфраструктура реплицируется в облако провайдера. В случае аварии рабочие сервисы автоматически запускаются в облачной среде. Такой подход обеспечивает быстрое восстановление без крупных инвестиций.
Репликация виртуальных машин
Репликация создает копию виртуальной машины на резервном сервере почти в реальном времени. Потери данных сводятся к минимуму, а переключение может происходить автоматически через платформы вроде VMware или Hyper‑V.
«Горячая» резервная площадка
Полноценная дублирующая инфраструктура, готовая к работе в любой момент. Переключение происходит мгновенно, что обеспечивает непрерывность обслуживания, но требует значительных затрат.
| Параметр | Backup | Репликация | DRaaS | Горячий резерв | Время восстановления | Часы или дни | Минуты или час | Минуты | Секунды | Потери данных | До 24 часов | Минуты | Минуты | Почти нулевые | Сложность | Низкая | Средняя | Зависит от провайдера | Высокая |
Как разрабатывается Disaster Recovery Plan
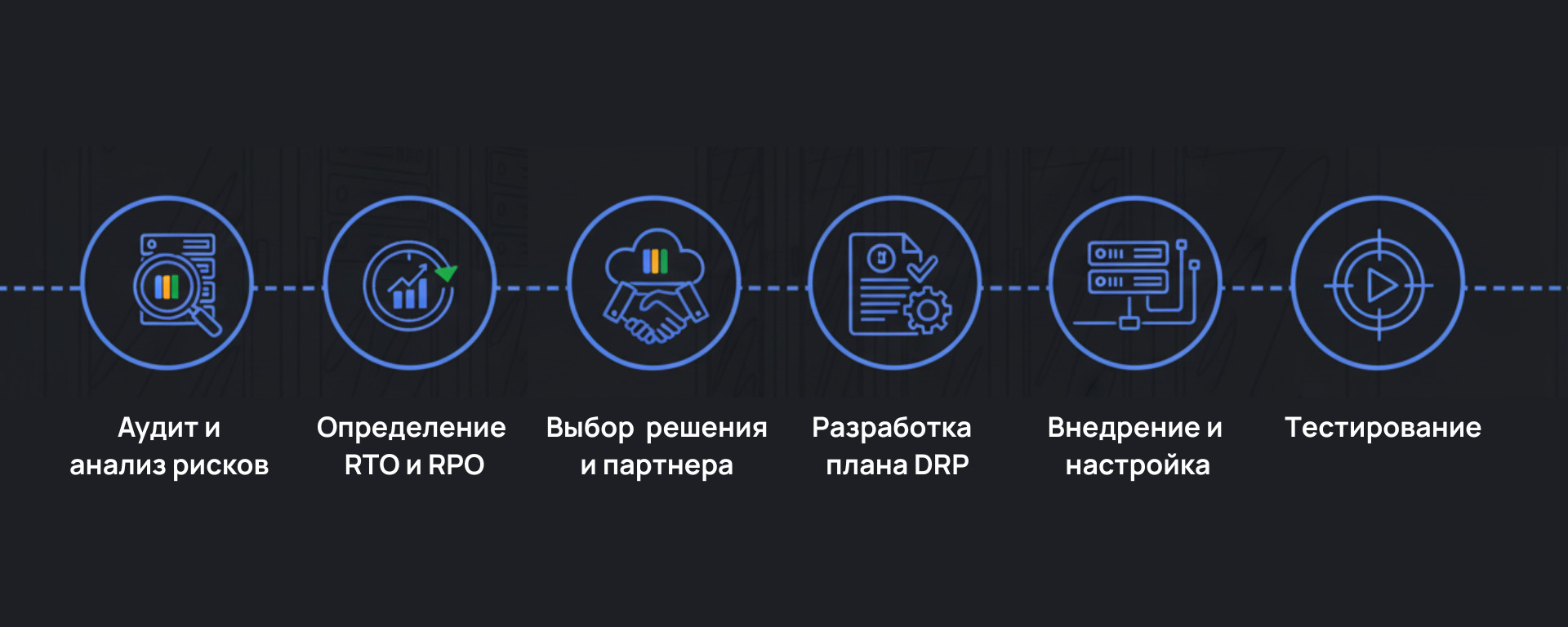
Создание DRP — проект, требующий системного подхода. Вот обязательные шаги его создания:
- Анализ рисков и аудит инфраструктуры.
- Определение RPO и RTO для всех важных систем.
- Выбор технологий и поставщика.
- Создание документа с пошаговыми сценариями восстановления.
- Настройка системы и тестовые запуски.
- Регулярное тестирование и обновление документа.
Cтруктура Плана аварийного восстановления (Disater recovery plan)
Хороший план всегда отвечает на четыре ключевых вопроса:
- Цели. Какие показатели восстановления (RTO, RPO) критичны и какие системы восстанавливаются первыми.
- Ответственные. Кто входит в команду восстановления и как обеспечиваются коммуникации внутри и с клиентами.
- Процедуры. Когда активируется план, в какой последовательности восстанавливаются сервисы, какие инструкции действуют для каждой роли.
- Поддержка актуальности. План нужно тестировать минимум раз в год и обновлять после крупных изменений в инфраструктуре.
Критерии выбора партнера по ИТ-инфраструктуре
Выбирая аутсорсинг-партнера для восстановления инфраструктуры, важно учитывать:
- Подтвержденный опыт и кейсы.
- Собственные или сертифицированные дата‑центры.
- Круглосуточную поддержку и прописанное SLA с гарантиями RTO/RPO, финансовую ответственность за несоблюдение.
- Комплексный подход: аудит, разработка, тестирование и сопровождение DRP.
Частые вопросы
Чем DRP отличается от резервного копирования?
Резервное копирование — часть DRP. Первый сохраняет данные, второй восстанавливает работу систем в целом.
С чего начать, если DRP нет?
Начните с анализа бизнес-рисков (Business Impact Analysis). Определите, какие сервисы критичны, рассчитайте их RPO и RTO — и только после этого выбирайте технологии.
Сколько стоит DRaaS?
Обычно оплата идет по модели «pay‑as‑you‑go»: вы платите только за реально используемые ресурсы. Это дешевле, чем держать резервную площадку самостоятельно.
Как убедить руководство инвестировать в DRP?
Рассмотрите DRP как бизнес-страховку. Сравните стоимость внедрения с убытками от одного дня простоя — аргументы становятся очевидными.
Нужно ли тестировать DRP?
Да, тестирование проводят в изолированной среде, чтобы не влиять на рабочую инфраструктуру. Полный тест — ежегодно, частичный — ежеквартально.
Как получить консультацию
Создание и внедрение DRP требует опыта и системного подхода. Если вы хотите проверить устойчивость ИТ-инфраструктуры и сократить время восстановления, обратитесь в специализированную компанию. Ее сотрудники помогут провести аудит и подобрать оптимальное решение.